一文读懂Kubernetes Scheduler扩展功能
前言
Scheduler是Kubernetes组件中功能&逻辑相对单一&简单的模块,它主要的作用是:watch kube-apiserver,监听PodSpec.NodeName为空的pod,并利用预选和优选算法为该pod选择一个最佳的调度节点,最终将pod与该节点进行绑定,使pod调度在该节点上运行
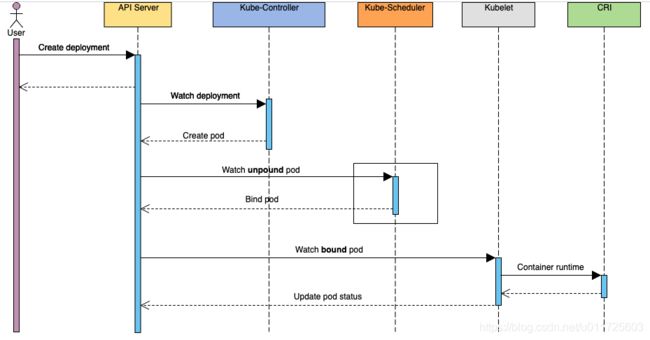
展开上述调用流程中的scheduler部分,内部细节调用(参考Kubernetes Scheduler)如图所示:
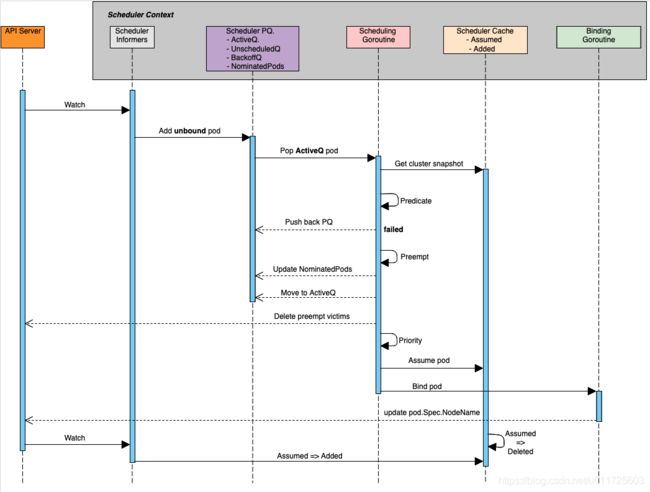
scheduler内部预置了很多预选和优选算法(参考scheduler_algorithm),比如预选:NoDiskConflict,PodFitsResources,MatchNodeSelector,CheckNodeMemoryPressure等;优选:LeastRequestedPriority,BalancedResourceAllocation,CalculateAntiAffinityPriority,NodeAffinityPriority等。但是在实际生产环境中我们常常会需要一些特殊的调度策略,比如批量调度(aka coscheduling or gang scheduling),这是kubernetes默认调度策略所无法满足的,这个时候就需要我们对scheduler进行扩展来实现这个功能了
scheduler扩展方案
目前Kubernetes支持四种方式实现客户自定义的调度算法(预选&优选),如下:
- default-scheduler recoding: 直接在Kubernetes默认scheduler基础上进行添加,然后重新编译kube-scheduler
- standalone: 实现一个与kube-scheduler平行的custom scheduler,单独或者和默认kube-scheduler一起运行在集群中
- scheduler extender: 实现一个"scheduler extender",kube-scheduler会调用它(http/https)作为默认调度算法(预选&优选&bind)的补充
- scheduler framework: 实现scheduler framework plugins,重新编译kube-scheduler,类似于第一种方案,但是更加标准化,插件化
下面分别展开介绍这几种方式的原理和开发指引
default-scheduler recoding
这里我们先分析一下kube-scheduler调度相关入口:
- 设置默认预选&优选策略
见defaultPredicates以及defaultPriorities(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go):
func init() {
registerAlgorithmProvider(defaultPredicates(), defaultPriorities())
}
func defaultPredicates() sets.String {
return sets.NewString(
predicates.NoVolumeZoneConflictPred,
predicates.MaxEBSVolumeCountPred,
predicates.MaxGCEPDVolumeCountPred,
predicates.MaxAzureDiskVolumeCountPred,
predicates.MaxCSIVolumeCountPred,
predicates.MatchInterPodAffinityPred,
predicates.NoDiskConflictPred,
predicates.GeneralPred,
predicates.PodToleratesNodeTaintsPred,
predicates.CheckVolumeBindingPred,
predicates.CheckNodeUnschedulablePred,
)
}
func defaultPriorities() sets.String {
return sets.NewString(
priorities.SelectorSpreadPriority,
priorities.InterPodAffinityPriority,
priorities.LeastRequestedPriority,
priorities.BalancedResourceAllocation,
priorities.NodePreferAvoidPodsPriority,
priorities.NodeAffinityPriority,
priorities.TaintTolerationPriority,
priorities.ImageLocalityPriority,
)
}
func registerAlgorithmProvider(predSet, priSet sets.String) {
// Registers algorithm providers. By default we use 'DefaultProvider', but user can specify one to be used
// by specifying flag.
scheduler.RegisterAlgorithmProvider(scheduler.DefaultProvider, predSet, priSet)
// Cluster autoscaler friendly scheduling algorithm.
scheduler.RegisterAlgorithmProvider(ClusterAutoscalerProvider, predSet,
copyAndReplace(priSet, priorities.LeastRequestedPriority, priorities.MostRequestedPriority))
}
const (
// DefaultProvider defines the default algorithm provider name.
DefaultProvider = "DefaultProvider"
)
- 注册预选和优选相关处理函数
注册预选函数(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/register_predicates.go):
func init() {
...
// Fit is determined by resource availability.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
scheduler.RegisterFitPredicate(predicates.PodFitsResourcesPred, predicates.PodFitsResources)
}
注册优选函数(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/register_priorities.go):
func init() {
...
// Prioritizes nodes that have labels matching NodeAffinity
scheduler.RegisterPriorityMapReduceFunction(priorities.NodeAffinityPriority, priorities.CalculateNodeAffinityPriorityMap, priorities.CalculateNodeAffinityPriorityReduce, 1)
}
- 编写预选和优选处理函数
PodFitsResourcesPred对应的预选函数如下(k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go):
// PodFitsResources checks if a node has sufficient resources, such as cpu, memory, gpu, opaque int resources etc to run a pod.
// First return value indicates whether a node has sufficient resources to run a pod while the second return value indicates the
// predicate failure reasons if the node has insufficient resources to run the pod.
func PodFitsResources(pod *v1.Pod, meta Metadata, nodeInfo *schedulernodeinfo.NodeInfo) (bool, []PredicateFailureReason, error) {
node := nodeInfo.Node()
if node == nil {
return false, nil, fmt.Errorf("node not found")
}
var predicateFails []PredicateFailureReason
allowedPodNumber := nodeInfo.AllowedPodNumber()
if len(nodeInfo.Pods())+1 > allowedPodNumber {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourcePods, 1, int64(len(nodeInfo.Pods())), int64(allowedPodNumber)))
}
// No extended resources should be ignored by default.
ignoredExtendedResources := sets.NewString()
var podRequest *schedulernodeinfo.Resource
if predicateMeta, ok := meta.(*predicateMetadata); ok && predicateMeta.podFitsResourcesMetadata != nil {
podRequest = predicateMeta.podFitsResourcesMetadata.podRequest
if predicateMeta.podFitsResourcesMetadata.ignoredExtendedResources != nil {
ignoredExtendedResources = predicateMeta.podFitsResourcesMetadata.ignoredExtendedResources
}
} else {
// We couldn't parse metadata - fallback to computing it.
