时间:2016-8-18 01:17
停下休息的时候不要忘记,比你强的人还在奔跑
----------------------------------------------------------------------------
第一章:数据库系统概述
一、数据库的产生动机
1.1 所有事物的产生都一定会有它的客观规律,对于计算机而言,最早是为了解决计算问题,而数据库的产生主要也是为了解决数据的有效管理。
1.2 数据库,顾名思义,存储的肯定都是数据,而数据库的产生是为了解决商业管理中的数据应运而生的。
1.3 数据库可以解决数据的统一管理问题。
二、数据、数据库、数据库管理系统、数据库系统
2.1 数据:描述事物的符号记录称为数据
数据是数据库中存储的基本对象,除了基本的数字之外,像图书的名称、价格、作者等都可以称为数据。
2.2 数据库
是存放数据的仓库,所有的数据在计算机存储设备上保存,而且所有保存的数据会按照一定的格式进行保存。
数据库是长期存储在计算机内、有组织的、可共享的大容量数据的集合,数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并可以为各种用户共享,所以数据库具有永久存储、有组织和可共享的三个基本特点。
一、Oracle简介
在进行别名设置的时候,可以通过as关键字来进行操作,对于最终的结果没有任何影响,但是,如果要进行别名的设置,在程序中肯定是没用的,那么在显示中用处也不大,而且要记住,不要使用中文。
1.6 小结
1、限定查询
2、关系运算符
2.4 关系运算符——范例
查询不是业务员切基本工资不大于2000的全部雇员信息。
基本实现:select * from emp where job != 'CLERK' and sal > 2000;
使用not对条件求反:select * from emp where not (job = 'CLERK' or sal <= 2000);
对职位以及工资进行判断,这两个判断条件需要同时满足。
3、范围查询
语法:字段 | 列 between 最小值 and 最大值
between ... and ... 操作符的主要功能是针对于一个指定的数据范围进行查找,在设置范围的时候,可以是数字、字符串或者是日期类型的数据。
3.1 范围查询——范例
使用between and 操作符查询出工资范围在1500到3000(包含)的全部雇员的信息。
select * from emp where sal between 1500 and 3000;
分析:
对于这样的操作,在之前可以利用两个关系运算符进行筛选,而有了between and之后,可以直接筛选。
3.2 范围查询——范例
查询在1981年雇佣的全部雇员的信息。
select * from emp where hiredate between '01-1月 -81' and '31-12月 -81';
分析:
在这个查询中一定会用到hiredate字段,但是现在并没有学过有关于日期的处理,所以此时如果想要进行日期格式的编写。
因为Oracle出现年代的原因,81仅代表1981,如果想表示2081,则需要写2081。
如果说是在1981年雇佣,那么范围就是:1981-01-01~1981-12-31,只需要利用between and 将这两个日期设置在内即可实现。
实际上这就实现了日期和字符串数据之间的自动转换操作功能。
4、null判断
4.1 判断内容是否为null
语法:
判断为null:
字段 | 值 is null;
判断不为null:
字段 | 值 is not null (not 字段 | 值 is null);
null是一个未知的数据,所以对于null的处理,如果直接利用关系运算符判断是无法判断的。
4.2 范例——利用=进行null判断
select * from emp where comm = null;
这时候不会有任何的结果返回,因为null不能使用=进行判断。
4.3 null判断——范例
查询出所有领取佣金的雇员的完整信息。
实现一:select * from emp where comm is not null;
实现二:select * from emp where not comm is null;
分析:
佣金的字段是comm,领取佣金的概念就是佣金不为null。
4.4 null判断——范例
查询所有不领取佣金的雇员的完整信息。
select * from emp where comm is null;
分析:
不领取佣金那么comm字段的内容就是null。
4.5 null判断——范例
列出所有不领取佣金的雇员,而且同时要求这些雇员的基本工资大于2000的全部雇员的信息。
select * from emp where comm is null and sal > 2000;
4.6 null判断——范例
查询没有佣金或佣金低于100的员工。
select * from emp where comm is null or comm < 100;
4.7 null判断——范例
查询收取佣金的员工的不同工作。
select distinct job as 工作 from emp where comm is not null;
分析:
既然现在要找的是职位,那么很有可能出现重复的数据,重复的数据必须使用distinct去除。
5、列表范围查找
所谓的列表范围指的是给了用户固定的几个参考值,只要符合这个值就满足条件。
语法:
在指定数据范围内:字段 | 值 in(值,值,...)
不在指定数据范围内:字段 | 值 not in(值,值,...)
5.1 范围判断——范例
查询出雇员编号是7369、7788、7566的雇员信息。
select * from emp where empno in (7369,7788,7566);
分析:
那么如果面对这样的操作,如果此时不使用in操作符,可以利用多个条件并且使用or进行连接。
5.2 范围判断——范例
查询除了7369、7788、7566之外的雇员信息。
select * from emp where empno not in(7369,7788,7566);
分析:
现在一定不在范围之内,所以使用not in进行判断。
但是在使用not in操作时需要注意,关于null的问题:
如果现在使用的是in操作符判断的范围数据之中包含了null,那么不会影响最终结果。
但是如果使用not in里面包含null字段,结果就是没有任何数据显示。
原因:
使用not in或in其目的是显示部分数据内容,如果说现在有一列数据不可能为null,并且not in里面判断null的条件满足了,那么就表示查询全部数据。
6、like模糊查询
语法:
模糊查询:字段 | 值 like 匹配标记
不满足模糊查询:字段 | 值 not like 匹配标记。
如果现在想对某一列进行某查询,可以使用like子句完成,通过like可以进行关键字的模糊查询,like子句中有两个通配符:
百分号(%):
可以匹配任意类型和长度的字符,如果是中文则使用两个百分号。
出现0次1次或多次。
下划线(_):
匹配单个任意字符,它常用来限制表达式的字符长度。
出现1次。
6.1 模糊查询——范例
现在查询出雇员姓名是以S开头的全部雇员的信息。
select * from emp where ename like 'S%';
分析:
在S之后的内容可以是任意的数据,可能是0位,可能是1位,也可能是多位。
6.2 模糊查询——范例
查询雇员姓名的第二个字母是M的全部雇员信息。
select * from emp where ename like '_M%';
分析:
现在只是要求第二个字母,所以第一个字母可以是任意数据,所以使用“_”占位。
6.3 模糊查询——范例
查询出姓名中任意位置包含字母F的雇员信息。
select * from emp where ename like'%F%';
分析:
现在可能是开头,也可能是结尾,或者是在中间,所以就必须要考虑到前后都有的问题,那么可以使用“%”。
6.4 模糊查询——范例
查询雇员姓名长度为6或者是超过6个的雇员信息。
select * from emp where ename like '______%';
分析:
姓名的长度为6个字符,那么可以写6个下划线,如果超过6个,可以加一个“%”。
6.5 模糊查询——范例
查询出雇员基本工资中包含1或者是在81年雇佣的全部雇员信息。
select * from emp where sal like'%1%' or hiredate like '%81%';
分析:
在之前的所有查询中都是针对于字符数据进行操作,而对于like而言,也可以在数字或者日期类型上使用。
但是有一点需要提醒,如果在设置模糊查询的时候不设置关键字,则表示查询全部。
这一种操作在日后的程序开发中也是很常见的(DAO设计模式)。
6.6 模糊查询——范例
找出部门10种所有经理,部门20种所有的业务员,既不是经理又不是业务员但是其薪资大于等于2000的所有员工的详细信息,并且要求这些员工的姓名之中包含字母S或字母K。
select * from emp
and (ename like '%S%' or ename like '%K%');
现在存在以下的几个条件:
条件一:10部门的经理。。
条件二:20部门的业务员。
条件三:不是经理和办事员,但是工资大于或等于2000。
条件四:以上所有的条件满足后再过滤,包含字母S或字母K。
7、小结
7.1 限定查询主要使用where子句,用于对选取的数据行进行控制。
7.2限定查询主要的运算符:关系运算符、between...and、in、is null、like
四、排序显示
要求:
掌握order by子句的使用;
掌握各个子句的执行顺序。
传统数据查询的时候,只会按照设置的主键进行排列,如果现在希望对指定的列进行排序操作,那么就需要通过order by子句进行控制。
语法:
select [distinct] * | 列名 [as] 列别名,...
from 表名
[where 条件(s)]
order by 排序的字段 | 列索引序号 asc|desc,排序的字段2 asc|desc....
在order by子句之中可以指定要进行排序的字段,有两种排序模式:
升序:ASC,默认
降序:DESC,需要手动指定
在所有的子句之中,order by子句是放在查询语句的最后一行,是最后一个执行的:
from -> where -> select -> order by。
既然order by在select之后执行,那么就表示order by子句可以使用select子句中设置的别名了。
1.1 数据排序——范例
查询雇员的完整信息并且按照基本工资由高到低进行排序。
select * from emp order by sal desc;
分析:
现在是针对所有数据行进行排序,那么直接执行order by子句即可。
1.2 数据排序——范例
按照基本工资由低到高进行排序。
select * from emp sal;
select * from emp sal asc;
分析:
之前使用的是一个降序排列,现在进行升序排列,默认使用asc,也可以手动指定asc。
1.3 数据排序——范例
查询出所有业务员的详细资料,并且按照基本工资由低到高排序。
select * from emp where job = 'CLERK' order by sal ;
分析:
现在不再是针对所有的数据进行排序,需要对数据执行筛选,可以使用where子句完成。
1.4 数据排序——范例
查询所有雇员的信息,要求按照基本工资由高到低排序,如果工资相等则按照雇用日期进行排序,由早到晚排序。
select * from emp order by sal desc,hiredate ;
分析:
现在的排序需要设置两个排序的字段:sal(DESC),hiredate(ASC)
本程序的语法没有问题,有问题的是在于数据中,因为现在的数据都是后期处理的结果,如果想要正常的观察数据,那么可以将数据库切换到PDB之中,找到原始的scott用户数据。
对于排序,除了使用字段之外,也可以设置序号,但是此操作不建议使用。
select empno,ename,sal,job
2、小结
使用order by子句可以对查询结果进行排序,order by子句一定要写在所有查询语句的最后。
五、单行函数
什么是函数?
