mxnet中的MultiBoxPrior、MultiBoxTarget、MultiBoxDetection函数理解
三个函数的参数和输出
mxnet.contrib.ndarray.MultiBoxPrior (生成锚框)
参数:
- data=输入图像样本(批量大小,通道数,高,宽)
- sizes=包含多个锚框大小的数组
- ratios=包含多个锚框的宽高比的数组
输出: 多个锚框
mxnet.contrib.ndarray.MultiBoxTarget (标注锚框类别和偏移量,生成掩码)
参数:
- anchor=锚框(即MultiBoxPrior的输出结果)
- label=真实边界框标签(类别,4个坐标)
- cls_pred=类别预测(shape=(batchsize,预测类别+1,锚框数量))
输出:
- 每个锚框的四个偏移量,其中负类锚框的偏移量为0
- 掩码,形状为(batchsize,锚框个数×4)
- 锚框标注的类别(类别自动增加,其中0为背景)
contrib.ndarray.MultiBoxDetection (预测边界框,非极大抑制)
参数:
- cls_prob=类别预测
- loc_pred=预测的锚框偏移量
- anchor=锚框
- threshold=置信度
输出:
- 锚框类别,置信度,4个坐标。其中类别-1表示背景或在非极大抑制中被移除。
锚框
锚框也叫先验框,以图片中每个像素为中心,生成的多个大小和宽度比不同的边界框。
锚框数量的计算:
设输入图像宽w,高h。然后分别设定一组大小为s1,s2,…,sn和一组高宽比为r1,r2,…,rm。
为了防止计算复杂度过高,通常只对包含s1和r1的大小与高宽比的组合感兴趣,即
(s1,r1),(s1,r2),(s1,sm),…,(s2,r1),(s3,r1),…,(sn,r1).
以相同像素为中心的锚框数量为n+m-1.对于整个图像一共生成wh(n+m-1)个。
代码实现:
from mxnet import contrib, image, nd
import numpy as np
import matplotlib.pyplot as plt
import api
# 读取图像
img = image.imread('D:/mxnet projects/practice/img/cat.1.jpg')
# img = nd.image.resize(img, (300, 300))
img = img.asnumpy()
h, w = img.shape[0:2] # 获取图像宽和高
X = nd.random.uniform(shape=(1, 3, h, w)) # 添加样本维度 3为通道数
Y = contrib.nd.MultiBoxPrior(X, sizes=[0.5, 0.3], ratios=[1, 0.5])
boxes = Y.reshape((h, w, 3, 4)) # 其中3位锚框数量(2+2-1),4为锚框的四个坐标点
bbox_scale = nd.array((h, w, h, w)) #boxes中的坐标值已经除以图像的宽和高,现在恢复大小
# 显示锚框
fig = plt.imshow(img)
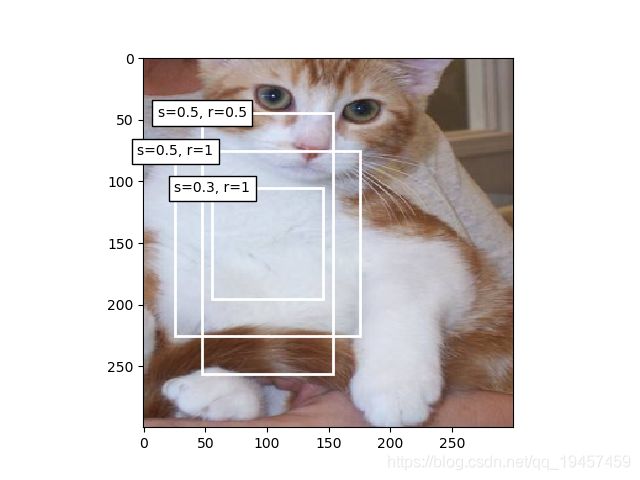
# 显示像素点150,100的锚框
api.show_bbox(fig.axes, boxes[150, 100, :, :]*bbox_scale,
['s=0.5, r=1', 's=0.3, r=1', 's=0.5, r=0.5'])
plt.show()
结果

注意的细节
这里的’s=0.3, r=1’锚框,r=1表示宽高比等于1,应该为正方形,但图片中显示的是长方形。
因为这里的宽高比等于本身图像的宽高比。即r=w:h=320:425
调整图像大小为等宽和等高后,正确的显示为正方形。
交并比
即锚框与真实边界框相交的面积/真实边界框的面积。范围在0和1之间。
标注锚框
from mxnet import contrib, gluon, image, nd
import numpy as np
import matplotlib.pyplot as plt
import api
img = image.imread('D:/mxnet projects/practice/img/catdog.jpg')
img = nd.image.resize(img, (500, 500))
img = img.asnumpy()
h, w = img.shape[0:2]
bbox_scale = nd.array((h, w, h, w))
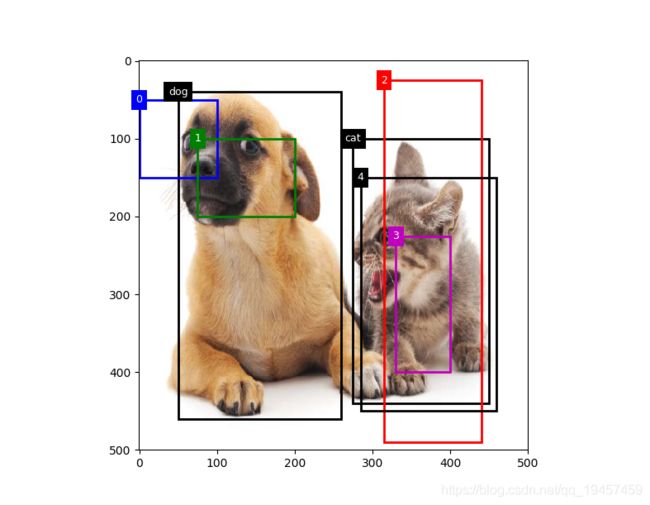
# 真实边界框标签
ground_truth = nd.array([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