podRequest = GetResourceRequest(pod)
}
if podRequest.MilliCPU == 0 &&
podRequest.Memory == 0 &&
podRequest.EphemeralStorage == 0 &&
len(podRequest.ScalarResources) == 0 {
return len(predicateFails) == 0, predicateFails, nil
}
allocatable := nodeInfo.AllocatableResource()
if allocatable.MilliCPU < podRequest.MilliCPU+nodeInfo.RequestedResource().MilliCPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceCPU, podRequest.MilliCPU, nodeInfo.RequestedResource().MilliCPU, allocatable.MilliCPU))
}
if allocatable.Memory < podRequest.Memory+nodeInfo.RequestedResource().Memory {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceMemory, podRequest.Memory, nodeInfo.RequestedResource().Memory, allocatable.Memory))
}
if allocatable.EphemeralStorage < podRequest.EphemeralStorage+nodeInfo.RequestedResource().EphemeralStorage {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceEphemeralStorage, podRequest.EphemeralStorage, nodeInfo.RequestedResource().EphemeralStorage, allocatable.EphemeralStorage))
}
for rName, rQuant := range podRequest.ScalarResources {
if v1helper.IsExtendedResourceName(rName) {
// If this resource is one of the extended resources that should be
// ignored, we will skip checking it.
if ignoredExtendedResources.Has(string(rName)) {
continue
}
}
if allocatable.ScalarResources[rName] < rQuant+nodeInfo.RequestedResource().ScalarResources[rName] {
predicateFails = append(predicateFails, NewInsufficientResourceError(rName, podRequest.ScalarResources[rName], nodeInfo.RequestedResource().ScalarResources[rName], allocatable.ScalarResources[rName]))
}
}
if klog.V(10) {
if len(predicateFails) == 0 {
// We explicitly don't do klog.V(10).Infof() to avoid computing all the parameters if this is
// not logged. There is visible performance gain from it.
klog.Infof("Schedule Pod %+v on Node %+v is allowed, Node is running only %v out of %v Pods.",
podName(pod), node.Name, len(nodeInfo.Pods()), allowedPodNumber)
}
}
return len(predicateFails) == 0, predicateFails, nil
}
优选NodeAffinityPriority对应的Map与Reduce函数(k8s.io/kubernetes/pkg/scheduler/algorithm/priorities/node_affinity.go)如下:
// CalculateNodeAffinityPriorityMap prioritizes nodes according to node affinity scheduling preferences
// indicated in PreferredDuringSchedulingIgnoredDuringExecution. Each time a node matches a preferredSchedulingTerm,
// it will get an add of preferredSchedulingTerm.Weight. Thus, the more preferredSchedulingTerms
// the node satisfies and the more the preferredSchedulingTerm that is satisfied weights, the higher
// score the node gets.
func CalculateNodeAffinityPriorityMap(pod *v1.Pod, meta interface{}, nodeInfo *schedulernodeinfo.NodeInfo) (framework.NodeScore, error) {
node := nodeInfo.Node()
if node == nil {
return framework.NodeScore{}, fmt.Errorf("node not found")
}
// default is the podspec.
affinity := pod.Spec.Affinity
if priorityMeta, ok := meta.(*priorityMetadata); ok {
// We were able to parse metadata, use affinity from there.
affinity = priorityMeta.affinity
}
var count int32
// A nil element of PreferredDuringSchedulingIgnoredDuringExecution matches no objects.
// An element of PreferredDuringSchedulingIgnoredDuringExecution that refers to an
// empty PreferredSchedulingTerm matches all objects.
if affinity != nil && affinity.NodeAffinity != nil && affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution != nil {
// Match PreferredDuringSchedulingIgnoredDuringExecution term by term.
for i := range affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution {
preferredSchedulingTerm := &affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution[i]
if preferredSchedulingTerm.Weight == 0 {
continue
}
// TODO: Avoid computing it for all nodes if this becomes a performance problem.
nodeSelector, err := v1helper.NodeSelectorRequirementsAsSelector(preferredSchedulingTerm.Preference.MatchExpressions)
if err != nil {
return framework.NodeScore{}, err
}
if nodeSelector.Matches(labels.Set(node.Labels)) {
count += preferredSchedulingTerm.Weight
}
}
}
return framework.NodeScore{
Name: node.Name,
Score: int64(count),
}, nil
}
// CalculateNodeAffinityPriorityReduce is a reduce function for node affinity priority calculation.
var CalculateNodeAffinityPriorityReduce = NormalizeReduce(framework.MaxNodeScore, false)
- 相关使用
接下来我们看一下kube-scheduler调度算法(预选&优选)是如何与上述这些操作结合起来的:
// Fit is determined by resource availability.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
scheduler.RegisterFitPredicate(predicates.PodFitsResourcesPred, predicates.PodFitsResources)
...
// RegisterFitPredicate registers a fit predicate with the algorithm
// registry. Returns the name with which the predicate was registered.
func RegisterFitPredicate(name string, predicate predicates.FitPredicate) string {
return RegisterFitPredicateFactory(name, func(AlgorithmFactoryArgs) predicates.FitPredicate { return predicate })
}
...
// RegisterFitPredicateFactory registers a fit predicate factory with the
// algorithm registry. Returns the name with which the predicate was registered.
func RegisterFitPredicateFactory(name string, predicateFactory FitPredicateFactory) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
fitPredicateMap[name] = predicateFactory
return name
}
...
// Prioritizes nodes that have labels matching NodeAffinity
scheduler.RegisterPriorityMapReduceFunction(priorities.NodeAffinityPriority, priorities.CalculateNodeAffinityPriorityMap, priorities.CalculateNodeAffinityPriorityReduce, 1)
...
// RegisterPriorityMapReduceFunction registers a priority function with the algorithm registry. Returns the name,
// with which the function was registered.
func RegisterPriorityMapReduceFunction(
name string,
mapFunction priorities.PriorityMapFunction,
reduceFunction priorities.PriorityReduceFunction,
weight int) string {
return RegisterPriorityConfigFactory(name, PriorityConfigFactory{
MapReduceFunction: func(AlgorithmFactoryArgs) (priorities.PriorityMapFunction, priorities.PriorityReduceFunction) {
return mapFunction, reduceFunction
},
Weight: int64(weight),
})
}
...
// RegisterPriorityConfigFactory registers a priority config factory with its name.
func RegisterPriorityConfigFactory(name string, pcf PriorityConfigFactory) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
priorityFunctionMap[name] = pcf
return name
}
...
// (g.predicates)
// podFitsOnNode checks whether a node given by NodeInfo satisfies the given predicate functions.
// For given pod, podFitsOnNode will check if any equivalent pod exists and try to reuse its cached
// predicate results as possible.
// This function is called from two different places: Schedule and Preempt.
// When it is called from Schedule, we want to test whether the pod is schedulable
// on the node with all the existing pods on the node plus higher and equal priority
// pods nominated to run on the node.
// When it is called from Preempt, we should remove the victims of preemption and
// add the nominated pods. Removal of the victims is done by SelectVictimsOnNode().
// It removes victims from meta and NodeInfo before calling this function.
func (g *genericScheduler) podFitsOnNode(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
meta predicates.Metadata,
info *schedulernodeinfo.NodeInfo,
alwaysCheckAllPredicates bool,
) (bool, []predicates.PredicateFailureReason, *framework.Status, error) {
var failedPredicates []predicates.PredicateFailureReason
var status *framework.Status
podsAdded := false
// We run predicates twice in some cases. If the node has greater or equal priority
// nominated pods, we run them when those pods are added to meta and nodeInfo.
// If all predicates succeed in this pass, we run them again when these
// nominated pods are not added. This second pass is necessary because some
// predicates such as inter-pod affinity may not pass without the nominated pods.
// If there are no nominated pods for the node or if the first run of the
// predicates fail, we don't run the second pass.
// We consider only equal or higher priority pods in the first pass, because
// those are the current "pod" must yield to them and not take a space opened
// for running them. It is ok if the current "pod" take resources freed for
// lower priority pods.
// Requiring that the new pod is schedulable in both circumstances ensures that
// we are making a conservative decision: predicates like resources and inter-pod
// anti-affinity are more likely to fail when the nominated pods are treated
// as running, while predicates like pod affinity are more likely to fail when
// the nominated pods are treated as not running. We can't just assume the
// nominated pods are running because they are not running right now and in fact,
// they may end up getting scheduled to a different node.
for i := 0; i < 2; i++ {
...
for _, predicateKey := range predicates.Ordering() {
...
if predicate, exist := g.predicates[predicateKey]; exist {
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
if err != nil {
return false, []predicates.PredicateFailureReason{}, nil, err
}
...
}
}
}
return len(failedPredicates) == 0 && status.IsSuccess(), failedPredicates, status, nil
}
...