函数就是和Java语言中的方法的功能是一样的,都是为了完成某些特定操作的功能支持。
而在Oracle数据库里面也包含了大量的单行函数,掌握这些函数之后,可以方便的帮助进行对数据库相关的开发。
对于开发者而言,最重要的就是SQL语法和单行函数。
开发分为两种:
SQL开发,数据库和程序的结合。
第二部分是函数,过程等开发(PL/SQL编程)。
Oracle中的单行函数的数量是非常多的,本章只讲解使用,后面会讲解如何开发用户自己的函数(PL/SQL编程)。
语法:
function_name(列 | 表达式[参数1,参数2]);
单行函数主要分为以下几种:
字符串函数:接收数据返回具体的字符信息。
数值函数:对数字进行处理,例如四舍五入。
日期函数:直接对日期进行相关的操作。
转换函数:日期、字符、数字之间可以完成相互转换功能。
通用函数:Oracle提供的有特色的函数。
1、字符串函数
字符串函数一定是以字符数据为主。
函数:
1)upper(列 | 字符串)
将字符串的内容全部转换为大写。
2)lower(列 | 字符串)
将字符串的内容全部转换为小写。
3)initcap(列 | 字符串)
将字符串的开头首字母大写。
4)replace(列 | 字符串,旧字符串, 新字符串)
使用新字符串替换旧字符串。
5)length(列 | 字符串)
求出字符串的长度。
6)substr(列 | 字符串,开始点,[长度])
截取字符串。
7)ascii(字符)
返回指与指定字符对应的ASCII码。
8)chr(数字)
给出一个数字,并返回与之对应的字符。
9)rpad(列 | 字符串,字符串长度,填充字符)
lpad(列 | 字符串,字符串长度,填充字符)
在左或右填充指定的字符,使字符串达到指定长度为止。
10)ltrim(字符串)
rtrim(字符串)
去掉左或右的空格。
11)trim(列 | 字符串)
去掉左右空格。
12)instr(列 | 字符串, 要查找的字符串)
查找一个子字符串是否在指定的位置上出现。
1.1 字符串函数——范例
这里会出现一个问题,在Oracle里面所有的验证操作必须存在于完整的SQL语句之中,所以如果现在只是进行功能验证,使用的是一张具体的表。
验证upper()和lower()函数。
select upper('wangyanchao') from emp;
会发现重复显示14行‘WANGYANCHAO’,所以现在函数功能的确是成功验证,但是代价太高。
如果使用distinct可以消除重复列,那么emp表中的数据很多呢?那样中间处理的数据量就会很大,所以现在就希望有一张表可以帮助用户进行验证,而在Oracle中提供了一个dual的虚拟数据表。
1.2 字符串函数——范例
现在查询出雇员姓名是‘smith’的完整信息,但是由于失误,没有考虑到数据的大小写问题(在一些项目的运行之中经常会出现此类输入数据不考虑大小写的问题),此时可以使用upper()函数将内容全部变为大写。
select * from emp where ename = upper('smith');
在一些系统之中,有一些是不区分大小写用户名的,那么他的做法就是将用户注册时所有资料都变为了大写或小写。
1.3 字符串函数——范例
查询所有雇员的姓名,要求每个雇员的姓名以首字母大写的形式出现。
select initcap(ename) from emp;
分析:
首字母大写,那么其他字母一定都是小写,所以就可以利用initcap()函数进行处理。
1.4 字符串函数——范例
查询所有雇员的姓名,要求将所有雇员姓名中的字母“A”替换成字母“_”。
select replace(ename,'A','_') from emp;
分析:
字符串的替换一定是replace()函数。
1.5 字符串函数——范例
查询出姓名长度是5的所有雇员信息。
select * from emp where length(ename) = 5;
分析:
如果想要计算长度,那么使用的一定是length()函数,返回的长度一定是数值型数据。
1.6 字符串函数——范例
查询出雇员姓名前三个字母是‘JAM’的雇员信息。
select * from emp where substr(ename,0,3) = 'JAM';
分析:
现在需要截取前三个字符,那么截取的操作一定就要使用substr()函数。
substr()函数包含头不包含尾。
可是在截取之前,需要注意sunstr()函数有两种形式:
从指定位置截取到结尾:
substr(列 | 字符串, 截取开始位置);
截取部分字符串:
substr(列 | 字符串, 截取开始位置,截取字符个数);
需要注意的是,在Oracle数据库之中,下标都是从1开始,如果设置为0,那么也会将其自动转换为1。
1.7 字符串函数——范例
查询所有10部门的雇员,但是不显示每个雇员姓名的前三个字母。
select substr(ename,3) from emp where deptno = 10;
1.8 字符串函数——范例
显示每个雇员姓名及其姓名的后三个字母。
select substr(ename, length(ename)-2) from emp;
也可以在substr()函数中设置负数参数。
select substr(ename, -3) from emp;
分析:
如果想要截取每个姓名之中的后三个字符,首先要解决的问题就是开始位置,从一个指定的开始位置一直截取到结尾。
可是每个雇员的姓名长度并不相同,那么开始位置如何确定呢?
实现一:使用传统做法,先求得姓名长度,然后减去2来确定开始位置。
实现二:可以设置开始位置为负数,可以理解为从右开始计算。
面试题:
很明显使用第二种方法最为方便,这个也属于Oracle的特色,不过需要注意的是:Java语言的字符串下标还是从0开始,而且Java语言里面的substring()方法是不能够设置负数的。
1.9 字符串函数——范例
返回指定字符的ASCII码。
select ascii('a') from dual;
1.10 字符串函数——范例
验证chr()函数,将ASCII码变回字符串。
select chr(65) from dual;
1.11 字符串函数——范例
去掉字符串左边的空格。
select ltrim(' aa') from dual;
rtrim()、trim()方法原理一致。
中间空格无法消除。
1.12 字符串函数——范例
字符串填充——lpad()、rpad()
select lpad('aa',5,'*') from dual;
也可以rpad()和lpad()组合使用。
select rpad(lpad('aa',5,'*'),8,'*') from dual;
1.13 字符串函数——范例
字符串查找——instr()。
select instr('aaaaaabaaa','b') from dual;
分析:
如果查找到指定内容,那么此函数就会返回该字符串首字符出现的位置,如果找不到,则返回0。
这个函数和Java中的indexOf()方法功能是相同的。
2、数值函数
要求:
掌握数值函数的使用。
函数:
round(数字 [保留位数])
对小数进行四舍五入,可以指定保留位,如果不指定,则表示将小数点之后的数字全部进行四舍五入。
trunc(数字[截取位数])
保留指定为数的小数,如果不指定,则表示不保留小数。
mod(数字,数字)
取模。
2.1 数值函数——范例
验证round()函数。
select round(789.652) from dual;
如果不设置参数,则默认不保留小数位。
select round(789.652,2) from dual;
保留两位小数。
select round(789.652,-3) from dual;
处理整数进位。
2.2 数值函数——范例
列出每个雇员的一些基本信息和日工资情况。
select ename , round(sal/30,2) from emp;
分析:
对于日工资的计算可以采用30天为基础,肯定会有小数,就保留两位。
2.3 数值函数——范例
验证trunc()函数。
select trunc(789.652) from dual;
去掉小数,并且不进位。
select trunc(789.652,2) from dual;
保留两位小数,并且不进位。
2.4 数值函数——范例
验证mod()函数。
select mod(10,3) from dual;
10%3。
3、日期函数
要求:
掌握日期的数学计算操作。
掌握日期函数的使用。
函数:
add_months(日期, 数字)
在指定的日期上加入指定的月数,求出新的日期。
months_between(日期1, 日期2)
求出两个日期间的雇佣月数。
next_day(日期,星期数)
求出下一个的星期X的具体日期。
last_day(日期)
求出指定日期的最后一天日期。
extract(日期1, 日期2)
日期时间分割,或计算给定两个日期间隔的月数。
如果现在想要进行日期的操作,那么一定会存在一个前提:那就是必须知道当前日期。
3.1 取得当前的系统时间
在Oracle中,用户可以直接通过sysdate表示出当前的系统时间。
select sysdate from dual;
可以直接利用sysdate伪列取得当前日期时间。
所谓的伪列指的是不是表中的列,但是又可以直接使用的列,叫做伪列。
3.2 修改日期显示格式
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
3.3 日期操作公式
除了取得系统时间的操作之外,在Oracle中也有如下三个日期操作公式:
日期 - 数字 = 日期;
若干天前的日期。
日期 + 数字 = 日期;
若干天后的日期。
日期 - 日期 = 数字(天数);
两个日期的时间差。
绝对不会存在“日期 + 日期”的计算。
3.4 日期函数——范例
查询出每个雇员的到今天为止的雇佣天数、以及十天前每个雇员的雇佣天数。
select round(sysdate - hiredate) as 雇佣天数, round(sysdate - 10 - hiredate) as 十天前雇佣天数 from emp;
分析:
如果要想计算天数唯一可以使用的公式就是“日期1 - 日期2”,日期1肯定是使用sysdate取得当前的日期,而日期2就是每一位雇员的hiredate。
以上只是针对于当前日期的操作,而对于Oracle而言,也提供相应的日期函数,之所以使用日期函数,主要是为了避免闰年等问题。
3.5 日期函数——范例
验证add_months()函数。
select sysdate, add_months(sysdate, 3) as 三个月之后的日期, add_months(sysdate, -3) as 三个月之前的日期, add_months(sysdate, 60) as 六十个月之后的日期 from dual;
分析:
使用add_months()函数的主要功能是在一个指定日期上增加若干个月之后求得的日期。
可以使用负数。
3.6 日期函数——范例
要求显示所有雇员在被雇佣三个月之后的日期。
select EMPNO ,ENAME ,JOB ,HIREDATE ,
分析:
需要查询出每一位雇员在雇佣三个月之后的信息,可以通过查询hiredate来增加3个月得到雇员信息。
注意:别名长度不能超过30个字符。
3.7 日期函数——范例
验证next_day()函数,next_day()函数的功能是求出下一个指定的日期数,如果说现在的日期是“2012年01月30日 星期一”,那么如果现在想要知道下一个星期一或星期日的具体日期,则可以使用next_day()函数。
