Hadoop 3.x 入门 - 记录躺过的坑
一、 伪分布式节点启动报错
./start-dfs.sh
Starting namenodes on [10.1.4.57]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [10.1.4.57]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.环境变量 hadoop-env.sh 中指定用户名:
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root再次启动ok。***_USER设置错误,会报
cannot set priority of datanode process 32156二、 namenode节点启动成功,web服务无法访问
检查linux系统的防火墙设置
firewall-cmd --stateCentOS-7 防火墙默认使用的是firewall,与之前的版本使用iptables不一样。防火墙操作命令:
关闭防火墙:systemctl stop firewalld.service
开启防火墙:systemctl start firewalld.service
关闭开机启动:systemctl disable firewalld.service
开启开机启动:systemctl enable firewalld.service关闭防火墙并设置禁用开机启动后,成功访问 http://ip:9870/
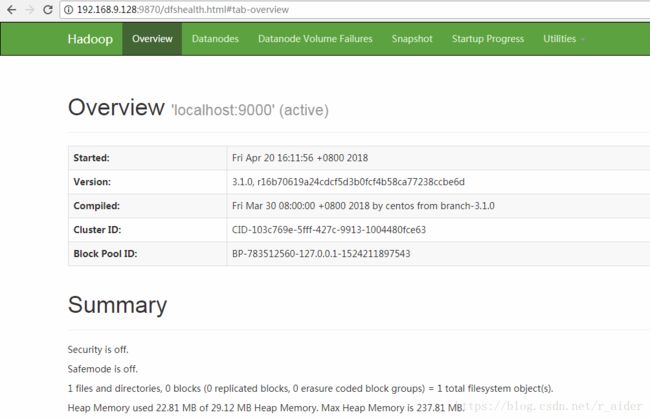
三、 datanode启动出错
2018-04-23 10:33:29,644 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /tmp/hadoop-root/dfs/data/in_use.lock acquired by nodename 3692@localhost
2018-04-23 10:33:29,647 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/tmp/hadoop-root/dfs/data
java.io.IOException: Incompatible clusterIDs in /tmp/hadoop-root/dfs/data: namenode clusterID = CID-103c769e-5fff-427c-9913-1004480fce63; datanode clusterID = CID-659951c9-642c-4325-8dc3-79f5edbdf175
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:736)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:294)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:407)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:387)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:551)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1705)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1665)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:390)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:280)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:816)
at java.lang.Thread.run(Thread.java:748)原因是bin/hdfs namenode -format只会格式化namenode,并不会影响到datanode,如果再次格式化会导致datanode和namenode的clusterID不一致。解决方法:先停掉hadoop,把slaves的dfs/data的内容删除,再次启动后,会创建新的clusterID,也可以复制master的clusterID到slaves中。
sbin/stop-all.sh
rm -Rf /tmp/hadoop-your-username/*
bin/hadoop namenode -formatsbin/start-dfs.sh四 、 单节点配置YARN启动报错
官方配置说明:

进行上述配置后,执行start-yarn.sh启动报错:

"[26,2]"、“start tag in epilog”描述的应该是标签错误,合并
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
再次启动,成功访问http://{IP}:8088 -->
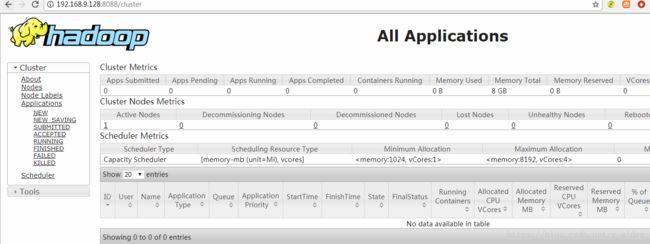
5、 伪分布式yarn下执行mapreduce任务报错
[root@skynet hadoop-3.1.0]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar grep /input output 'dfs[a-z.]+'
2018-04-26 09:51:51,788 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2018-04-26 09:51:53,411 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1524705632872_0003
2018-04-26 09:51:53,850 INFO input.FileInputFormat: Total input files to process : 9
2018-04-26 09:51:54,939 INFO mapreduce.JobSubmitter: number of splits:9
2018-04-26 09:51:55,082 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2018-04-26 09:51:55,777 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1524705632872_0003
2018-04-26 09:51:55,782 INFO mapreduce.JobSubmitter: Executing with tokens: []
2018-04-26 09:51:56,322 INFO conf.Configuration: resource-types.xml not found
2018-04-26 09:51:56,322 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-04-26 09:51:56,624 INFO impl.YarnClientImpl: Submitted application application_1524705632872_0003
2018-04-26 09:51:56,753 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1524705632872_0003/
2018-04-26 09:51:56,754 INFO mapreduce.Job: Running job: job_1524705632872_0003