// (g.prioritizers)
// prioritizeNodes prioritizes the nodes by running the individual priority functions in parallel.
// Each priority function is expected to set a score of 0-10
// 0 is the lowest priority score (least preferred node) and 10 is the highest
// Each priority function can also have its own weight
// The node scores returned by the priority function are multiplied by the weights to get weighted scores
// All scores are finally combined (added) to get the total weighted scores of all nodes
func (g *genericScheduler) prioritizeNodes(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
meta interface{},
nodes []*v1.Node,
) (framework.NodeScoreList, error) {
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
nodeInfo := g.nodeInfoSnapshot.NodeInfoMap[nodes[index].Name]
for i := range g.prioritizers {
var err error
results[i][index], err = g.prioritizers[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Name = nodes[index].Name
}
}
})
for i := range g.prioritizers {
if g.prioritizers[i].Reduce == nil {
continue
}
wg.Add(1)
go func(index int) {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_mapreduce").Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_mapreduce").Dec()
wg.Done()
}()
if err := g.prioritizers[index].Reduce(pod, meta, g.nodeInfoSnapshot, results[index]); err != nil {
appendError(err)
}
if klog.V(10) {
for _, hostPriority := range results[index] {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), hostPriority.Name, g.prioritizers[index].Name, hostPriority.Score)
}
}
}(i)
}
// Wait for all computations to be finished.
wg.Wait()
...
}
综上,如果要在kube-scheduler基础上添加策略,则按照如下步骤进行添加:
- 设置默认预选&优选策略:defaultPredicates以及defaultPriorities(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go)
- 注册预选和优选相关处理函数:注册预选函数(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/register_predicates.go);注册优选函数(k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/register_priorities.go)
- 编写预选和优选处理函数:编写预选函数(k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go);编写优选函数Map+Reduce(k8s.io/kubernetes/pkg/scheduler/algorithm/priorities/xxx.go)
- 除了默认设置预选&优选外,还可以手动通过命令行
--policy-config-file指定调度策略(会覆盖默认策略),例如examples/scheduler-policy-config.json
standalone
相比recoding只修改简单代码,standalone在kube-scheduler基础上进行重度二次定制,这种方式优缺点如下:
- Pros
- 满足对scheduler最大程度的重构&定制
- Cons
- 实际工程中如果只是想添加预选或者优选策略,则会切换到第一种方案,不会单独开发和部署一个scheduler
- 二次定制scheduler开发难度较大(至少对scheduler代码非常熟悉),且对Kubernetes集群影响较大(无论是单独部署,还是并列部署),后续升级和维护成本较高
- 可能会产生调度冲突问题,在同时部署两个scheduler时,可能会出现一个scheduler bind的时候实际资源已经被另一个scheduler分配了
因此建议在其它方案满足不了扩展需求时,才采用standalone方案,且生产环境仅部署一个scheduler
scheduler extender
对于Kubernetes项目来说,它很乐意开发者使用并向它提bug或者PR(受欢迎),但是不建议开发者为了实现业务需求直接修改Kubernetes核心代码,因为这样做会影响Kubernetes本身的代码质量以及稳定性。因此Kubernetes希望尽可能通过外围的方式来解决客户自定义的需求
其实任何好的项目都应该这样思考:尽可能抽取核心代码,这部分代码不应该经常变动或者说只能由maintainer改动(提高代码质量,减小项目本身开发&运维成本);将第三方客户需求尽可能提取到外围解决(满足客户自由),例如:插件的形式(eg: CNI,CRI,CSI and scheduler framework etc)
上面介绍的default-scheduler recoding以及standalone方案都属于侵入式的方案,不太优雅;而scheduler extender以及scheduler framework属于非侵入式的方案,这里重点介绍scheduler extender
scheduler extender类似于webhook,kube-scheduler会在默认调度算法执行完成后以http/https的方式调用extender,extender server完成自定义的预选&优选逻辑,并返回规定字段给scheduler,scheduler结合这些信息进行最终的调度裁决,从而完成基于extender实现扩展的逻辑
scheduler extender适用于调度策略与非标准kube-scheduler管理资源相关的场景,当然你也可以使用extender完成与上述两种方式同样的功能
下面我们结合代码说明extender的使用原理:
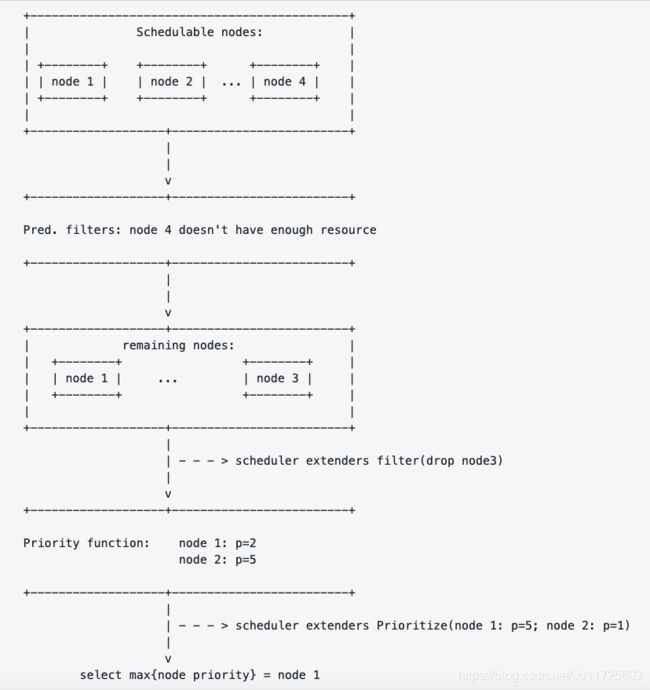
- 定义scheduler extender
在使用extender之前,我们必须在scheduler policy配置文件中定义extender相关信息,如下:
// k8s.io/kubernetes/pkg/scheduler/apis/config/legacy_types.go
// Extender holds the parameters used to communicate with the extender. If a verb is unspecified/empty,
// it is assumed that the extender chose not to provide that extension.
type Extender struct {
// URLPrefix at which the extender is available
URLPrefix string
// Verb for the filter call, empty if not supported. This verb is appended to the URLPrefix when issuing the filter call to extender.
FilterVerb string
// Verb for the preempt call, empty if not supported. This verb is appended to the URLPrefix when issuing the preempt call to extender.
PreemptVerb string
// Verb for the prioritize call, empty if not supported. This verb is appended to the URLPrefix when issuing the prioritize call to extender.
PrioritizeVerb string
// The numeric multiplier for the node scores that the prioritize call generates.
// The weight should be a positive integer
Weight int64
// Verb for the bind call, empty if not supported. This verb is appended to the URLPrefix when issuing the bind call to extender.
// If this method is implemented by the extender, it is the extender's responsibility to bind the pod to apiserver. Only one extender
// can implement this function.
BindVerb string
// EnableHTTPS specifies whether https should be used to communicate with the extender
EnableHTTPS bool
// TLSConfig specifies the transport layer security config
TLSConfig *ExtenderTLSConfig
// HTTPTimeout specifies the timeout duration for a call to the extender. Filter timeout fails the scheduling of the pod. Prioritize
// timeout is ignored, k8s/other extenders priorities are used to select the node.
HTTPTimeout time.Duration
// NodeCacheCapable specifies that the extender is capable of caching node information,
// so the scheduler should only send minimal information about the eligible nodes
// assuming that the extender already cached full details of all nodes in the cluster
NodeCacheCapable bool
// ManagedResources is a list of extended resources that are managed by
// this extender.
// - A pod will be sent to the extender on the Filter, Prioritize and Bind
// (if the extender is the binder) phases iff the pod requests at least
// one of the extended resources in this list. If empty or unspecified,
// all pods will be sent to this extender.
// - If IgnoredByScheduler is set to true for a resource, kube-scheduler
// will skip checking the resource in predicates.
// +optional
ManagedResources []ExtenderManagedResource
// Ignorable specifies if the extender is ignorable, i.e. scheduling should not
// fail when the extender returns an error or is not reachable.