select sysdate, next_day(sysdate,'星期一') as 下一个星期一日期 from dual;
3.8 日期函数——范例
验证last_day()函数,使用last_day()函数可以求得指定日期所在月的最后一天日期,如果今天的日期是“2016年01月19日”,则使用last_day()求出来的日期就是“2016年1月31日”。
select last_day(sysdate) from dual;
3.9 日期函数——范例
查询所有事在其雇佣所在月的倒数第三天被公司雇佣的完整雇员信息。
select * from emp where last_day(hiredate)-2 = hiredate;
分析:
每一位雇员都有自己的雇用日期,阿么现在要求查询出雇用日期在本月倒数第三天雇佣的人。
首先需要雇员雇用日期所在月的最后一天:last_day(hiredate);
3.10 日期函数——范例
还有一个函数称为months_between()函数,此函数的功能是取得两个日期之间所经过的月份间隔。
查询出每个雇员的编号、姓名、雇用日期、雇佣的月数及年份。
select empno as 雇员编号, ename as 雇员姓名, hiredate as 雇佣日期, trunc(months_between(sysdate,hiredate)) as 雇佣月数, trunc(months_between(sysdate,hiredate)/12) as 雇佣年份 from emp;
扩充:
查询出每个雇员的编号、姓名、雇用日期、已雇佣的年数、月数、天数。
对于本程序而言,一定是分步计算,而且有一定的难度,因为需要操作的准确性。
例如:
今天的日期是2016年8月24日,那么MARTIN的雇用日期是1980-09-28,那么这位雇员到今天为止被雇佣了
步骤一:
求出年,年只需要依靠月就可以计算出来。
select empno,ename,hiredate, trunc(months_between(sysdate,hiredate)/12) as 已雇佣年数 from emp;
步骤二:
求出月,计算年的时候存在小数,那么这里面的数据就是月,只需要求模即可得到。
步骤三:
是针对于天的计算,因为现在已经计算出了年和月,所以天应该抛去年和月的数字信息。
现在的问题是,如果想要计算天数,唯一知道的公式就是“日期1-日期2”,那么日期1一定使用的是sysdate,而日期2(应该去掉年和月),可以利用add_months()函数实现此功能。
3.11 extract()函数
在Oracle 9i之后增加了一个extract()函数,此函数的功能主要是从一个日期时间(date)或者是时间间隔(interval)中截取出特定的部分,此函数的使用语法如下所示:
extract([year | month | day | hour | minute | second] | [timezone_hour | timezone_minute] | [timezone_region _ timezone_abbr] from [日期(date_value) | 时间间隔(interval_value)])
范例:
从日期时间中取出年、月、日数据。
select extract(year from date '2016-08-25') years, extract(month from date '2016-08-25') months, extract(day from date '2016-08-25') days from dual;
分析:
现在是通过一个日期的字符串完成的,那么也可以利用当前日期完成(sysdate,systimestamp)
3.12 日期函数——范例
从时间戳中取出年、月、日、时、分、秒。
select extract(year from systimestamp) years, extract(month from systimestamp) months, extract(day from systimestamp) days, extract(hour from systimestamp) hours, extract(minute from systimestamp) minutes, extract(second from systimestamp) seconds from dual;
3.13 日期函数——范例
验证to_timestame()函数。
除了以上的操作之外,主要的功能是取得时间间隔,此处需要用到一个时间转换函数:
to_timestamp(),可以将字符串转换为时间戳,而且此处的内容需要使用到部分的子查询功能。
select extract(day from to_timestamp('2016-08-26 12:22:22','yyyy-mm-dd hh24:mi:ss') - to_timestamp('2015-08-26 13:33:33','yyyy-mm-dd hh24:mi:ss')) days from dual;
3.14 小结
日期可以与数字进行运算。
使用日期函数可以解决闰年的问题。
4、转换函数
要求:
掌握字符、数字、日期间的转换操作。
在数据库之中主要使用的数据类型:字符、数字、日期(时间戳),所以这三类数据类型之间就需要实现转换操作,那么这个就属于转换函数的功能。
函数:
to_char(日期 | 数字 | 列, 转换格式)
将指定的数据按照指定的格式变为字符串。
to_date(字符串 | 列, 转换格式)
将指定字符串按照指定的格式变为date型。
to_number(字符串 | 列)
将指定的数据类型变为数值类型。
4.1 to_char()函数
通过名称就可以发现,此函数的功能是将数据类型变为字符串。
在默认情况下,如果查询一个日期,则日期默认的显示格式为“31-01月 16”,而这样的日期显示效果肯定不如常见的“2016-01-31”看起来舒服,所以此时就可以通过to_char()函数对这个显示的日期数据进行格式化(格式化之后的数据是字符串),但是如果要完成这种格式化,则首先需要熟悉一下格式化日期的替代标记。
日期格式化标记:
01)yyyy 完整的年费数字表示,年有四位,所以使用四个y。
02)y,yyy 带逗号的年。
03)yyy 年的后三位。
04)yy 年的后两位。
05)y 年的最后一位。
06)year 年份的文字表示,直接表示四位的年。
07)month 月份的文字表示,直接表示两位的月。
08)mm 用两位数字来表示月份,月有两位,所以使用两个m。
09)day 天数的文字表示。
10)ddd 表示一年中的天数。
11)dd 表示一月中的天数。
12)d 表示一周中的天数。
13)dy 用文字表示星期几。
14)ww 表示一年中的周数。
15)w 表示一月中的周数。
16)hh 表示12小时制,小时是两位数字,所以使用两个h。
17)hh24 表示24小时制。
18)mi 表示分钟。
19)ss 表示秒,秒是两位数字,所以使用两个s。
20)sssss 午夜之后的秒数字表示(0~86399)
21)fm 去掉查询后的前导0,该标记用于时间模板的后缀。
22)am | pm 表示上午或下午。
格式化数字标记:
1)9 表示一位数字。
2)0 显示前导0。
3)$ 将货币的符号显示为美元符号。
4)L 根据语言环境不同,自动选择货币符号。
5). 显示小数点。
6), 显示千位符。
在to_char()函数中,需要使用两个参数:日期数据、转换格式。
select sysdate 当前系统时间, to_char(sysdate,'yyyy-mm-dd') 格式化日期, to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') 精确到秒, to_char(sysdate,'fmyyyy-mm-dd hh24:mi:ss') 去掉前导0 from dual;
在开发之中建议不要取消前导0,因为会导致字符串长度发生变化。
除了使用标记(使用标记是一种习惯,就像java.text.SimpleDateFormat类一样),也可以使用单词来表示。
select sysdate 当前系统时间, to_char(sysdate,'year-month-day')格式化日期 from dual;
4.2 转换函数——范例
查询出所有在每年2月份雇佣的雇员信息。
select * from emp where '02' = to_char(hiredate,'mm')
select * from emp where 2 = to_char(hiredate,'mm')
分析:
可以利用to_char()函数从雇用日期中去的雇佣的月份。
4.3 转换函数——范例
将每个雇员的雇用日期进行格式化显示,要求所有的雇用日期可以按照“年--月-日”的格式进行显示,也可以将雇佣的年、月、日拆开分别显示。
select ename,job,hiredate, to_char(hiredate,'yyyy-mm-dd'), to_char(hiredate,'yyyy') 年, to_char(hiredate,'mm') 月, to_char(hiredate,'dd') 日 from emp;
4.4 to_char()函数格式化数字
to_char()函数最为要的功能是可以将数字进行格式化。
格式化数字显示:
select to_char(987654321.123,'999,999,999,999.9999') 格式化数字 from dual;
select to_char(987654321.123,'000,000,000,000.0000') 增加前导0 from dual;
除了对数字格式化,也可以对货币进行显示:
select to_char(987654321.123,'l000,000,000,000.000000') 根据语言自动选择货币, to_char(987654321.123,'$000,000,000,000.000000') 显示美元 from dual;
在开发之中,to_char()函数的作用还是非常明显的,建议掌握。
4.5 to_date()函数
这个函数主要是将字符串变为日期类型数据,而改变的过程中依然需要之前to_char()函数中使用的相关标记。
字符串转日期:
select to_date('2016-08-27','yyyy-mm-dd') from dual;
4.6 to_number()函数
to_number()函数的作用就是将字符串变为数字。
使用to_number()函数将字符串变为数字:
select 18 + to_number('5') from dual;
不使用to_number()函数字符串也可以自动变为数字:
select 18 + '5' from dual;
Oracle里面支持数据类型的自动转型。
4.7 通用函数
目标:掌握Oracle函数的使用。
函数:
1)nvl(数字 | 列, 默认值)
如果现实的数字是null的话,则使用默认数值表示。
2)nvl2(数字 | 列, 返回结果一(不为空显示), 返回结果2(为空显示))
判断指定的列是否为null,如果不为null则返回结果一,如果为null则返回结果二。
3)nullif(表达式一, 表达式二)
比较表达式一和表达式二的结果是否相等,如果相等返回null,如果不相等返回表达式一。
4)decode(列 | 值, 判断值1, 显示结果1, 判断值2, 显示结果2..., 默认值)
多值判断,如果某一个列(或某一个值)与判断值相同,则使用指定的显示结果输出,如果没有满足条件,则显示默认值。
