激活函数(Activation Functions)概述
Activation Function
在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function。神经网络中使用激活函数来加入非线性因素,提高模型的表达能力。
Activation Function性质
- 可微性:计算梯度时必须要有此性质。
- 非线性:保证数据非线性可分。
- 单调性:保证凸函数。
- 输出值与输入值相差不会很大:保证神经网络训练和调参高效。
常用Activation Function:
- sigmoid
- tanh
- ReLU
- Leaky ReLU
- ELU
- Maxout
- softmax
sigmoid函数
函数式:
f ( z ) = 1 1 + e x p ( − z ) f(z) = \frac{1}{1+exp(-z)} f(z)=1+exp(−z)1
图像:

优点
- 取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。
缺点
- sigmoid 函数不是关于原点中心对称的,由于Sigmoid输出是在0-1之间,总是正数,以f=sigmoid(wx+b)为例, 假设输入均为正数(或负数),那么对w的导数总是正数(或负数),这样在反向传播过程中要么都往正方向更新,要么都往负方向更新,使得收敛缓慢。,这样更新的时候容易出现zigzag现象,不容易到达最优值。
- 指数运算相对耗时。
- 激活函数计算量大,反向传播求误差梯度时,求导涉及除法反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
原因:
反向传播算法中,要对激活函数求导,sigmoid 的导数表达式为:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x) = f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
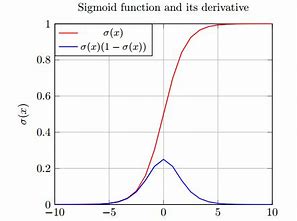
导数图像:
Tanh函数
函数式
f ( z ) = s i n h ( z ) c o s h ( z ) = e z − e − z e z + e − z f(z) =\frac{sinh(z)}{cosh(z)} = \frac{e^z - e^{-z}}{e^z + e^{-z}} f(z)=cosh(z)sinh(z)=ez+e−zez−e−z
图像

优点
- Tanh函数是0均值的更加有利于提高训练效率。
- Tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。
缺点
- 指数运算相对耗时。
- 梯度消失。(原因同上sigmoid函数,导数图像可以加以说明。)
Rectified Linear Unit(ReLU)
函数式
R ( z ) = m a x ( 0 , z ) R(z) = max(0, z) R(z)=max(0,z)
图像

优点
- 不存在梯度趋于0的饱和区域。
- 实际应用中converge(融合)远比sigmoid/tanh快。
- ReLU 对于 SGD 的收敛有巨大的加速作用(Alex Krizhevsky 指出有 6 倍之多)
- 生物上的合理性,它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。(大多数时间,生物神经元是非激活的)
缺点
- 不是以0为中心,x<0时没有梯度,反向传播不会更新,会dead。
举例来说:一个非常大的梯度经过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0 。
也就是说,这个 ReLU 单元在训练中将不可逆转的死亡,导致了数据多样化的丢失。实际中,如果学习率设置得太高,可能会发现网络中 40% 的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。
合理设置学习率,会降低这种情况的发生概率。
Leaky ReLU
函数式
当x<0时,f(x)=αx,其中α非常小,这样可以避免在x<0时,不能够学习的情况:
f ( x ) = m a x ( α x , x ) f(x)=max(αx,x) f(x)=max(αx,x)
称为Parametric Rectifier(PReLU),将 α 作为可学习的参数。
-
当 α 从高斯分布中随机产生时称为Random Rectifier(RReLU)。
-
当固定为α=0.01时,是Leaky ReLU。
图像