Ignorable bool
}
这里面主要关注如下几个字段:
- URLPrefix:extender访问地址
- FilterVerb:extender预选接口,scheduler在默认预选策略完成后会调用该接口完成自定义预选算法
- PrioritizeVerb:extender优选接口,scheduler在默认优选策略完成后会调用该接口完成自定义优选算法
- Weight:表示extender优选算法对应的权重
policy配置示例如下:
{
"predicates": [
{
"name": "HostName"
},
{
"name": "MatchNodeSelector"
},
{
"name": "PodFitsResources"
}
],
"priorities": [
{
"name": "LeastRequestedPriority",
"weight": 1
}
],
"extenders": [
{
"urlPrefix": "http://127.0.0.1:12345/api/scheduler",
"filterVerb": "filter",
"enableHttps": false
}
]
}
- extender预选接口
传递给extender预选接口的参数结构如下(k8s.io/kubernetes/pkg/scheduler/apis/extender/v1/types.go):
// ExtenderArgs represents the arguments needed by the extender to filter/prioritize
// nodes for a pod.
type ExtenderArgs struct {
// Pod being scheduled
Pod *v1.Pod
// List of candidate nodes where the pod can be scheduled; to be populated
// only if ExtenderConfig.NodeCacheCapable == false
Nodes *v1.NodeList
// List of candidate node names where the pod can be scheduled; to be
// populated only if ExtenderConfig.NodeCacheCapable == true
NodeNames *[]string
}
其中,Nodes结构体表示scheduler默认预选策略通过的节点列表,我们看相关调用代码(k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go):
// CreateFromConfig creates a scheduler from the configuration file
func (c *Configurator) CreateFromConfig(policy schedulerapi.Policy) (*Scheduler, error) {
klog.V(2).Infof("Creating scheduler from configuration: %v", policy)
...
var extenders []algorithm.SchedulerExtender
if len(policy.Extenders) != 0 {
ignoredExtendedResources := sets.NewString()
var ignorableExtenders []algorithm.SchedulerExtender
for ii := range policy.Extenders {
klog.V(2).Infof("Creating extender with config %+v", policy.Extenders[ii])
extender, err := core.NewHTTPExtender(&policy.Extenders[ii])
if err != nil {
return nil, err
}
if !extender.IsIgnorable() {
extenders = append(extenders, extender)
} else {
ignorableExtenders = append(ignorableExtenders, extender)
}
for _, r := range policy.Extenders[ii].ManagedResources {
if r.IgnoredByScheduler {
ignoredExtendedResources.Insert(string(r.Name))
}
}
}
// place ignorable extenders to the tail of extenders
extenders = append(extenders, ignorableExtenders...)
predicates.RegisterPredicateMetadataProducerWithExtendedResourceOptions(ignoredExtendedResources)
}
...
return c.CreateFromKeys(predicateKeys, priorityKeys, extenders)
}
...
// Filters the nodes to find the ones that fit based on the given predicate functions
// Each node is passed through the predicate functions to determine if it is a fit
func (g *genericScheduler) findNodesThatFit(ctx context.Context, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, FailedPredicateMap, framework.NodeToStatusMap, error) {
var filtered []*v1.Node
failedPredicateMap := FailedPredicateMap{}
filteredNodesStatuses := framework.NodeToStatusMap{}
if len(g.predicates) == 0 && !g.framework.HasFilterPlugins() {
filtered = g.nodeInfoSnapshot.ListNodes()
} else {
allNodes := len(g.nodeInfoSnapshot.NodeInfoList)
numNodesToFind := g.numFeasibleNodesToFind(int32(allNodes))
// Create filtered list with enough space to avoid growing it
// and allow assigning.
filtered = make([]*v1.Node, numNodesToFind)
errCh := util.NewErrorChannel()
var (
predicateResultLock sync.Mutex
filteredLen int32
)
ctx, cancel := context.WithCancel(ctx)
// We can use the same metadata producer for all nodes.
meta := g.predicateMetaProducer(pod, g.nodeInfoSnapshot)
state.Write(migration.PredicatesStateKey, &migration.PredicatesStateData{Reference: meta})
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
nodeInfo := g.nodeInfoSnapshot.NodeInfoList[(g.nextStartNodeIndex+i)%allNodes]
fits, failedPredicates, status, err := g.podFitsOnNode(
ctx,
state,
pod,
meta,
nodeInfo,
g.alwaysCheckAllPredicates,
)
if err != nil {
errCh.SendErrorWithCancel(err, cancel)
return
}
if fits {
length := atomic.AddInt32(&filteredLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&filteredLen, -1)
} else {
filtered[length-1] = nodeInfo.Node()
}
} else {
predicateResultLock.Lock()
if !status.IsSuccess() {
filteredNodesStatuses[nodeInfo.Node().Name] = status
}
if len(failedPredicates) != 0 {
failedPredicateMap[nodeInfo.Node().Name] = failedPredicates
}
predicateResultLock.Unlock()
}
}
// Stops searching for more nodes once the configured number of feasible nodes
// are found.
workqueue.ParallelizeUntil(ctx, 16, allNodes, checkNode)
processedNodes := int(filteredLen) + len(filteredNodesStatuses) + len(failedPredicateMap)
g.nextStartNodeIndex = (g.nextStartNodeIndex + processedNodes) % allNodes
filtered = filtered[:filteredLen]
if err := errCh.ReceiveError(); err != nil {
return []*v1.Node{}, FailedPredicateMap{}, framework.NodeToStatusMap{}, err
}
}
if len(filtered) > 0 && len(g.extenders) != 0 {
for _, extender := range g.extenders {
if !extender.IsInterested(pod) {
continue
}
filteredList, failedMap, err := extender.Filter(pod, filtered, g.nodeInfoSnapshot.NodeInfoMap)
if err != nil {
if extender.IsIgnorable() {
klog.Warningf("Skipping extender %v as it returned error %v and has ignorable flag set",
extender, err)
continue
}
return []*v1.Node{}, FailedPredicateMap{}, framework.NodeToStatusMap{}, err
}
for failedNodeName, failedMsg := range failedMap {
if _, found := failedPredicateMap[failedNodeName]; !found {
failedPredicateMap[failedNodeName] = []predicates.PredicateFailureReason{}
}
failedPredicateMap[failedNodeName] = append(failedPredicateMap[failedNodeName], predicates.NewFailureReason(failedMsg))
}
filtered = filteredList
if len(filtered) == 0 {
break
}
}
}
return filtered, failedPredicateMap, filteredNodesStatuses, nil
}
...
// SchedulerExtender is an interface for external processes to influence scheduling
// decisions made by Kubernetes. This is typically needed for resources not directly
// managed by Kubernetes.
type SchedulerExtender interface {
// Name returns a unique name that identifies the extender.
Name() string
// Filter based on extender-implemented predicate functions. The filtered list is
// expected to be a subset of the supplied list. failedNodesMap optionally contains
// the list of failed nodes and failure reasons.
Filter(pod *v1.Pod,
nodes []*v1.Node, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo,
) (filteredNodes []*v1.Node, failedNodesMap extenderv1.FailedNodesMap, err error)
// Prioritize based on extender-implemented priority functions. The returned scores & weight
// are used to compute the weighted score for an extender. The weighted scores are added to
// the scores computed by Kubernetes scheduler. The total scores are used to do the host selection.
Prioritize(pod *v1.Pod, nodes []*v1.Node) (hostPriorities *extenderv1.HostPriorityList, weight int64, err error)
// Bind delegates the action of binding a pod to a node to the extender.
Bind(binding *v1.Binding) error
// IsBinder returns whether this extender is configured for the Bind method.
IsBinder() bool
// IsInterested returns true if at least one extended resource requested by
// this pod is managed by this extender.
IsInterested(pod *v1.Pod) bool
// ProcessPreemption returns nodes with their victim pods processed by extender based on
// given:
// 1. Pod to schedule
// 2. Candidate nodes and victim pods (nodeToVictims) generated by previous scheduling process.
// 3. nodeNameToInfo to restore v1.Node from node name if extender cache is enabled.
// The possible changes made by extender may include:
// 1. Subset of given candidate nodes after preemption phase of extender.
// 2. A different set of victim pod for every given candidate node after preemption phase of extender.
ProcessPreemption(
pod *v1.Pod,
nodeToVictims map[*v1.Node]*extenderv1.Victims,
nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo,
) (map[*v1.Node]*extenderv1.Victims, error)
// SupportsPreemption returns if the scheduler extender support preemption or not.