5)case 列 | 数值 when 表达式1 then 显示结果1... else 表达式n ... end
用于实现多条件判断,在when之后编写条件,而在then之后编写条件满足所进行的操作,如果都不满足,则使用else中的表达式处理。
6)coalesce(表达式1, 表达式2, ... 表达式n)
将表达式诸葛进行判断,如果表达式1的内容是null,则显示表达式2,如果表达式2的内容是null,则显示表达式3,以此类推,如果表达式n的结果还是null,则返回null。
对于通用函数而言,只有两个核心函数:nvl()、decode()。
4.8 使用nvl()函数处理null。
在数据库之中,null是无法进行计算的,即在一个数学计算之中如果存在了null,则最后的结果肯定是null。
要求查询出每个雇员的编号、姓名、职位、雇用日期、年薪。
select empno,ename,job,hiredate,(sal+comm)*12 年薪 from emp;
可以发现,有的人年薪为null,因为comm上的内容有的是null,而只要是null参与运算,则最终的结果都是null。
所以在这种情况下,就需要针对null进行处理,此时可以将null转变为0。
验证nvl()函数:
select nvl(null,0),nvl(3,0) from dual;
这个时候发现如果为null,那么就将其变为0,如果不是null,则继续使用指定数值。
select empno,ename,job,hiredate,(sal+nvl(comm,0))*12 年薪 from emp;
4.9 nvl2()函数
nvl2()函数是在Oracle 9i之后增加的一个新的功能函数,相比较nvl()函数,nvl2()函数可以同时对null或非null进行不同的判断并返回不同的结果。
查询每个雇员的编号、姓名、年薪、基本工资、奖金。
select empno, ename, nvl2(comm,(comm+sal)*12,sal*12),sal,comm from emp;
4.10 nullif()函数
nullif(表达式一, 表达式二)函数的主要功能判断两个表达式的结果是否相等,如果相等则返回null,不相等则返回表达式一。
验证nullif()函数:
select nullif(1,1), nullif(1,2) from dual;
4.11 decode()函数
decode()函数是Oracle中最有特色的一个函数,decode()函数类似于程序中的if...else if...else,但是判断的内容都是一个具体的值。
decode()函数的语法如下:
decode(列 | 表达式, 值1, 输出结果, 值2, 输出结果,...默认值)
测试decode()函数:
select decode(2,1,'内容为1',2,'内容为2'),decode (2,1,'内容为1','没有满足条件') from dual;
在Java语言之中,if...else判断的是逻辑条件,而在decode()函数中,判断的是数值。
4.12 decode()函数——范例
现在雇员表中的工作有以下几种:CLERK、SALESMAN、MANAGER、ANALYST、PRESIDENT。
要求可以查询雇员的姓名、职位、基本工资等信息,但是要求将所有的职位信息都替换为中文显示。
select ename,job,decode(job,'CLERK','业务员','SALESMAN','销售人员','MANAGER','经理','ANALYST','分析员','PRESIDENT','总裁'),sal from emp;
需要注意的是,如果使用decode()函数进行判断,那么所有的内容都要进行判断,如果有记录未进行判断,那么所有未判断的内容都为null。
4.13 case表达式
case表达式是在Oracle 9i版本引入的,功能与decode()函数有些类似,都是执行多条件判断,不过严格来讲case表达式本身并不属于函数的范畴,它的主要功能是针对于给定的列或者字段进行依次判断,在when中编写判断语句,而在then中编写处理语句,最后如果都不满足,则使用else进行处理。
4.14 case表达式——范例
显示每个雇员的姓名、工资、职位,同时显示新的工资(新工资的标准为:业务员增长10%、销售人员增长20%、经理增长30%、其他职位的人增长50%)
select ename,sal,case job when 'CLERK' then sal*1.1when 'SALSESMAN' then sal * 1.2when 'MANAGER' then sal * 1.3 else sal * 1.5 end 新工资 from emp;
4.15 coalesce()函数
coalesce(表达式1, 表达式2, 表达式3,...表达式n)函数的主要功能是对null进行操作,采用依次判断表达式的方式完成,如果表达式1位null,则显示表达式2的内容,如果表达式2的内容为null,则显示表达式3的内容,以此类推,判断到最后如果还是null,则最终显示的结果就是null。
验证coalesce()函数:
select ename, sal, comm coalesce(comm,100,2000),coalesce(comm,null,null) from emp;
相当于if...else if...else if...else
六、多表查询
对于查询,之前已经学习过了简单查询、限定查询、查询排序,这些都属于SQL的标准语句,在上一章的单行函数,主要功能是为了弥补查询的不足。
而从多表查询开始,就正式的进入到了复杂查询部分。
要求:
多表查询的主要目的。
多表查询的基本实现。
理解笛卡尔积的概念与消除。
1、多表查询的基本语法
1.1 多表查询语法
多表查询就是在一条查询语句中,从多张表里一起取出所需要的数据,如果想要进行多表查询,直接在from子句之后跟上表即可,此时的语法如下:
select [distinct] * | 列名称 [as] [列别名]....from 表名称1, 表名称2... where 条件(s) order by 字段
在之前所编写的所有查询语句中,from子句之后只编写了一个查询表,而多表查询就相当于在from子句之后编写了多个查询表,同时从多个表中获取数据。
下面就将采用emp表和dept表一起进行多表查询,但是在查询之前,首先要做一个操作,那就是先确定emp表和dept表中的数据量分别有多少,可以使用count()函数完成这种操作。
select count(*) from emp;
select count(*) from dept;
可以发现emp和dept两张数据表加在一起才18行记录,那么下面就按照之前给出的语法格式,使用多表查询,当数据量过大时会导致效率问题。
1.2 使用多表查询
select * from emp,dept;
发现此时的结果一共返回了56行记录,那么此时的问题就是笛卡尔积所造成的。
1.3 笛卡尔积
在进行多表连接查询的时候,由于数据库内部的处理机制,会产生一些“无用”的数据,而这些数据就称为笛卡尔积。通过之前的查询可以发现,笛卡尔积返回的56条记录刚好是14 * 4(emp表的记录数 * dept表的记录数)的运算就结果,即,同一条数据重复显示了n次。
可以发现笛卡尔积的出现,会让查询结果变得非常的庞大,如果现在两张表的数据量都很大,那么这种庞大是很可怕的,所以现在必须要想办法消除笛卡尔积。
1.4 消除笛卡尔积
一般而言,如果想要进行笛卡尔积的消除,往往会使用关联字段,利用等值条件来处理笛卡尔积。
由于多张表之间可能会存在重名的字段,所以在进行重名字段访问的时候,前面需要加上表名称,采用“表名称.字段”的方式来进行访问。
select * from emp,dept where emp.deptno = dept.deptno;
这个时候的查询结果可以发现已经消除掉了笛卡尔积,但是这个时候笛卡尔积依然存在,只是不显示了而已。
已经清楚了基本概念之后,下面可以针对数据量做一个分析,在Oracle中存在了sh用户,此用户保存在了PDBORCL插入式数据库之中,可以使用sh用户中的sales表和costs表进行测试。
select count(*) from sh.costs, sh.sales;
一旦开始执行之后,那么这个等待的过程会很长,但是这个时候是显示数据量(包含笛卡尔积的数据量),而后再开始消除,利用等值关联。
返回的数据量:75448036416
虽然消除掉了所有显示的笛卡尔积,但是数据库的原理机制就表示笛卡尔积永远存在,笛卡尔积问题会随着数据量的增大而越发明显。
1.5 小结
多表查询会产生笛卡尔积,所以性能比较差。
多表查询时可以利用等值关联字段消除笛卡尔积。
2、多表查询实例
虽然多表查询本身存在了性能问题,但并不表示多表查询无法使用,而是需要一些更合理的做法来解决多表查询的问题,下面就针对多表查询的使用与分析做一个习题讲解。
2.1 查询每个雇员的编号、姓名、职位、基本工资、部门名称、部门位置信息。
select emp.empno,emp.ename,emp.job,emp.sal,dept.dname,dept.loc from emp,dept where dept.deptno = emp.deptno;
确定需要的数据表:
emp表:查询每个雇员的编号、姓名、职位、基本工资。
dept表:部门名称、部门位置。
确定已知的关联字段:
部门与雇员关联:emp.deptno = dept.depto;
随后还需要按照一个SQL语句的执行步骤编写:from -> where -> select
但是此处会发现一个问题,在上面的程序里面,可以发现采用了表名称访问的列名称,那么如果说现在的表名很长,会影响代码阅读性,所以往往在多表查询的时候为查询的数据表定义别名,而别名也是在from子句中定义的。
select E.empno,E.ename,E.job,E.sal,D.dname,D.loc from emp E,dept D where D.deptno = E.deptno;
2.2 多表查询——范例
查询出每个雇员的编号、姓名、雇佣日期、基本工资、工资等级。
select E.empno,E.ename,E.hiredate,E.sal,S.grade from emp E, salgrade S where E.sal between S.losal and S.hisal;
分析:
emp表:每个雇员的编号、姓名、雇用日期、基本工资。
salgrade表:工资等级。
确定已知的关联字段:
emp.sal between salgrade.losal and salgrade.hisal;
2.3 多表查询——范例
在之前的查询中,发现只是显示了数字1、2、3、4、5,现在希望可以将其替换为中文(如果需要替换功能,肯定使用decode()函数)。
select E.ename,E.job,E.sal,decode(S.grade,1,'E等工资',2,'D等工资', 3,'C等工资', 4,'B等工资', 5, 'A等工资') from emp E, salgrade S where E.sal between S.losal and S.hisal;
以上的练习都是针对于两张表进行的多表查询,而且多表查询中都只使用了一个条件来消除笛卡尔积。
2.4 多表查询——范例
查询出每个雇员的姓名、职位、基本工资、部门名称、工资等级。
