本文旨在记录阅读《超算竞赛导引》一书中的重点知识和心得体会~ 目前国际上把亚洲ASC、美国SC、德国ISC并称为三大国际超算竞赛,全球Top500,中国HPC Top100和Green 500为高性能计算机排行榜。
第一章:超算的发展与应用
一、 超级计算机简介
超级计算机(以下简称"SC")的作用就不用多说啦,为了反映当前世界上超级计算机的发展水平,自1993年起,每年的6月和11月分别在德国和美国召开的世界超级计算机会议上,发布世界上超级计算机的500强(Top500)排行榜,通过测试执行基准程序LINPACK(线性方程组求解)所需的时间长短来排行。Top500对SC的体系架构的分类是比较简化的,只将SC分为星形、向量、大规模并行处理(massively parallel processing, MMP)系统和集群这几种。目前P级(每秒千万亿次,10^15)的SC已经成熟,E级(百万万亿次,10^18)的SC研制正在激烈的竞争中进行。
二、超算的发展与架构分类
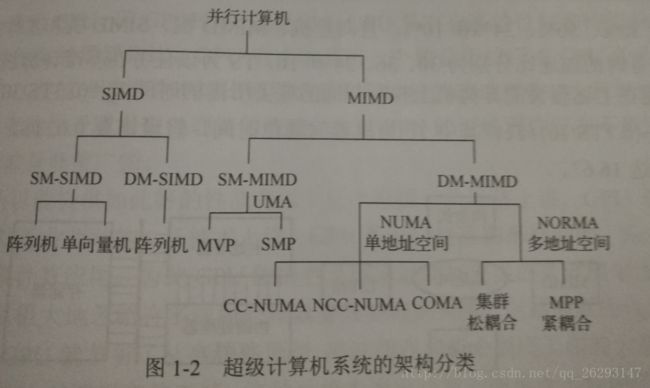
1. 第一代SC是单指令多数据流(SIMD)的阵列处理机,第二代是具有流水结构的向量机,第三代是具有MIMD形式的共享主存多处理机系统,第四代是MPP系统,第五代是集群系统,并逐步由同构方式转为异构方式,主要由CPU+GPU或CPU+MIC(many integrated core ).
2. 可以按并行计算方式是SIMD还是MIMD,以及存储器是共享的还是分布的这两个准则加以分类,一般可分为以下四类:
(1)共享存储-SIMD(SM-SIMD) (2)分布存储-SIMD(DM-SIMD) (3)SM-MIMD (4)DM-MIMD
三、SC的应用现状
1)已归纳出5种并行程序设计算法范例

2)已开发了各种类型的并行编程语言可供用户使用
(1)面向共享存储器的线程编程语言,如POSIX Threads、Java Threads、Open MP等。在标准的顺序语言中调用线程库中的各种例程。
(2)面向分布存储器的消息传递编程语言,如消息传递接口(message passing interface,MPI)、并行虚拟机(PVM)等。在标准的顺序语言中调用各种消息传递的库例程。
(3)开发数据并行的并行编程语言,如HPF(high performance fortran).
(4)面向异构并行架构的编程语言,如NVIDIA的CUDA编程语言。
3)已提出3种基本的并行编程模型供用户使用
(1)共享变量
(2)消息传递
(3)数据并行
第二章:超算集群系统的构建及功耗管理
一、超算集群系统的组成
集群架构目前已经成为最广泛的超级计算机架构,典型的HPC集群系统主要由五类计算(或网络)设备和三类网络组成。
五类设备主要指管理节点及登录节点、计算节点(包括瘦节点(刀片服务器)和胖节点(用于数据划分困难或对内存需求特别大的特殊应用运算等,一般采用四路以上的服务器))、交换设备(大型交换机)、I/O节点和存储设备。另外,当前很多高性能服务器都采用CPU+加速处理器异构的方式,因此有些高效能集群系统还包括加速节点。
第三章:超算系统的网络通信
·一、InfiniBand 技术概要
主流网络互连技术包括以太网、FC和InfiniBand,FC是为实现存储互联而设计的存储专属网络,由于其技术局限性,迄今只在存储互联领域得到广泛应用。以太网与InfiniBand同为开放网络互连技术,以太网更侧重网络协议的通用性,而InfiniBand拥有大幅领先于以太网和FC性能的优势,同时是具备软件定义网络(soft defined network,SDN)属性的智能网络。
InfiniBand架构介绍如下:
1) HCA
主机通道适配器(host channel adapter,HCA)是InfiniBand网络的最终节点,可以安装在服务器或存储中,实现服务器、存储与InfiniBand网络的连接。
2)TCA
目标通道适配器(TCA)主要为内嵌系统定义的适配器架构,不用提供面向应用程序的标准应用程序接口(API),迄今应用只局限于很小的领域。
3)网络交换机
实现网络通信的交换
4)路由器
实现InfiniBand多子网直接互连。
5)网线与连接模块
高性能、低延迟、高效率、可靠稳定的网络互连、低功耗、数据完整性、开放性。
二、InfiniBand技术核心---RDMA
RDMA与TCP/IP类似属于网络传输协议,然而传统的TCP/IP技术在处理数据传输的过程中需要占用大量的服务器资源而使得TCP传输效率低下。RDMA操作使应用可以从一个远程应用的内存中读数据或向这个内存中写数据。远程节点的CPU在整个RDMA操作中并不提供服务,因此没有带来任何负载,使得CPU资源能专注于应用处理。
RDMA的技术核心:
1)零拷贝技术