# 锚框
anchors = nd.array([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = plt.imshow(img)
api.show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
api.show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])
plt.show()
结果
labels = contrib.nd.MultiBoxTarget(anchors.expand_dims(axis=0),
ground_truth.expand_dims(axis=0),
nd.zeros((1, 3, 4)))
labels[0] : 锚框的偏移量
计算公式
设锚框 A 及其被分配的真实边界框 B 的中心坐标分别为 (xa,ya) 和 (xb,yb) , A 和 B 的宽分别为 wa 和 wb ,高分别为 ha 和 hb ,一个常用的技巧是将 A 的偏移量标注为

其中常数的默认值为 μx=μy=μw=μh=0,σx=σy=0.1,σw=σh=0.2 。如果一个锚框没有被分配真实边界框,我们只需将该锚框的类别设为背景。类别为背景的锚框通常被称为负类锚框,其余则被称为正类锚框。
labels[0]:
[[ 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
1.3999999e+00 9.9999990e+00 2.5939689e+00 7.1754227e+00
-1.1999989e+00 2.6881757e-01 1.6823606e+00 -1.5654588e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
-5.7142794e-01 -1.0000001e+00 -8.9406973e-07 6.2581623e-01]]
<NDArray 1x20 @cpu(0)>
labels[1] : 掩码
labels[1]:
[[0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 1. 1. 1. 1.]]
<NDArray 1x20 @cpu(0)>
labels[2]: 锚框所属的类别
labels[2]:
[[0. 1. 2. 0. 2.]]
<NDArray 1x5 @cpu(0)>
非极大抑制工作原理
对于一个预测边界框 B ,模型会计算各个类别的预测概率。设其中最大的预测概率为 p ,该概率所对应的类别即 B 的预测类别。我们也将 p 称为预测边界框 B 的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表 L 。从 L 中选取置信度最高的预测边界框 B1 作为基准,将所有与 B1 的交并比大于某阈值的非基准预测边界框从 L 中移除。这里的阈值是预先设定的超参数。此时, L 保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。 接下来,从 L 中选取置信度第二高的预测边界框 B2 作为基准,将所有与 B2 的交并比大于某阈值的非基准预测边界框从 L 中移除。重复这一过程,直到 L 中所有的预测边界框都曾作为基准。此时 L 中任意一对预测边界框的交并比都小于阈值。最终,输出列表 L 中的所有预测边界框。
锚框的预测
anchors = nd.array([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = nd.array([0] * anchors.size)
cls_probs = nd.array([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
output = contrib.ndarray.MultiBoxDetection(
cls_probs.expand_dims(axis=0), offset_preds.expand_dims(axis=0),
anchors.expand_dims(axis=0), nms_threshold=0.5)
output:其中第一个元素代表锚框类别,第二个元素代表锚框的置信度,剩余四个元素为偏移量
(0为狗,1为猫,-1表示背景或在非极大抑制中被移除)
output:
[[[ 0. 0.9 0.1 0.08 0.52 0.92]
[ 1. 0.9 0.55 0.2 0.9 0.88]
[-1. 0.8 0.08 0.2 0.56 0.95]
[-1. 0.7 0.15 0.3 0.62 0.91]]]
<NDArray 1x4x6 @cpu(0)>