select E.ename,E.job,E.sal,D.dname,decode(S.grade, 5, 'E等工资', 4, 'D等工资', 3, 'C等工资', 2, 'B等工资', 1, 'A等工资') from emp E, salgrade S,dept D where E.sal between S.losal and S.hisal and E.deptno = D.deptno;
分析:
确定所需要的数据表:
emp表:每个雇员的姓名、职位、基本工资。
dept表:部门名称。
salgrade表:工资等级。
确定已知的关联字段:
雇员表和部门表:emp.deptno = dept.deptno;
雇员和工资等级:emp.sal between salgrade.losal and salgrade.hisal;
如果现在是多个消除笛卡尔积的条件,那么往往使用and将这些条件连接在一起。
步骤一:查询出雇员的姓名、职位、工资,这一操作只需单张数据表就可以完成。
select ename,job,sal from emp E;
步骤二:加入部门表,肯定需要一个字段与emp表一起消除笛卡尔积。
select E.ename,E.job,E.sal,D.dname from emp E, dept D where E.deptno = D.deptno;
步骤三:加入工资等级表。
现在已经取出三张表的笛卡尔积了,只需要通过一个条件将错误的笛卡尔积去除即可。
select E.ename,E.job,E.sal,D.dname,S.grade from emp E, dept D, salgrade S where E.deptno = D.deptno and E.sal between S.losal and S.hisal;
只要增加一张表,那么就一定需要一个可以消除增加表所带来的笛卡尔积的问题。
2.5 小结
多表查询之中,每增加一个关联表都需要设置一个消除笛卡尔积的条件。
3、表的连接操作
要求:
清楚表的连接操作:内连接、外连接。
对于数据表的连接操作在数据库之中一共定义了两种:
内连接:
也称为等值连接(或称为连接,还可以被称为普通连接或者自然连接),是最早的一种连接方式,内连接是从结果表中删除与其他被连接表中没有匹配的所有行,所以当匹配条件不满足时内连接可能会丢失信息。在之前所使用的连接方式都属于内连接,而在where子句中设置的消除笛卡尔积的条件就是采用了等值判断的方式进行的。
外连接:
内连接中只能够显示等值满足的条件,如果不满足的条件则无法显示,如果现在希望特定表中的数据可以全部显示,就利用外连接,外连接分为三种:左外连接(左链接)、右外连接(右连接)、全外连接(全连接)。
3.1 操作准备——扩充数据
为了更好的观察并理解各个连接方式的区别,那么首先需要在emp表中增加一条数据。(没有部门编号)
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values (8888,'王彦超','MANAGER', 7269,sysdate,8000, 1000,null);
此时增加完的数据是一个没有部门的雇员,即部门编号为null,那么下面就演示等值连接带来的效果。
3.2 使用等值连接
select * from emp E, dept D where E.deptno = D.deptno;
没有部门的雇员没有显示。
所以现在就可以发现,使用内连接只有满足连接条件的数据才会全部显示。可是如果现在希望emp表或者dept表中的数据显示完整,
那么久可以利用外连接进行,而外连接现在主要使用两种:
左外连接:左关系属性 = 右关系属性(+),加号放在了等号的右边,表示左连接。
右外连接:左关系属性 = 右关系属性,放在了等号的左边,表示右连接。
在Oracle中可以利用其提供的"(+)"进行左外连接或右外连接的实现。
3.3 左外连接——范例
显示雇员编号是8888的雇员信息。
select * from emp E, dept D where E.deptno = D.deptno(+);
可以显示雇员编号为8888的雇员信息。
3.4 右外连接——范例。
使用右外连接查询emp表dept表。
select * from emp E, dept D where E.deptno(+) = D.deptno;
因为没有部门编号为40的雇员信息,所以dept.empno = 40这条记录为null。
什么时候使用外连接?
如果所需要的数据信息未显示,那么就使用外连接,而具体是左外连接还是右外连接,没有必要去记,试一试即可。
4、自身关联
要求:
掌握自身关联的实现。
理解外连接在自身关联操作上的使用。
4.1 自身关联——范例
查询出雇员对应的领导信息。
在emp表中存在一个mgr字段,这个字段表示的是雇员的领导。
select E.empno,E.ename,E.mgr,M.empno,M.ename,M.mgr from emp E, emp M where E.empno(+) = M.mgr;
分析:
确定所需要的数据表:
emp表:雇员的编号、姓名。
emp表:领导的编号、姓名。
确定已知的关联字段:
雇员和领导:emp.mgr = memp.empno(雇员的领导编号 = 领导的信息--雇员信息)
步骤一:
直接进行自身连接的操作。
select E.empno, E.ename, M.empno, M.ename from emp E, emp M where E.empno = M.mgr;
现在的表中一共存在了15条记录,但是却只显示了14条记录,等值连接在没有条件满足的时候,是不会显示数据的。
在emp表中的king雇员是没有领导的,所以king的mgr为null,那么这个时候就必须考虑外连接。
步骤二:
使用左外连接:
select E.empno, E.ename, M.empno, M.ename from emp E, emp M where E.mgr= M.empno(+);
对于没有领导信息的雇员,对应的领导信息全部使用null进行表示。
4.2 多表查询——范例
查询出在1981年雇佣的全部雇员的编号、姓名、雇佣日期(按照年-月-日的格式显示)、职位、领导姓名、雇员月工资、雇员年薪(基本工资+奖金)、雇员工资等级、部门编号、部门名称、部门位置,并且要求这些雇员的月基本工资在1500~3000之间,
将最后的结果按照年薪进行降序排列,如果年薪相同,则按照职位进行排序。
select E.empno, E.ename, to_char(E.hiredate, 'yyyy-mm-dd'),E.job, M.ename, E.sal,nvl2(E.comm,(E.comm+E.sal)*12, E.sal * 12) as 年薪,S.grade,decode(S.grade, 1,'E等工资',2,'D等工资',3,'C等工资',4,'B等工资',5,'A等工资') as 工资等级,E.empno,D.dname,D.loc from emp E, emp M, salgrade S, dept D where E.deptno = D.deptno and E.mgr = M.empno(+) and E.sal between S.losal and S.hisal and E.sal between 1500 and 3500 and extract(year from E.hiredate) = '1981' order by 年薪 desc, job;
分析:
确定所需要的数据表:
emp表:编号、姓名、雇用日期、职位、月工资、计算年薪。
emp表:领导姓名。
dept表:部门编号、名称、位置。
salgrade表:工资等级。
确定已知的关联字段:
雇员和领导:emp.mgr = memp.empno;
雇员和部门:emp.deptno = dept.deptno;
雇员和工资等级:emp.sal between salgrade.losal and salgrade.hisal;
步骤一:
查询出所有在1981年雇佣的雇员编号、姓名、雇用日期、职位、月工资、年薪,并且月薪在1500~3500之间,只需要emp一张表即可实现。
select E.empno,E.ename,E.hiredate,E.sal, (E.sal+nvl(E.comm,0))*12 income from emp E where to_char(E.hiredate,'yyyy') = '1981' and E.sal between 1500 and 3500;
步骤二:
加入领导信息,使用自身关联。
select E.empno,E.ename,E.hiredate,E.sal, (E.sal+nvl(E.comm,0))*12 income from emp E, emp M where to_char(E.hiredate,'yyyy') = '1981' and E.sal between 1500 and 3500 and E.mgr = M.empno(+);
步骤三:
加入部门信息。
select E.empno,E.ename,E.hiredate,E.sal, (E.sal+nvl(E.comm,0))*12 income, D,deptno, D.dname, D.loc from emp E, emp M, dept D where to_char(E.hiredate,'yyyy') = '1981' and E.sal between 1500 and 3500 and E.mgr = M.empno(+) and E.deptno = D.deptno;
步骤四:
查询出工资等级。
select E.empno,E.ename,E.hiredate,E.sal, (E.sal+nvl(E.comm,0))*12 income, D,deptno, D.dname, D.loc, S.grade from emp E, emp M, dept D, salgrade S where to_char(E.hiredate,'yyyy') = '1981' and E.sal between 1500 and 3500 and E.mgr = M.empno(+) and E.deptno = D.deptno and E.sal between S.losal and S.hisal;
步骤五:
进行排序。
因为select子句是在order by子句之前执行,所以在select子句之中所定义的别名在order by之中是可以使用的。
select E.empno,E.ename,E.hiredate,E.sal, (E.sal+nvl(E.comm,0))*12 income, D,deptno, D.dname, D.loc, S.grade from emp E, emp M, dept D, salgrade S where to_char(E.hiredate,'yyyy') = '1981' and E.sal between 1500 and 3500 and E.mgr = M.empno(+) and E.deptno = D.deptno and E.sal between S.losal and S.hisal order by income desc, E.job;
通过这一稍微复杂点的题目,可以发现,所有的分析必须要分步进行,而这些分析过程,需要大量的练习才可以巩固。
4.3 小结
自身关联属于一张表自己关联自己的情况,此时依然会产生笛卡尔积。
5、SQL1999语法
要求:
理解交叉连接的作用;
理解自然连接的作用;
理解on子句的使用;
理解using子句的使用;
理解外连接的使用。
为什么会有SQL1999语法?