SupportsPreemption() bool
// IsIgnorable returns true indicates scheduling should not fail when this extender
// is unavailable. This gives scheduler ability to fail fast and tolerate non-critical extenders as well.
IsIgnorable() bool
}
...
// k8s.io/kubernetes/pkg/scheduler/core/extender.go
// Filter based on extender implemented predicate functions. The filtered list is
// expected to be a subset of the supplied list; otherwise the function returns an error.
// failedNodesMap optionally contains the list of failed nodes and failure reasons.
func (h *HTTPExtender) Filter(
pod *v1.Pod,
nodes []*v1.Node, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo,
) ([]*v1.Node, extenderv1.FailedNodesMap, error) {
var (
result extenderv1.ExtenderFilterResult
nodeList *v1.NodeList
nodeNames *[]string
nodeResult []*v1.Node
args *extenderv1.ExtenderArgs
)
if h.filterVerb == "" {
return nodes, extenderv1.FailedNodesMap{}, nil
}
if h.nodeCacheCapable {
nodeNameSlice := make([]string, 0, len(nodes))
for _, node := range nodes {
nodeNameSlice = append(nodeNameSlice, node.Name)
}
nodeNames = &nodeNameSlice
} else {
nodeList = &v1.NodeList{}
for _, node := range nodes {
nodeList.Items = append(nodeList.Items, *node)
}
}
args = &extenderv1.ExtenderArgs{
Pod: pod,
Nodes: nodeList,
NodeNames: nodeNames,
}
if err := h.send(h.filterVerb, args, &result); err != nil {
return nil, nil, err
}
if result.Error != "" {
return nil, nil, fmt.Errorf(result.Error)
}
if h.nodeCacheCapable && result.NodeNames != nil {
nodeResult = make([]*v1.Node, len(*result.NodeNames))
for i, nodeName := range *result.NodeNames {
if node, ok := nodeNameToInfo[nodeName]; ok {
nodeResult[i] = node.Node()
} else {
return nil, nil, fmt.Errorf(
"extender %q claims a filtered node %q which is not found in nodeNameToInfo map",
h.extenderURL, nodeName)
}
}
} else if result.Nodes != nil {
nodeResult = make([]*v1.Node, len(result.Nodes.Items))
for i := range result.Nodes.Items {
nodeResult[i] = &result.Nodes.Items[i]
}
}
return nodeResult, result.FailedNodes, nil
}
...
// Helper function to send messages to the extender
func (h *HTTPExtender) send(action string, args interface{}, result interface{}) error {
out, err := json.Marshal(args)
if err != nil {
return err
}
url := strings.TrimRight(h.extenderURL, "/") + "/" + action
req, err := http.NewRequest("POST", url, bytes.NewReader(out))
if err != nil {
return err
}
req.Header.Set("Content-Type", "application/json")
resp, err := h.client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return fmt.Errorf("Failed %v with extender at URL %v, code %v", action, url, resp.StatusCode)
}
return json.NewDecoder(resp.Body).Decode(result)
}
scheduler会在默认预选算法执行完成后,遍历extender列表,依次发出http/https POST请求给extender,请求参数为extenderv1.ExtenderArgs,extender执行完预选算法后,返回extenderv1.ExtenderFilterResult(k8s.io/kubernetes/pkg/scheduler/apis/extender/v1/types.go),如下:
// ExtenderFilterResult represents the results of a filter call to an extender
type ExtenderFilterResult struct {
// Filtered set of nodes where the pod can be scheduled; to be populated
// only if ExtenderConfig.NodeCacheCapable == false
Nodes *v1.NodeList
// Filtered set of nodes where the pod can be scheduled; to be populated
// only if ExtenderConfig.NodeCacheCapable == true
NodeNames *[]string
// Filtered out nodes where the pod can't be scheduled and the failure messages
FailedNodes FailedNodesMap
// Error message indicating failure
Error string
}
并将上一次过滤后的node列表传递给下一个extender进行过滤
- extender优选接口
传递给extender优选接口的参数结构和预选相同(k8s.io/kubernetes/pkg/scheduler/apis/extender/v1/types.go):
// ExtenderArgs represents the arguments needed by the extender to filter/prioritize
// nodes for a pod.
type ExtenderArgs struct {
// Pod being scheduled
Pod *v1.Pod
// List of candidate nodes where the pod can be scheduled; to be populated
// only if ExtenderConfig.NodeCacheCapable == false
Nodes *v1.NodeList
// List of candidate node names where the pod can be scheduled; to be
// populated only if ExtenderConfig.NodeCacheCapable == true
NodeNames *[]string
}
其中,Nodes结构体表示scheduler预选策略(默认+extender算法)通过的节点列表,我们看相关调用代码(k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go):
// prioritizeNodes prioritizes the nodes by running the individual priority functions in parallel.
// Each priority function is expected to set a score of 0-10
// 0 is the lowest priority score (least preferred node) and 10 is the highest
// Each priority function can also have its own weight
// The node scores returned by the priority function are multiplied by the weights to get weighted scores
// All scores are finally combined (added) to get the total weighted scores of all nodes
func (g *genericScheduler) prioritizeNodes(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
meta interface{},
nodes []*v1.Node,
) (framework.NodeScoreList, error) {
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(g.prioritizers) == 0 && len(g.extenders) == 0 && !g.framework.HasScorePlugins() {
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{
Name: nodes[i].Name,
Score: 1,
})
}
return result, nil
}
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
appendError := func(err error) {
mu.Lock()
defer mu.Unlock()
errs = append(errs, err)
}
results := make([]framework.NodeScoreList, len(g.prioritizers))
for i := range g.prioritizers {
results[i] = make(framework.NodeScoreList, len(nodes))
}
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
nodeInfo := g.nodeInfoSnapshot.NodeInfoMap[nodes[index].Name]
for i := range g.prioritizers {
var err error
results[i][index], err = g.prioritizers[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Name = nodes[index].Name
}
}
})
for i := range g.prioritizers {
if g.prioritizers[i].Reduce == nil {
continue
}
wg.Add(1)
go func(index int) {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_mapreduce").Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_mapreduce").Dec()
wg.Done()
}()
if err := g.prioritizers[index].Reduce(pod, meta, g.nodeInfoSnapshot, results[index]); err != nil {
appendError(err)
}
if klog.V(10) {
for _, hostPriority := range results[index] {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), hostPriority.Name, g.prioritizers[index].Name, hostPriority.Score)
}
}
}(i)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return framework.NodeScoreList{}, errors.NewAggregate(errs)
}
// Run the Score plugins.
state.Write(migration.PrioritiesStateKey, &migration.PrioritiesStateData{Reference: meta})
scoresMap, scoreStatus := g.framework.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return framework.NodeScoreList{}, scoreStatus.AsError()
}
// Summarize all scores.
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range g.prioritizers {
result[i].Score += results[j][i].Score * g.prioritizers[j].Weight
}
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
if len(g.extenders) != 0 && nodes != nil {
combinedScores := make(map[string]int64, len(g.nodeInfoSnapshot.NodeInfoList))
for i := range g.extenders {
if !g.extenders[i].IsInterested(pod) {
continue
}
wg.Add(1)
go func(extIndex int) {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_extender").Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues("prioritizing_extender").Dec()
wg.Done()
}()
prioritizedList, weight, err := g.extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
if klog.V(10) {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), host, g.extenders[extIndex].Name(), score)
}
combinedScores[host] += score * weight
}
mu.Unlock()
}(i)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
}
}
if klog.V(10) {
for i := range result {
klog.Infof("Host %s => Score %d", result[i].Name, result[i].Score)
}
}
return result, nil
}
...