2018-04-26 09:52:11,181 INFO mapreduce.Job: Job job_1524705632872_0003 running in uber mode : false
2018-04-26 09:52:11,239 INFO mapreduce.Job: map 0% reduce 0%
2018-04-26 09:53:04,709 INFO mapreduce.Job: Task Id : attempt_1524705632872_0003_m_000002_0, Status : FAILED
[2018-04-26 09:52:26.109]Container [pid=5916,containerID=container_1524705632872_0003_01_000004] is running 217049600B beyond the 'VIRTUAL' memory limit. Current usage: 21.6 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1524705632872_0003_01_000004 :6、 伪分布式yarn下执行mapreduce任务报错
2018-04-26 10:53:47,979 INFO conf.Configuration: resource-types.xml not found
2018-04-26 10:53:47,979 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-04-26 10:53:49,887 INFO impl.YarnClientImpl: Submitted application application_1524711155618_0001
2018-04-26 10:53:50,089 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1524711155618_0001/
2018-04-26 10:53:50,108 INFO mapreduce.Job: Running job: job_1524711155618_0001
2018-04-26 10:54:22,606 INFO mapreduce.Job: Job job_1524711155618_0001 running in uber mode : false
2018-04-26 10:54:22,830 INFO mapreduce.Job: map 0% reduce 0%
2018-04-26 11:04:05,398 INFO mapreduce.Job: map 7% reduce 0%
2018-04-26 11:04:21,311 INFO mapreduce.Job: map 11% reduce 0%
2018-04-26 11:04:39,021 INFO mapreduce.Job: map 22% reduce 0%
2018-04-26 11:05:28,803 INFO mapreduce.Job: map 41% reduce 0%
2018-04-26 11:05:30,174 INFO mapreduce.Job: map 59% reduce 0%
2018-04-26 11:05:31,604 INFO mapreduce.Job: map 63% reduce 0%
2018-04-26 11:05:36,465 INFO mapreduce.Job: map 67% reduce 0%
2018-04-26 11:14:53,509 INFO mapreduce.Job: map 78% reduce 0%
2018-04-26 11:15:03,711 INFO mapreduce.Job: map 100% reduce 0%
2018-04-26 11:15:38,986 INFO mapreduce.Job: Task Id : attempt_1524711155618_0001_r_000000_0, Status : FAILED
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#5
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:377)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1682)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.io.IOException: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.checkReducerHealth(ShuffleSchedulerImpl.java:396)
at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.copyFailed(ShuffleSchedulerImpl.java:311)
at org.apache.hadoop.mapreduce.task.reduce.Fetcher.openShuffleUrl(Fetcher.java:291)
at org.apache.hadoop.mapreduce.task.reduce.Fetcher.copyFromHost(Fetcher.java:330)
at org.apache.hadoop.mapreduce.task.reduce.Fetcher.run(Fetcher.java:198)7、 qidongbaocuo
[root@skynet hadoop-3.1.0]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar grep /input output 'dfs[a-z.]+'
2018-04-27 09:46:13,774 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2018-04-27 09:46:15,595 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:16,598 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:17,602 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:18,604 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:19,607 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:20,610 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:21,612 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:22,616 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:23,621 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 8 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-04-27 09:46:24,624 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)