在之前使用的"(+)"标记只适合在Oracle数据库之中使用,如果是其他数据库,则无法使用。
但是大部分数据库都是支持SQL1999语法。
SQL1999语法:
select [distinct] * | 列名称[as][列别名]....from 表1 表1别名[cross join 表2 表2别名]
[natural join 表2 表2别名] | [join 表2 using(关联列名称)] | [join 表2 on(关联条件)] | [left | right | full outer join 表2 on(关联字段)] [where 条件(s)] [order by 排序的字段1 asc | desc, 排序的字段2 asc | desc...];
5.1 交叉连接
交叉连接(cross join)作用于两个关系上,并且第一个关系的每个元组与第二个关系的所有元组进行连接,这样的操作形式与笛卡尔积是完全相同的,交叉连接的语法如下所示:
select [distinct] * | 列名称 from 表1 [cross join 表2] where 条件(s)
select * from emp cross join dept;
交叉连接的主要功能就是产生笛卡尔积。
一般而言,在进行多表连接的时候都会存在关联字段以消除笛卡尔积,而关联字段的名称一般都会一样,如果不一样,也会有部分相同,现在讨论的是完全一样的情况,例如deptno字段就是相同的,可以利用自然连接来消除这个笛卡尔积。
5.2 自然连接
自然连接(natural join)运算作用于两个关系,最终会通过两个关系产生出一个关系作为结果,与交叉连接(笛卡尔积)不同的是,自然连接只考虑那些在两个关系模式中都出现的属性上取值相同的元组对,自然连接的操作语法如下:
select [distinct] * | 列名称 from 表1 [natural join 表2] where 条件(s)
select * from emp natural join dept;
这个时候会把链接的字段放到第一列进行显示,这种方式就是内连接的一种方式。
此时没有部门的雇员未出现。
5.3 using子句
通过自然连接可以直接使用关联字段消除笛卡尔积,那么如果现在的两张表中没有存在这种关联字段的话,就可以使用using子句完成笛卡尔积的消除,using子句的语法如下所示:
select [distinct] * | 列名称 from 表1 join 表2 using(关联列名称)
select * from emp join dept using(deptno);
当表2中无指定字段时,会报错。
5.4 on子句
在编写等值连接时,采用了关键字段进行笛卡尔积的消除,那么用户在SQL:1999语法之中通过on子句就可以由用户手动设置一个关联条件,on子句语法如下:
select [distinct] * | 列名称 from 表1 join 表2 on(关联条件) where 条件(s)
using是设置连接字段,而on是设置连接条件。
select * from emp E join salgrade S on(E.sal between S.losal and S.hisal);
5.5 外连接
在数据库的查询操作中的外连接一共分为三种形式:左外连接、右外连接、全外连接,而此时连接的语法如下:
select [distinct] * | 列名称 from 表1 [left | right | full outer join 表2 on(关联条件)] where 条件(s);
对于外连接,在之前使用的是"(+)"来完成的,这个标记只能够实现左外连接或者是右外连接,但是对于全外连接无法使用,而全外连接只能够依靠SQL:1999语法中规定的内容来完成。
5.6 右外连接
select * from emp E right outer join dept D on(E.deptno = D.deptno);
右外连接以右表为主,所以部门表信息全部显示。
5.7 左外连接
select * from emp E left outer join dept D on(E.deptno = D.deptno);
左外连接以左表为主,所以雇员表信息全部显示。
5.8 全外连接
select * from emp E full outer join dept D on(E.deptno = D.deptno);
部门信息和雇员信息全部显示。
通过以上的分析可以发现,给出的所有语法里,只有全外连接是必须通过SQL:1999语法来实现的,但是对于全外连接,使用的情况并不多。
建议:如果使用的是Oracle数据库,就使用"(+)"标记来控制左右连接,不使用它实现内连接。
5.9 小结
交叉连接会产生笛卡尔积。
自然连接可以自动匹配关联字段来消除笛卡尔积。
如果要实现全外连接只能够依靠SQL:1999语法。
SQL:1999语法能不用就不用。
6、数据的集合运算
数据的集合操作是对查询结果的操作。
要求:
理解数据的集合操作:union、union all、intersect、minus
6.1 集合运算
集合运算时一种二目运算符,一共包括四种运算:并、差、交、笛卡尔积,其中对于笛卡尔积在之前已经了解过,所以本次主要是看并、交、差三种操作,操作集合的语法如下所示:
查询语句
[union | union all | intersect | minus]
查询语句
.....
要实现集合的运算,主要使用四种运算符:
union(并集):返回若干个查询结果的全部内容,但是重复元组不显示。
union all(并集):返回若干个查询结果的全部内容,重复元组也会显示。
minus(差集):返回若干个查询结果中的不同部分。
intersect(交集):返回若干个查询结果中相同的部分。
6.2 并集操作
并集操作是将多个查询的结果连接到一起,而对于并集操作提供了两种操作符:
union(不重复显示)
union all(重复显示)
分析:
select * from dept;
这个查询会返回四行记录。
select * from dept where deptno = 10;
这个查询会返回一行记录。
这个时候两个查询结果返回的列的结构相同,下面使用union连接:
select * from dept
union
select * from where deptno = 10;
这时候只返回四行记录,因为第一个查询已经包含了第二个查询的内容,所以重复数据就不显示了,如果想要显示重复的数据,可以使用union all进行操作。
提示:
在以后进行查询操作编写过程中,尽量使用union或union all来代替or。
范例:
查询所有销售人员和业务员的信息。
select * from emp where job = 'SALESMAN' or job = 'CLERK'
或者:select * from emp where job in('SALESMAN','CLERK');
改为union操作:
select * from emp where job = 'SALESMAN' union select * from emp where job = 'CLERK';
这样写相当于进行了两个单表查询,单表查询性能相对较高。
6.3 差集操作
使用minus进行差集操作。
select * from dept minus select * from dept where deptno = 10;
6.4 交集操作
使用intersect执行交集操作。
select * from dept intersect select * from dept where deptno = 10;
6.5 小结
开发之中建议使用union来代替or操作。
集合操作时,各个查询语句返回的结构要求一致。
七、分组统计查询
要求:掌握各个统计函数的使用。
1、统计函数
在之前使用过count()函数,此函数的功能是可以取得一张表中的全部数据量,而这种函数在数据库之中就将其定义为统计函数,有些地方也将其称为分组函数。
统计函数:
count(* | [distinct] 列) 求出全部的记录数。
sum(列) 求出总和,操作的列是数字。
avg(列) 求平均值。
max(列) 求最大值。
min(列) 求最小值。
median(列) 返回中间值。
variance(列) 返回方差。
stddev(列) 返回标准差。
给出了八个统计函数,但是从SQL的标准规定来讲,只有5个是标准函数:count() sum() avg() max() min()
1.1 统计函数——范例
查找出公司每个月支出的月工资的总和。
select sum(sal) from emp;
分析:求和使用sum()函数,工资使用sal列。
1.2 统计函数——范例
查询出公司的最高工资、最低工资和平均工资。
select max(sal), min(sal), avg(sal) from emp
1.3 统计函数——范例
统计出公司最早雇佣和最晚雇佣的雇用日期。
select min(hiredate), max(hiredate) from emp;
针对于雇用日期的查询肯定是用hiredate字段,在Oracle中的函数是可以进行数据类型的互相转换的。
最早雇佣的hiredate的值一定是最小的,最晚雇佣的hiredate的值一定是最大的。
1.4 统计函数——范例
统计公司工资之中的中间值。
select median(sal) from emp;
分析:
例如现在有三个数字:2000、3000、2500,所谓的中间值就是2500。
1.5 统计函数——范例
统计工资的标准差与方差。
select stddev(sal) 标准差, variance(sal) 方差 from emp;
1.6 统计函数——范例
统计出公司的雇员人数。
select count(*), count(empno), count(comm) from emp;
分析:
对于count()函数而言,是最早使用的函数,count()函数之中的参数可以使用*,也可以使用字段。
现在empno字段上是不存在null值的。
1.7 统计函数——范例
验证count(*)、count(字段)、count(distinct 字段)的使用区别。
select count(*), count(ename), count(comm), count(distinct job) from emp;
分析:
对于count()函数,可以传递三类参数:*、字段、distinct 字段。
面试题:
请问count(*),count(字段),count(distinct 字段)有什么区别?