// Prioritize based on extender implemented priority functions. Weight*priority is added
// up for each such priority function. The returned score is added to the score computed
// by Kubernetes scheduler. The total score is used to do the host selection.
func (h *HTTPExtender) Prioritize(pod *v1.Pod, nodes []*v1.Node) (*extenderv1.HostPriorityList, int64, error) {
var (
result extenderv1.HostPriorityList
nodeList *v1.NodeList
nodeNames *[]string
args *extenderv1.ExtenderArgs
)
if h.prioritizeVerb == "" {
result := extenderv1.HostPriorityList{}
for _, node := range nodes {
result = append(result, extenderv1.HostPriority{Host: node.Name, Score: 0})
}
return &result, 0, nil
}
if h.nodeCacheCapable {
nodeNameSlice := make([]string, 0, len(nodes))
for _, node := range nodes {
nodeNameSlice = append(nodeNameSlice, node.Name)
}
nodeNames = &nodeNameSlice
} else {
nodeList = &v1.NodeList{}
for _, node := range nodes {
nodeList.Items = append(nodeList.Items, *node)
}
}
args = &extenderv1.ExtenderArgs{
Pod: pod,
Nodes: nodeList,
NodeNames: nodeNames,
}
if err := h.send(h.prioritizeVerb, args, &result); err != nil {
return nil, 0, err
}
return &result, h.weight, nil
}
scheduler会在默认优选算法执行完成后,并发(wg.Wait)执行extender优选算法(预选需要顺序执行,优选可以并发执行),请求参数为extenderv1.ExtenderArgs(和预选一样),返回extenderv1.HostPriorityList(k8s.io/kubernetes/pkg/scheduler/apis/extender/v1/types.go),如下:
// HostPriority represents the priority of scheduling to a particular host, higher priority is better.
type HostPriority struct {
// Name of the host
Host string
// Score associated with the host
Score int64
}
// HostPriorityList declares a []HostPriority type.
type HostPriorityList []HostPriority
这里返回了每个节点对应的extender优选算法分数,注意extender的优选算法实际上只是完成了Map过程(返回0-10分数),所以需要scheduler对extender优选scores进行Reduce(替换成0-100分数),如下:
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
...
const (
// MaxNodeScore is the maximum score a Score plugin is expected to return.
MaxNodeScore int64 = 100
// MinNodeScore is the minimum score a Score plugin is expected to return.
MinNodeScore int64 = 0
// MaxTotalScore is the maximum total score.
MaxTotalScore int64 = math.MaxInt64
)
...
const (
// MinExtenderPriority defines the min priority value for extender.
MinExtenderPriority int64 = 0
// MaxExtenderPriority defines the max priority value for extender.
MaxExtenderPriority int64 = 10
)
最后,给一个scheduler extender扩展的demo project,代码简单&无意义,不分析,只用于参考
scheduler framework
extender提供了非侵入scheduler core的方式扩展scheduler,但是有如下缺点:
- 缺少灵活性:extender提供的接口只能由scheduler core在固定点调用,比如:“Filter” extenders只能在默认预选结束后进行调用;而"Prioritize" extenders只能在默认优选执行后调用
- 性能差:相比原生调用func来说,走http/https + 加解JSON包开销较大
- 错误处理困难:scheduler core在调用extender后,如果出现错误,需要中断调用,很难将错误信息传递给extender,终止extender逻辑
- 无法共享cache:extender是webhook,以单独的server形式与scheduler一起运行,如果scheduler core提供的参数无法满足extender处理需求,同时由于无法共享scheduler core cache,那么extender需要自行与kube-apiserver进行通信,并建立cache
为了解决scheduler extender存在的问题,scheduler framework在scheduler core基础上进行了改造和提取,在scheduler几乎所有关键路径上设置了plugins扩展点,用户可以在不修改scheduler core代码的前提下开发plugins,最后与core一起编译打包成二进制包实现扩展
Scheduling Cycle & Binding Cycle
scheduler整个调度流程可以分为如下两个阶段:
- scheduling cycle:选择出一个节点以供pod运行,主要包括预选&优选,串行执行(一个pod调度完成后才调度下一个)
- binding cycle:将scheduling cycle选择的node与pod进行绑定,主要包括bind操作,并发执行(并发执行不同pod的绑定操作)
这两个阶段合称为"scheduling context",每个阶段在调度失败或者发生错误时都可能发生中断并被放入scheduler队列等待重新调度
Extension points
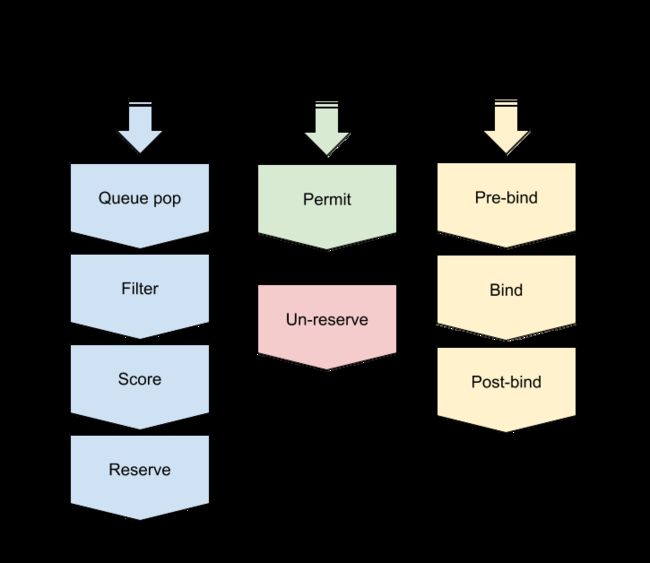
pod调度流程以及对应的scheduler plugins扩展点如下:
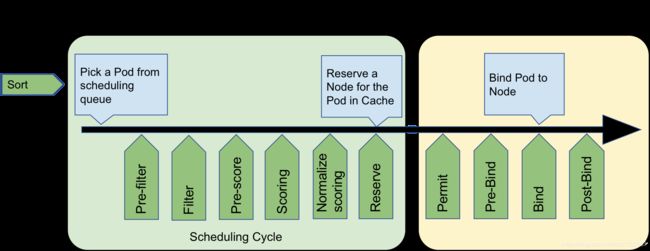
这里按照调用顺序依次介绍各个plugin扩展点:
- Queue sort:用于对scheduelr优先级队列进行排序,需要实现"less(pod1, pod2)"接口,且该插件只会生效一个
- Pre-filter:用于检查集群和pod需要满足的条件,或者对pod进行预选 预处理,需要实现"PreFilter"接口
- Filter:对应scheduler预选算法,用于根据预选策略对节点进行过滤
- Pre-Score:对应"Pre-filter",主要用于优选 预处理,比如:更新cache,产生logs/metrics等
- Scoring:对应scheduler优选算法,分为"score"(Map)和"normalize scoring"(Reduce)两个阶段
- score:并发执行node打分;同一个node在打分的时候,顺序执行插件对该node进行score
- normalize scoring:并发执行所有插件的normalize scoring;每个插件对所有节点score进行reduce,最终将分数限制在[MinNodeScore, MaxNodeScore]有效范围
- Reserve(aka Assume):scheduling cycle的最后一步,用于将node相关资源预留(assume)给pod,更新scheduler cache;若binding cycle执行失败,则会执行对应的Un-reserve插件,清理掉与pod相关的assume资源,并进入scheduling queue等待重新调度
- Permit:binding cycle的第一个步骤,判断是否允许pod与node执行bind,有如下三种行为:
- approve:允许,进入Pre-bind流程
- deny:不允许,执行Un-reserve插件,并进入scheduling queue等待重新调度
- wait (with a timeout):pod将一直持续处于Permit阶段,直到approve,进入Pre-bind;如果超时,则会被deny,等待重新被调度
- Pre-bind:执行bind操作之前的准备工作,例如volume相关的操作
- Bind:用于执行pod与node之间的绑定操作,只有在所有pre-bind plugins相关操作都完成的情况下才会被执行;另外,如果一个bind插件选择处理pod,那么其它bind插件都会被忽略
- Post-bind:binding cycle最后一个步骤,用于在bind操作执行成功后清理相关资源
在介绍完scheduler framework扩展点后,我们开始介绍如何按照framework规范进行plugins开发
Plugin dev process
step1 - Plugin Registration
scheduler framework plugins开发首先需要注册plugin,如下(k8s.io/kubernetes/cmd/kube-scheduler/app/server.go):
// PluginFactory is a function that builds a plugin.
type PluginFactory = func(configuration *runtime.Unknown, f FrameworkHandle) (Plugin, error)
// Registry is a collection of all available plugins. The framework uses a
// registry to enable and initialize configured plugins.