网卡(HCA)可以直接与应用内存相互传输数据,从而避免了在应用程序内存与内核内存之间的数据拷贝过程。
2)内核旁路技术
内核旁路(kernel bypass)技术,当执行RDMA读/写请求时,应用程序不需要执行内核调用就可向网卡发送命令,从而减少了在处理网络传输时内核空间与用户空间之间环境切换的次数。
3)协议装载
网卡硬件中部署可靠的传输协议,从而消除通信对CPU资源的依赖。 InfiniBand与其他网络技术最大的区别就是其为应用层提供直接RDMA消息传输服务,无论是用户应用程序还是内核应用。而传统网络当应用层需要访问网络服务时,必须要通过操作系统的支持才能完成。
三、基于InfiniBand的HPC应用优化
基于MPI规范的实现软件包括MPICH与OpenMPI.MPICH由美国阿贡国家实验室和密西西比州立大学联合开发,具有很好的可移植性。MVAPICH2、Intel MPI、Platform MPI都是基于MPICH开发的。OpenMPi由多家高校、研究机构、公司共同维护的开源MPI实现。
第四章:超算系统的应用环境
简单概括为CPU并行系统应用环境、CPU+MIC异构并行系统应用环境以及CPU+GPU异构并行系统应用环境,其中每一类都包含硬件环境(多核服务器、InfiniBand网线等)、软件环境(操作系统(windows/Linux)、并行运行环境(MPICH/节点内用OpenMP或PThread))、开发环境(编译器和调试器(gcc/gdb,Intel conpiler XE等)、高性能数学函数库(MKL,GotoBlas,OpenBLAS等)、高性能调优工具(intel VTune/NVIDIA Nsight))。
第五章:超算系统性能评测方法
当前最常用的性能度量是“每秒浮点运算次数”(floating operations per second).
对一台给定的高性能计算机系统,其理论的峰值性能是固定的,为CPU主频×CPU单核每个时钟周期能执行的浮点操作数×系统总CPU核数
高性能计算机的性能测评通常可分为以下四大类:
1)单项测评
通常又称为微基准测试,对计算机特定部件或单项性能进行测试,常见的包括内存带宽测试、网络性能测试、I/O性能测试等。
2)整体计算性能测评
常见的测试包括HPL(high performance LINPACK)、HPCC(high performance computing challenge)、SPEC HPC(standard performance evaluation corporation high performance computing)等。目前国际和国内的SC排行榜都是基于整体计算性能测评结果进行排序的。
3)领域应用性能测评
4)典型应用性能测评
主要测试程序及应用
1.内存性能测试程序Stream
2.通信性能测试程序OMB
3.浮点计算性能测试程序HPL
HPL是通过求解一个稠密线性方程组Ax=b所花费的时间来评价计算机的浮点计算性能。为保证测评结果的公正性,HPL不允许修改基本算法(采用LU分解的高斯消去法),机必须保证总浮点计算次数不变。对N*N的矩阵A,求解Ax=b的总浮点计算次数即计算量为(2/3×N^3-2×N^2)。因此,只要给顶问题规模N,测的系统计算时间T,则HPL将测定该系统浮点性能值为:计算量/计算时间T,单位为flops.
常用的HPL优化策略如下:
(1)选择尽可能大的N,在系统内存耗尽之前,N越大,HPL性能越高
(2)HPL的核心计算是矩阵乘(耗时通常在90%以上),其采用分块算法实现,其中分块的大小对计算性能影响巨大,需综合系统CPU缓存大小等因素,通过小规模问题的实例,选择最佳的分块矩阵值。
(3)LU分解参数、MPI、不同BLAS数学库的性能、编译选项核操作系统等其他众多因素同样对测试结果有影响。
4.综合性能测试程序HPCC
`HPCC由若干知名的测试程序组成,其选择的七个测试程序如下:
(1)HPL,获得浮点计算性能值,时空局部性均良好
(2)DGEMM,双精度实数矩阵乘,获得浮点计算性能值,时空局部性均良好
(3)Stream,获得系统内存持续带宽值,空间局部性好,时间局部性差
(4)PTRANS,并行矩阵转秩,体现系统通信性能,空间局部性好,时间局部性差
(5)RandomAccess,测试内存随机更新速率,时空局部性均不好
(6)FFT,计算双精度一维复数离散傅里叶变换,获得浮点计算性能值,空间局部性差,时间局部性好
(7)b_eff,测定系统通信带宽和延迟
HPCC虽然提供了丰富的测试结果,但并未在高性能计算界获得广泛的支持和认可,其中测试过程和结果过于复杂、无法给定易于比较的单一指标是两个重要因素。
5.领域测试程序集Graph 500 Benchmark
其所计算的问题是在一个庞大的无向图种采用宽度优先算法进行搜索。
后面章节省略(主要讲三大高性能竞赛历史以及ASC赛题分析)