在使用count(字段)的时候,如果列上存在了null,那么null是不会进行统计的,例如count(comm)。
在使用count(distinct 字段)的时候,如果有重复的记录,也不会统计。
在使用count(*)是最方便的,但是在开发时建议使用字段,避免使用*。
在所有的统计函数中,只有count()函数可以在表中没有任何数据的时候依然返回内容,所有函数在没有数据的时候返回的都是null,而count()函数返回的是数字0,所以count()函数永远会返回数据,而这个问题也就相当于解决了JavaEE开发之中编写DAO时,取得数据个数不用if判断的原因所在了。
1.8 小结
五个核心的统计函数:count() avg() sum() min() max()
2、单字段分组统计
对于统计函数而言,单独使用的情况一定是有的,例如:在做报表显示的时候基本的分页操作,一定需要查询出全部的数据量。
要求:
掌握group by子句的使用。
掌握分组操作的使用限制。
什么时候需要分组?
对于分组这个概念在生活中往往会出现以下的需求:
需求一:在一个班级之中,要求男女各一组进行辩论赛。
需求二:在公司中,要求每个部门一组进行拔河比赛。
对于以上的两个需求,假设存在学生表,那么在学生表之中一定会存在一个性别的字段,而每一个部门的数据,其性别内容一定是相同的。而在公司之中,如果要进行部门的分组,肯定是需要有一个部门列的内容存在重复(部门,10部门,20部门)。
可以直接查看emp表之中的全部数据,以确定是否存在可以分组的字段。
select * from emp;
此时的查询结果之中,job和deptno字段都出现了重复的内容。虽然在大部分情况下(正常情况)都允许在重复数据的列上实现分组,但是也允许一条数据一组。
2.1 分组统计语法
select [distinct] 分组字段 | 统计函数 from 表1 where 条件(s) group by 分组字段 order by 排序字段
分组使用group by子句,但是此时select子句里允许出现的就是分组字段和统计函数,这些在讲解分组限制的时候再进行讨论。
2.2 分组统计——范例
统计出每个部门的人数。
select deptno,count(*) from emp group by deptno;
分析:
此时一定需要按照部门的信息分组,在emp表中,每个雇员的部门都使用一个部门编号来表示,那么就可以针对于deptno字段来实现分组统计。
2.3 分组统计——范例
统计出每种职位的最低和最高工资。
select job,min(sal), max(sal) from emp group by job;
分析:
职位的信息统计,那么肯定按照job的字段实现分组,而后统计的函数肯定是max()和min()。
以上的两个基本范例就实现了分组的基本操作,而且这些代码都按照标准格式进行了编写。
可是在分组之中,最麻烦的地方就在于分组操作的若干个限制。
2.4 分组注意事项
1)如果没有group by子句,则在select子句之中只允许出现统计函数,其他任何字段都不允许出现。
错误:select deptno, count(empno) from emp;
正确:select count(empno) from emp;
2)在统计查询之中,select子句后只允许出现分组字段和统计函数,而其他的非分组字段不能使用。
错误:select deptno,ename,count(empno) from emp group by deptno;
正确:select deptnom count(empno) from emp group by deptno;
原则:在进行分组操作的时候,只有在group by子句之中出现的字段才是在select子句中允许出现的字段,如果没有在group by中出现,那么select子句中也不允许出现。
3)统计函数允许嵌套使用,但是嵌套统计函数之后的select子句之中不允许再出现任何的字段,包括分组字段。
错误:select deptno,max(avg(sal)) from emp group by deptno;
正确:select max(avg(sal)) from emp group by deptno;
见范例。
2.5 分组统计——范例
求出每个部门平均工资最高的工资。
分析:
按照部门分组,然后统计出每个部门的平均工资数值,那么针对于这些统计的结果求出一个最大的记录。
错误代码:
select deptno, avg(sal) from emp group by deptno;
此时计算出来的是每个部门的平均工资,可是现在要求是统计出最高的平均工资。
select deptno,max(avg(sal)) from emp group by deptno; // ORA:00937:不是单组分组函数。
此时因为select子句之中存在了deptno的字段,所以这个时候就出现了错误。
正确代码:
select max(avg(sal)) from emp group by deptno;
2.6 分组统计——范例
查询每个部门的名称、部门人数、部门平均工资、平均服务年限。
分析:
平均服务年限需要计算出年的概念,可以使用months_between()函数,但是在这个查询里面肯定需要不止一张表。
1)确定所需要的数据表:
emp表:部门人数、平均工资、平均服务年限,这些需要通过统计函数进行计算。
dept表:部门名称。
2)确定已知的关联字段:
emp表与dept表关联:emp.deptno = dept.deptno
步骤一:将dept表和emp表一起进行查询,暂时不进行分组操作。
查询每个部门的名称、雇员编号、工资、雇用日期。
步骤二:观察现在的dname字段(查询结果,理解为临时表),既然重复的的列就可以进行分组。
一旦出现分组之后,那么未分组的字段内容就要变更了,变为一条记录,也就是说要出现分组字段和统计函数。
select D.dname, count(E.empno), round(avg(months_between(sysdate,E.hiredate)/12),2), round(avg(E.sal),2) from emp E, dept D where E.deptno = D.deptno group by D.dname;
注意:必须使用avg()函数来计算hiredate,因为使用group by子句之后,必须使用分组字段和聚合函数。
步骤三:此时出现的信息只包含了三个部门的信息,此时需要加入外连接来显示40部门的信息。
select D.dname, count(empno), round(avg(E.sal),2), round(avg(months_between(sysdate,E.hiredate)/12),2) from emp E, dept D where D.deptno = E.deptno(+) group by D.dname;
学到此处应该清楚的认识到group by子句的使用,那么既然有了group by子句,也就有了一个新的子句执行顺序:
from --> where --> group by --> select --> order by
2.7 分组统计——范例
查询出公司各个工资等级雇员的数量、平均工资。
select S.grade, count(empno),round(avg(E.sal),2) from emp E, salgrade S where E.sal between S.losal and S.hisal group by S.grade;
分析:
确定所需要的数据表:
emp表:雇员的数量、平均工资的统计结果。
salgrade表:工资等级信息。
确定已知的关联字段:
雇员与工资等级:emp.sal between salgrade.losal and salgrade.hisal;
步骤一:将需求更改,使用salgrade表和emp表进行关联查询,查询出等级编号、雇员编号和工资。
select S.grade,E.empno, E.sal from salgrade S, emp E where E.sal between S.losal and S.hisal;
步骤二:既然grade字段上有了重复的数据信息,那么就可以继续针对于临时表数据实现分组。
select S.grade, count(empno),round(avg(E.sal),2) from emp E, salgrade S where E.sal between S.losal and S.hisal group by S.grade;
以上的两个范例是针对于多表查询后的数据进行统计,其实是根据返回结果(临时表)进行分组。
只要是行和列的组成结果一定是临时表。
2.8 分组统计——范例
统计出领取佣金与不领取佣金的雇员的平均工资、平均雇佣年限、雇员人数。
select '领取佣金', round(avg(sal),2) 平均工资, round(avg(months_between(sysdate,hiredate)/12),2) 平均年限, count(empno)
如果看到此范例要求,很明显首先应该想到的是使用comm字段进行分组。
group by comm;
但是并没有所谓的通过comm字段进行分组,而是按照每一种可能出现的佣金数值来进行的分组操作。
下面需要更换一种思路:
首先查询出所有领取佣金的雇员信息。
select '领取佣金', round(avg(sal),2) 平均工资, round(avg(months_between(sysdate,hiredate)/12),2) 平均年限, count(empno)from emp where comm is not null
然后查询出所有不领取佣金的雇员信息。
select '领取佣金', round(avg(sal),2) 平均工资, round(avg(months_between(sysdate,hiredate)/12),2) 平均年限, count(empno)from emp where comm is null
以上的两个查询结果的返回列形式完全相同,可以使用union联合查询。
拿到题目之后,一定要分析一下,不要按照习惯性的方式进行分组操作,并不是所有的分组统计都需要group by子句。
2.9 小结
利用group by子句可以设置分组。
select子句在分组操作中的限制。
3、多字段分组统计
在进行字段分组的时候不管是单表取数据,还是多表查询,那么在一个列上一定会存在重复记录。
多字段分组对于单字段分组,本质上讲没有区别,也就是说若干个列上的数据同时存在重复,此时才需要多字段分组。
要求:
在group by子句中使用多个字段进行分组实现。
语法:
select [distinct] 分子字段1, 分组字段2.... from 表1,表2 where 条件(s) group by 分组字段1, 分组字段2
既然可以在group by子句中出现多个分组字段,那么在select子句中也一定可以定义多个分组字段的查询显示。
3.1 分组统计——范例
查询每个部门的详细信息,包括部门编号、部门名称、部门地址、部门人数、部门平均工资、部门工资总和、最高工资和最低工资。
select D.deptno 部门编号, D.dname 部门名称, D.loc 部门地址, count(E.empno) 部门人数, round(avg(nvl(sal,0))) 平均工资, sum(nvl(sal,0)) 工资总和, max(nvl(sal,0)) 最高工资, min(nvl(sal,0)) 最低工资 from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno,D.dname,D.loc;
分析:
既然现在要统计每个部门的信息,那么一定要包含:部门编号、部门名称、部门位置,部门人数、平均工资、总工资、最高工资、最低工资。
现在肯定不能只依靠一张表来完成,因为部门信息一定是dept表,而雇员的信息记录在emp表。
确定所需要的数据表:
dept表:部门编号,部门名称,部门位置。
emp表:统计出平均工资,总工资,最高工资,最低工资,和部门人数。
确定已知的关联字段:
雇员和部门:emp.deptno = dept.deptno;
步骤一:将题目的要求转换,将emp表和dept表关联,查询出部门编号,部门名称,部门位置,雇员编号和姓名。
select D.deptno, D.dname, D.loc, E.empno, E.ename from emp E, dept D where D.deptno = E.deptno
可以发现deptno, dname, loc三个字段出现了重复数据,既然列上的信息重复,就一定具备了分组的条件。
步骤二:使用多字段分组,同时实现统计信息。