// All plugins must be in the registry before initializing the framework.
type Registry map[string]PluginFactory
// Register adds a new plugin to the registry. If a plugin with the same name
// exists, it returns an error.
func (r Registry) Register(name string, factory PluginFactory) error {
if _, ok := r[name]; ok {
return fmt.Errorf("a plugin named %v already exists", name)
}
r[name] = factory
return nil
}
// WithPlugin creates an Option based on plugin name and factory.
func WithPlugin(name string, factory framework.PluginFactory) Option {
return func(registry framework.Registry) error {
return registry.Register(name, factory)
}
}
func main() {
rand.Seed(time.Now().UnixNano())
// Register custom plugins to the scheduler framework.
// Later they can consist of scheduler profile(s) and hence
// used by various kinds of workloads.
command := app.NewSchedulerCommand(
app.WithPlugin(coscheduling.Name, coscheduling.New),
app.WithPlugin(qos.Name, qos.New),
)
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
我们需要实现自己的PluginFactory,并返回custom Plugin,例如:
// New initializes a new plugin and returns it.
func New(_ *runtime.Unknown, handle framework.FrameworkHandle) (framework.Plugin, error) {
podLister := handle.SharedInformerFactory().Core().V1().Pods().Lister()
return &Coscheduling{frameworkHandle: handle,
podLister: podLister,
}, nil
}
这里有两个参数:
- PluginConfig:plugin初始化参数
- FrameworkHandle:提供API访问kube-apiserver(例如:client (kubernetes.Interface) and SharedInformerFactory)以及scheduler core内部cache
// FrameworkHandle provides data and some tools that plugins can use. It is
// passed to the plugin factories at the time of plugin initialization. Plugins
// must store and use this handle to call framework functions.
type FrameworkHandle interface {
// SnapshotSharedLister returns listers from the latest NodeInfo Snapshot. The snapshot
// is taken at the beginning of a scheduling cycle and remains unchanged until
// a pod finishes "Reserve" point. There is no guarantee that the information
// remains unchanged in the binding phase of scheduling, so plugins in the binding
// cycle(permit/pre-bind/bind/post-bind/un-reserve plugin) should not use it,
// otherwise a concurrent read/write error might occur, they should use scheduler
// cache instead.
SnapshotSharedLister() schedulerlisters.SharedLister
// IterateOverWaitingPods acquires a read lock and iterates over the WaitingPods map.
IterateOverWaitingPods(callback func(WaitingPod))
// GetWaitingPod returns a waiting pod given its UID.
GetWaitingPod(uid types.UID) WaitingPod
// RejectWaitingPod rejects a waiting pod given its UID.
RejectWaitingPod(uid types.UID)
// ClientSet returns a kubernetes clientSet.
ClientSet() clientset.Interface
SharedInformerFactory() informers.SharedInformerFactory
}
在注册完plugin后,framework会在初始化时,利用这些参数对plugin进行实例化,如下:
// NewFramework initializes plugins given the configuration and the registry.
func NewFramework(r Registry, plugins *config.Plugins, args []config.PluginConfig, opts ...Option) (Framework, error) {
options := defaultFrameworkOptions
for _, opt := range opts {
opt(&options)
}
f := &framework{
registry: r,
snapshotSharedLister: options.snapshotSharedLister,
pluginNameToWeightMap: make(map[string]int),
waitingPods: newWaitingPodsMap(),
clientSet: options.clientSet,
informerFactory: options.informerFactory,
metricsRecorder: options.metricsRecorder,
}
if plugins == nil {
return f, nil
}
// get needed plugins from config
pg := f.pluginsNeeded(plugins)
if len(pg) == 0 {
return f, nil
}
pluginConfig := make(map[string]*runtime.Unknown, 0)
for i := range args {
pluginConfig[args[i].Name] = &args[i].Args
}
pluginsMap := make(map[string]Plugin)
for name, factory := range r {
// initialize only needed plugins.
if _, ok := pg[name]; !ok {
continue
}
p, err := factory(pluginConfig[name], f)
if err != nil {
return nil, fmt.Errorf("error initializing plugin %q: %v", name, err)
}
pluginsMap[name] = p
// a weight of zero is not permitted, plugins can be disabled explicitly
// when configured.
f.pluginNameToWeightMap[name] = int(pg[name].Weight)
if f.pluginNameToWeightMap[name] == 0 {
f.pluginNameToWeightMap[name] = 1
}
}
for _, e := range f.getExtensionPoints(plugins) {
if err := updatePluginList(e.slicePtr, e.plugins, pluginsMap); err != nil {
return nil, err
}
}
// Verifying the score weights again since Plugin.Name() could return a different
// value from the one used in the configuration.
for _, scorePlugin := range f.scorePlugins {
if f.pluginNameToWeightMap[scorePlugin.Name()] == 0 {
return nil, fmt.Errorf("score plugin %q is not configured with weight", scorePlugin.Name())
}
}
if len(f.queueSortPlugins) > 1 {
return nil, fmt.Errorf("only one queue sort plugin can be enabled")
}
return f, nil
}
func (f *framework) getExtensionPoints(plugins *config.Plugins) []extensionPoint {
return []extensionPoint{
{plugins.PreFilter, &f.preFilterPlugins},
{plugins.Filter, &f.filterPlugins},
{plugins.Reserve, &f.reservePlugins},
{plugins.PostFilter, &f.postFilterPlugins},
{plugins.Score, &f.scorePlugins},
{plugins.PreBind, &f.preBindPlugins},
{plugins.Bind, &f.bindPlugins},
{plugins.PostBind, &f.postBindPlugins},
{plugins.Unreserve, &f.unreservePlugins},
{plugins.Permit, &f.permitPlugins},
{plugins.QueueSort, &f.queueSortPlugins},
}
}
func updatePluginList(pluginList interface{}, pluginSet *config.PluginSet, pluginsMap map[string]Plugin) error {
if pluginSet == nil {
return nil
}
plugins := reflect.ValueOf(pluginList).Elem()
pluginType := plugins.Type().Elem()
set := sets.NewString()
for _, ep := range pluginSet.Enabled {
pg, ok := pluginsMap[ep.Name]
if !ok {
return fmt.Errorf("%s %q does not exist", pluginType.Name(), ep.Name)
}
if !reflect.TypeOf(pg).Implements(pluginType) {
return fmt.Errorf("plugin %q does not extend %s plugin", ep.Name, pluginType.Name())
}
if set.Has(ep.Name) {
return fmt.Errorf("plugin %q already registered as %q", ep.Name, pluginType.Name())
}
set.Insert(ep.Name)
newPlugins := reflect.Append(plugins, reflect.ValueOf(pg))
plugins.Set(newPlugins)
}
return nil
}
// framework is the component responsible for initializing and running scheduler
// plugins.
type framework struct {
registry Registry
snapshotSharedLister schedulerlisters.SharedLister
waitingPods *waitingPodsMap
pluginNameToWeightMap map[string]int
queueSortPlugins []QueueSortPlugin
preFilterPlugins []PreFilterPlugin
filterPlugins []FilterPlugin
postFilterPlugins []PostFilterPlugin
scorePlugins []ScorePlugin
reservePlugins []ReservePlugin
preBindPlugins []PreBindPlugin
bindPlugins []BindPlugin
postBindPlugins []PostBindPlugin
unreservePlugins []UnreservePlugin
permitPlugins []PermitPlugin
clientSet clientset.Interface
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
}
framework会根据Plugins配置初始化需要的插件,并根据插件类型添加到相应的扩展点plugins列表中
step2 - Plugin dev
在注册完plugin后,需要实现plugin相应的接口完成对应的功能,比如Filter(预选)和Scoring(优选)插件接口(k8s.io/kubernetes/pkg/scheduler/framework/v1alpha1/interface.go):
// Plugin is the parent type for all the scheduling framework plugins.
type Plugin interface {
Name() string
}
// FilterPlugin is an interface for Filter plugins. These plugins are called at the
// filter extension point for filtering out hosts that cannot run a pod.
// This concept used to be called 'predicate' in the original scheduler.
// These plugins should return "Success", "Unschedulable" or "Error" in Status.code.
// However, the scheduler accepts other valid codes as well.
// Anything other than "Success" will lead to exclusion of the given host from
// running the pod.
type FilterPlugin interface {
Plugin
// Filter is called by the scheduling framework.
