创新实训记录13--算法结果展示/报错解决
目录
- 界面展示
- 1.context里面传输的需要是列表,否则会导致跳转界面的不显示:
- 2.使输出一行一个:
- 3.进度卡在0,不进行,也不报错问题:
- 4.报错&解决:(禁止跨域是浏览器的安全限制机制)
- 5.报错&解决:
- 6.报错&解决:
- 7.报错&解决:
- 8.预测结果效果:
- 9.词云效果添加;
界面展示
django界面 pyechart bootstrap
1.context里面传输的需要是列表,否则会导致跳转界面的不显示:
先前传的是一个字符串导致一直前端遍历的时候获取不到相关内容!

2.使输出一行一个:
原始:

现在:

function loadXMLDoc1() {
var node=document.getElementById("contents");
for(var i=0;i<res1.length;i++) {
var p=document.createElement("p");
var tmp=document.createTextNode(res1[i]);
p.appendChild(tmp);
node.appendChild(p) ;
}
}
3.进度卡在0,不进行,也不报错问题:

原因:
传入的论文id集合里面应该是int类型的,而原先是string类型的:
#论文集合(由此篇论文及其inlink,outlink组成)
list_paper=[]
with open('choose_paper/data/articles.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
artical = lines[num]
list_paper.append(int(artical.strip()))
with open('choose_paper/data/inlinks.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
inlink = lines[num].split()
for i in range(len(inlink)):
list_paper.append(int(inlink[i]) )
with open('choose_paper/data/outlinks.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
outlink = lines[num].split()
for i in range(len(outlink)):
list_paper.append(int(outlink[i]))
4.报错&解决:(禁止跨域是浏览器的安全限制机制)
Access to XMLHttpRequest at 'file:///F:/%E4%BB%A3%E7%A0%81/Jquery/a.txt' from origin 'null' has been blocked by CORS policy: Cross origin requests are only supported for protocol schemes: http, data, chrome, chrome-extension, https.
解决办法:
https://www.cnblogs.com/jing-tian/p/10820839.html
5.报错&解决:
Uncaught ReferenceError: loadXMLDoc0 is not defined at HTMLButtonElement.onclick ((index):35)
解决:
html:
<input type="button" value="立即登录" onclick="dosave();"/>
js:
dosave = function (){
alert("成功啦!");
}
参考:
https://blog.csdn.net/qq_39019865/article/details/79867091?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
6.报错&解决:
Uncaught SyntaxError: Unexpected identifier
解决:
https://blog.csdn.net/challenge_me/article/details/87856998
7.报错&解决:
输出的结果总是带有上一行的结果:(找了很久!)
愿因在于result+=“(” 应该为result=“(”:
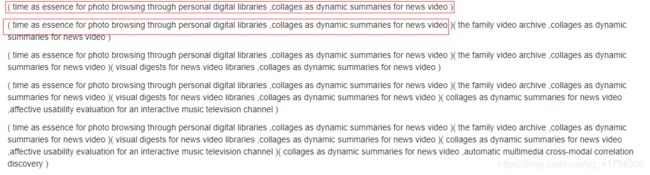
而且因为获取的页面原来存在文字,导致切换的不准备的显示:(会带有上一按钮的内容)

修改:(添加此话)

for tmp in finalresult:
result_0="( "
for j in range(2):
with open("choose_paper/PaperCompare/ACM_dataset/nodes.txt",'r',encoding='utf-8') as f:
lines=f.readlines()
for i in range(len(lines)):
line=lines[i].split()
if(str(tmp[j])==str(line[0])):
for m in range(1,len(line)):
result_0+=line[m]
result_0+=" "
if(j==0):
result_0+=","
result_0+=")"
result0.append(result_0)
8.预测结果效果:


9.词云效果添加;

代码:
##词云--------------------------------------
# 年份列表
file_years = 'choose_paper/data/years.txt'
years = []
with open(file_years,'r',encoding="utf-8") as f:
for line in f.readlines():
year_ = line.strip()
years.append(year_)
# 会议列表
file_venues = 'choose_paper/data/venues.txt'
venues = []
with open(file_venues,'r',encoding="utf-8") as f:
for line in f.readlines():
venue_ = line.strip()
venues.append(venue_)
# 关键词列表
key_path = 'choose_paper/data/keywords.txt'
word_list =[]
with open(key_path,'r',encoding="utf-8") as f:
for line in f.readlines():
word = line.strip().split()
word_list.append(word)
# 定义根据年份会议获取数据
word_dict = {} #某年某个关键词出现的次数统计
use_data = [] #可视化时传入的data
yea = str(year) #将输入的年份转为str
venu = str(venue)
for i in range(len(years)):
if yea == years[i].strip() and venu == venues[i].strip():
sword = word_list[i]
for word in sword:
if word in word_dict.keys() and word is not '':
word_dict[word]+=1
elif word is not '':
temp = { }
temp[word]=1
word_dict.update(temp)
else:
continue
# 对word_dict进行处理,筛选词语
length = len(word_dict)
if length>60:
for k,v in word_dict.items():
if v>1:
tup = (k,v)
use_data.append(tup)
else:
for k,v in word_dict.items():
tup = (k,v)
use_data.append(tup)
##词云展示:
wtitle = str(year)+' '+venue+':关键词词云展示'
mywordcloud = WordCloud()
mywordcloud.add('',use_data,shape='triangle')\
.set_global_opts(title_opts=opts.TitleOpts(
title=wtitle))
mywordcloud.render(path="choose_paper/data/graph/wordCloud.txt") # 显示图表
mywordcloud_txt = "{"
with open('choose_paper/data/graph/wordCloud.txt', 'r', encoding='utf-8') as f:
line = f.readlines()
for i in range(16, len(line)-4):
mywordcloud_txt += line[i]