优点
- relu的所有优点。
- 解决了x<0时没有梯度,反向传播不会更新,会dead的情况。
Exponential Linear Unit指数线性单元
函数式
f ( x ) = { α ( e x − 1 ) , x ≤ 0 x , x > 0 f(x) = \begin{cases} \alpha (e^x - 1), \quad x \le 0 \\ x, \quad x \gt 0 \end{cases} f(x)={α(ex−1),x≤0x,x>0
导数式:
f ′ ( x ) = { f ( x ) + α , x ≤ 0 1 , x > 0 f'(x) = \begin{cases} f(x) + \alpha , \quad x \le 0 \\ 1, \quad x \gt 0 \end{cases} f′(x)={f(x)+α,x≤01,x>0
ReLU家族对比
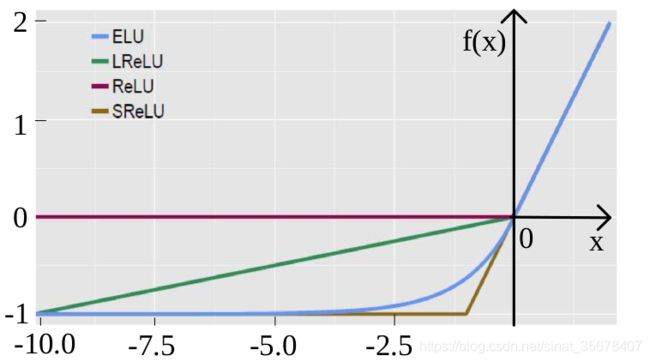
优点
- 有较高的噪声鲁棒性,同时能够使得使得神经元的平均激活均值趋近为 0,同时对噪声更具有鲁棒性。
- ReLU的所有优点。
缺点
- 计算指数,计算量较大。
Maxout
函数式
Maxout可以看做是在深度学习网络中加入一层激活函数层,包含一个参数k。这一层相比ReLU,sigmoid等,其特殊之处在于增加了k个神经元,然后输出激活值最大的值。我们常见的隐含层节点输出:
h i ( x ) = s i g m o i d ( W i x i + b i ) h_i(x) = sigmoid(W_ix_i + b_i) hi(x)=sigmoid(Wixi+bi)
而在Maxout网络中,其隐含层节点的输出表达式为:
h i ( x ) = m a x j ∈ { 1 , 2 , . . . , k } ( W i j x + b i j ) h_i(x) = max_{j \in \{1, 2, ..., k\}}(W_{ij}x + b_{ij}) hi(x)=maxj∈{1,2,...,k}(Wijx+bij)
图像

优点
- Maxout的拟合能力非常强,可以拟合任意的凸函数。
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
缺点
- 整体参数的数量大。
Softmax函数
函数式
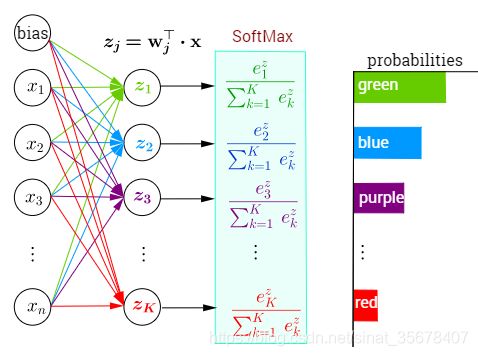
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类。
S i = e V i ∑ j C e V j S_i = \frac{e^{V_i}}{\sum_{j}^{C}e^{V_j}} Si=∑jCeVjeVi
其中, V i V_i Vi是分类器前级输出单元的输出。i 表示类别索引,总的类别个数为 C。 S i S_i Si 表示的是当前元素的指数与所有元素指数和的比值。Softmax 将多分类的输出数值转化为相对概率,更容易理解和比较。
可以看出,所有 S i S_i Si的和为1,即:
∑ i C S i = 1 \sum_{i}^{C}S_i = 1 i∑CSi=1
图像
优点
- softmax建模使用的分布是多项式分布,回归进行的多分类,类与类之间是互斥的,即一个输入只能被归为一类;
缺点
- 不适合用于回归进行多分类,输出的类别并不是互斥的情况。(这种情况下,一般使用多个logistic回归进行分类)
softmax求导过程
常见激活函数总结
- sigmoid: 计算量大,激活函数计算量大,反向传播求误差梯度时,求导涉及除法
反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。 - Tanh: tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。
与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。 - ReLU:收敛速度快,但是存在dead情况,此时可以考虑使用Leaky ReLU等ReLU家族函数。
- Maxout: 拟合性强,以上的激活函数优点几乎都具有,但是参数很多,训练不易。
- Softmax: 主要用于多分类,且各类别互斥的情况。
选择上,结合具体的优缺点选择,注意各激活函数的特点!!!
参考资料
- cs231n课程
- 机器学习课程——吴恩达
- https://www.jianshu.com/p/22d9720dbf1a
- https://www.jianshu.com/p/ffa51250ba2e
- https://zhuanlan.zhihu.com/p/37211635