// All FilterPlugins should return "Success" to declare that
// the given node fits the pod. If Filter doesn't return "Success",
// please refer scheduler/algorithm/predicates/error.go
// to set error message.
// For the node being evaluated, Filter plugins should look at the passed
// nodeInfo reference for this particular node's information (e.g., pods
// considered to be running on the node) instead of looking it up in the
// NodeInfoSnapshot because we don't guarantee that they will be the same.
// For example, during preemption, we may pass a copy of the original
// nodeInfo object that has some pods removed from it to evaluate the
// possibility of preempting them to schedule the target pod.
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *schedulernodeinfo.NodeInfo) *Status
}
...
// ScorePlugin is an interface that must be implemented by "score" plugins to rank
// nodes that passed the filtering phase.
type ScorePlugin interface {
Plugin
// Score is called on each filtered node. It must return success and an integer
// indicating the rank of the node. All scoring plugins must return success or
// the pod will be rejected.
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
// ScoreExtensions returns a ScoreExtensions interface if it implements one, or nil if does not.
ScoreExtensions() ScoreExtensions
}
这里一般会传递一个CycleState的参数给plugin,它代表了一个scheduling context(调度上下文),plugin可以利用CycleState获取本调度周期内的数据,另外也可以通过CycleState提供的API在不同plugin之间传递数据
需要注意的是:通过CycleState获取的数据只在本次调度周期内生效
另外,在开发plugin时还需要注意并发的概念,这里面存在两种场景的并发:
- 同一个插件可能在同一个scheduling context中被并发执行
- 同一个插件可能在不同的scheduling context中被并发执行
原因其实也很简单,就是:scheduling cycle是串行工作的(一个pod调度完成后才调度下一个);binding cycle是并发执行的(可以并行绑定pod),而scheduling context由这两部分组成
In the main thread of the scheduler, only one scheduling cycle is processed at a time. Any extension point up to and including reserve will be finished before the next scheduling cycle begins*. After the reserve phase, the binding cycle is executed asynchronously. This means that a plugin could be called concurrently from two different scheduling contexts, provided that at least one of the calls is to an extension point after reserve. Stateful plugins should take care to handle these situations.
step3 - Configuring Plugins
在开发完framework插件接口后,最后需要配置plugin(k8s.io/kubernetes/pkg/scheduler/apis/config/types.go),使plugin生效,如下:
// KubeSchedulerConfiguration configures a scheduler
type KubeSchedulerConfiguration struct {
...
// Plugins specify the set of plugins that should be enabled or disabled. Enabled plugins are the
// ones that should be enabled in addition to the default plugins. Disabled plugins are any of the
// default plugins that should be disabled.
// When no enabled or disabled plugin is specified for an extension point, default plugins for
// that extension point will be used if there is any.
Plugins *Plugins
// PluginConfig is an optional set of custom plugin arguments for each plugin.
// Omitting config args for a plugin is equivalent to using the default config for that plugin.
PluginConfig []PluginConfig
}
// Plugins include multiple extension points. When specified, the list of plugins for
// a particular extension point are the only ones enabled. If an extension point is
// omitted from the config, then the default set of plugins is used for that extension point.
// Enabled plugins are called in the order specified here, after default plugins. If they need to
// be invoked before default plugins, default plugins must be disabled and re-enabled here in desired order.
type Plugins struct {
// QueueSort is a list of plugins that should be invoked when sorting pods in the scheduling queue.
QueueSort *PluginSet
// PreFilter is a list of plugins that should be invoked at "PreFilter" extension point of the scheduling framework.
PreFilter *PluginSet
// Filter is a list of plugins that should be invoked when filtering out nodes that cannot run the Pod.
Filter *PluginSet
// PostFilter is a list of plugins that are invoked after filtering out infeasible nodes.
PostFilter *PluginSet
// Score is a list of plugins that should be invoked when ranking nodes that have passed the filtering phase.
Score *PluginSet
// Reserve is a list of plugins invoked when reserving a node to run the pod.
Reserve *PluginSet
// Permit is a list of plugins that control binding of a Pod. These plugins can prevent or delay binding of a Pod.
Permit *PluginSet
// PreBind is a list of plugins that should be invoked before a pod is bound.
PreBind *PluginSet
// Bind is a list of plugins that should be invoked at "Bind" extension point of the scheduling framework.
// The scheduler call these plugins in order. Scheduler skips the rest of these plugins as soon as one returns success.
Bind *PluginSet
// PostBind is a list of plugins that should be invoked after a pod is successfully bound.
PostBind *PluginSet
// Unreserve is a list of plugins invoked when a pod that was previously reserved is rejected in a later phase.
Unreserve *PluginSet
}
// PluginSet specifies enabled and disabled plugins for an extension point.
// If an array is empty, missing, or nil, default plugins at that extension point will be used.
type PluginSet struct {
// Enabled specifies plugins that should be enabled in addition to default plugins.
// These are called after default plugins and in the same order specified here.
Enabled []Plugin
// Disabled specifies default plugins that should be disabled.
// When all default plugins need to be disabled, an array containing only one "*" should be provided.
Disabled []Plugin
}
// Plugin specifies a plugin name and its weight when applicable. Weight is used only for Score plugins.
type Plugin struct {
// Name defines the name of plugin
Name string
// Weight defines the weight of plugin, only used for Score plugins.
Weight int32
}
// PluginConfig specifies arguments that should be passed to a plugin at the time of initialization.
// A plugin that is invoked at multiple extension points is initialized once. Args can have arbitrary structure.
// It is up to the plugin to process these Args.
type PluginConfig struct {
// Name defines the name of plugin being configured
Name string
// Args defines the arguments passed to the plugins at the time of initialization. Args can have arbitrary structure.
Args runtime.Unknown
}
plugin配置按照作用分为两类:
- 各扩展点的启动 or 禁止插件列表,scheduler会在该扩展点执行完默认插件后,按照列表顺序执行插件,如果该扩展点列表为空,则使用默认插件列表
- 插件的参数列表,如果某个插件对应的参数配置为空,则该插件会使用默认配置
这里要注意插件配置是按照扩展点组织的,如果一个插件同时实现了若干个扩展点功能(比如同时实现了预选&优选接口),则需要分别填写在preFilter与score列表中,如下(PluginA)所示:
{
"plugins": {
"preFilter": [
{
"name": "PluginA"
},
{
"name": "PluginB"
},
{
"name": "PluginC"
}
],
"score": [
{
"name": "PluginA",
"weight": 30
},
{
"name": "PluginX",
"weight": 50
},
{
"name": "PluginY",
"weight": 10
}
]
},
"pluginConfig": [
{
"name": "PluginX",
"args": {
"favorite_color": "#326CE5",
"favorite_number": 7,
"thanks_to": "thockin"
}
}
]
}
综上,给出了基于scheduler framework扩展scheduler的相关原理分析和开发指引。基于该框架实现的项目可以参考coscheduling(aka gang scheduling)
Conclusion
本文介绍了扩展kube-scheduler的四种方式。其中default-scheduler recoding与standalone属于侵入式的方案,两者都需要对scheduler core进行修改并编译。相比而言,standalone属于重度二次定制;scheduler extender与scheduler framework属于非侵入式的方案,无需修改scheduler core。extender采用webhook的方式进行扩展,在性能和灵活性方面都很欠缺,framework通过对scheduler core进行提取和重构,在调度流程几乎每个关键路径上都设置了插件扩展点,用户通过开发插件,达到非侵入scheduler core的目的,同时很大程度解决了extender在性能和灵活性上的短板
最后关于扩展kube-scheduler,建议如下:
- scheduler framework可以解决绝大多数扩展问题,同时也是Kubernetes官方推荐的方式,优先采用该方案进行扩展
- extender适用于比较简单的扩展场景,在Kubernetes版本不支持framework的情况下可以使用
- 如果以上方法都无法满足对scheduler扩展的需求(几乎不可能),则建议采用standalone方案进行二次定制,同时建议只部署一个scheduler
Refs
- Scheduler extender
- The Kubernetes Scheduler
- 扩展 Kubernetes 之 Scheduler
- Scheduling Framework
- Scheduling Profiles
- design proposal of the scheduling framework
- scheduler-plugins