select D.deptno, D.dname, D.loc, count(E.empno) count, round(avg(E.sal),2) avg, sum(E.sal) sum, max(E.sal) max, min(E.sal) min from emp E, dept D where E.deptno = D.deptno group by D.deptno, D.dname, D.loc;
步骤三:部门一共有四个部门,并且现在要求列出所有部门的统计信息,所以必须使用外连接。
步骤四:因为40部门没有雇员信息,所以某些结果就是null,使用nvl函数进行处理。
select D.deptno, D.dname, D.loc, count(E.empno) count, round(avg(nvl(E.sal,0)),2) avg, sum(nvl(E.sal,0)) sum, max(nvl(E.sal,0)) max, min(nvl(E.sal,0)) min from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno, D.dname, D.loc;
3.2 小结
多字段分组是group by定义多个字段,并且多个字段必须同时重复。
4、having子句
在之前学习了关于查询组成的相关子句,而having子句是这些子句之中的最后一个,与where非常相似。
要求:
掌握having子句的使用。
理解having子句和where子句的区别。
使用group by子句可以实现数据的分组显示,但是在很多时候往往需要对分组之后的数据进行再次的过滤,例如:要求选出部门人数超过5个人的部门信息,这样的操作肯定是先要通过部门进行分组统计,然后再使用统计结果进行数据的过滤,而要想实现这样的功能就只能通过having子句来完成。
语法:
select [distinct] 分组字段1 [分组字段2..] from 表1 where 条件(s) group by 分组字段1 [,分组字段2] having 过滤条件(s)
注意:
having子句必须和group by子句一起使用。
having子句和group by子句前后顺序不重要,因为有子句执行顺序。
所有子句的执行顺序:
from --> where --> group by --> having --> select --> order by;
4.1 分组统计——范例
查询出所有平均工资大于2000的职位信息、平均工资、雇佣人数。
select job,round(avg(sal)),count(empno) from emp -- where avg(sal) > 2000 group by job having avg(sal) > 2000
需要注意的是:where子句中不能包含聚合函数。
分析:
首先不关心平均工资是否大于多少,只按照职位分组后进行统计。
select job, round(avg(sal)),count(empno) from emp group by job;
现在希望可以对分组后的数据进行过滤,如果现在使用where是不可能的,因为where在group by子句之前,并且where子句中不允许使用聚合函数。
4.2 分组统计——范例
列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、和最高工资。
select D.deptno, D.dname,round(avg(sal)),min(sal),max(sal) from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno,D.dname having count(*) > 1
分析:
确定所需要的数据表:
emp表:部门编号、名称。
dept表:统计信息。
确定已知的关联字段:
雇员与部门关联:emp.empno = dept.deptno;
步骤一:将emp表与dept表关联查询。
select D.deptno, D.dname, E.empno, E.sal from emp E, dept D where E.deptno = D.deptno
步骤二:现在部门名称和部门编号出现了重复,可以通过这两个字段进行分组查询。
select D.deptno, D.dname, round(E.sal), min(E.sal), max(E.sal) from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno, D.dname;
步骤三:需要针对分组后的结果进行筛选(人数大于1)
select D.deptno, D.dname, round(E.sal), min(E.sal), max(E.sal) from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno, D.dname having count(E.empno) > 1;
注意:having在select子句之前执行,所以having子句中不能使用select别名。
having和where的区别:
where:在分组之前使用,不允许使用聚合函数。
having:在分组之后使用(必须结合group by),允许使用聚合函数。
4.3 分组统计——范例
显示非销售人员工作名称以及从事同一工作雇员的月工资的总和,并且要满足从事同一工作的雇员的月工资合计大于5000,输出结果按月工资的总和升序排序。
select job, sum(sal) sum from emp where job != 'SALESMAN' group by job having sum(sal) > 5000 order by sum;
分析:
步骤一:显示所有非销售人员的工作名称。
select distinct job from emp where job != 'SALESMAN';
步骤二:发现需要对数据进行统计,统计月工资总和,使用sum函数。
select job, sum(sal) sum from emp where job != 'SALESMAN' group by job
步骤三:针对于分组之后的工资总和进行筛选。
select job, sum(sal) sum from emp where job != 'SALESMAN' group by job having sum(sal) > 5000
步骤四:按照月工资进行升序排序,而order by子句是最后执行的,所以order by子句可以使用select别名。
select job, sum(sal) sum from emp where job != 'SALESMAN' group by job having sum(sal) > 5000 order by sum;
4.4 小结
having子句是在分组之后进行使用的,主要是为了针对分组的结果进行过滤。
八、子查询
首先对于SQL查询语言而言,已经学习了完整的操作语法,而子查询之中所讲解的语法格式并没有任何的新技术,或者说子查询感觉上跟Java的内部类是很相似的。
子查询就是指在一个完整的查询语句之中,嵌套若干个不同功能的小查询,从而一起完成一个复杂查询的一种编写形式。
复杂查询 = 限定查询 + 多表查询 + 统计查询 + 子查询。
复杂查询也是在笔试之中出现较多的部分。
1、简单子查询
1.1 子查询——范例
查询公司之中工资最低的雇员的完整信息。
select * from emp where sal = (select min(sal) from emp)
分析:
步骤一:
公司一定会存在最低工资,如果想要知道最低,需要使用min()函数。
select min(sal) from emp;
现在相当于知道了最低工资是800这个数据,如果说现在换一个思路,要求查询出工资是800的雇员,此类查询只需要在where子句之中设置一个条件即可,利用sal字段进行判断。
步骤二:因为此时不可能预先知道最低工资就可以把上面的800换为之前的min(sal)查询。
select * from emp where sal = (select min(sal) from emp;
子查询就是在一个完整的查询之中定义了若干个小的查询所形成的的复杂查询,在编写子查询的时候一定要使用( )标记。
1.2 子查询返回的结果
子查询可以返回的数据类型一共分为四种:
单行单例:返回的是一个具体列的内容,可以理解为一个单值数据。
单行多列:返回一行数据中多个列的内容。
多行单列:返回多行记录中同一列的内容,相当于给出了一个操作范围,可以使用in。
多行多列:查询返回的结果是一张临时表。
1.3 子查询语法:
1)select中
select (select 字段1,字段2..from 表 where 条件(s)) from 表 where 条件(s)
2)from中
select 字段 from (select 字段1,字段2 from 表)
3)where中
select 字段1, 字段2 from 表 where 条件(s) (select 字段1, 字段2... from 表);
4)having中
select 分组字段1, 分组字段2... from 表 where 条件(s) group by 分组字段1, 分组字段2... having 条件(s) (select 字段1, 字段2.. from 表);
1.4 子查询的常见操作
where子句:此时自查询返回的结果一般都是单行单列、单行多列、多行单列。
having子句:此时子查询返回的结果都是单行单列数据,为了使用统计函数操作。
from子句:此时子查询返回的结果一般都是多行多类,可以按照一张临时表的形式进行操作。
虽然子查询以where、having、from为主,但是select中也可以出现。
1.5小结
一个查询语句内部可以定义多个子查询。
子查询一般在where、from、having子句中出现较多。
2、where子查询
要求:
可以在where子句中处理单行单列子查询、多行单列子查询、单行多列子查询。
2.1 子查询返回单行单列数据
如果子查询返回的是单行单列的数据,那么子查询所得到的就是一个数值。
查询出基本工资比ALLEN低的全部雇员信息。
select * from emp where sal < ( select sal from emp where ename = 'ALLEN');
分析:
步骤一:首先找到ALLEN的工资
select sal from emp where ename = 'ALLEN';
此时返回的是单行单列的数值。
步骤二:在where子句中使用子查询
select * from emp where sal < (select sal from emp where ename = 'ALLEN');
2.2 子查询——范例
查询基本工资高于公司平均薪水的全部雇员信息。
select * from emp where sal > (select avg(sal) from emp)
分析:
步骤一:需要知道公司的平均薪水,使用avg()函数。
select avg(sal) from emp;
步骤二:需要知道那些雇员的工资高于之前的查询结果(平均工资)
select * from emp where sal > (selest avg(sal) from emp);
2.3 子查询——范例
查找出于ALLEN从事同一工作,并且基本工资高于雇员编号为7521的全部雇员信息。
select * from emp where job = (select job from emp where ename = 'ALLEN') and sal > (select sal from emp where empno = 7521);
分析:
步骤一:找到ALLEN的工作
select job from emp where ename = 'ALLEN';
步骤二:找到7521的工资
select sal from emp where empno = 7521;
步骤三:判断职位和工作。
select * from emp where job = (select job from emp where ename = 'ALLEN') and sal > (select sal from emp where empno = 7521);
单行单列子查询返回的就是一个数值。
2.4 子查询返回单行多列数据
查询与SCOTT从事同一工作并且工资相同的雇员信息。
select * from emp where (job,sal) = (select job,sal from emp where ename = 'SCOTT') and ename != 'SCOTT';
需要注意的是,比较字段顺序不能颠倒。
分析:
步骤一:首先要找到SCOTT的工作以及工资。
select job, sal from enp where ename = 'SCOTT';
步骤二:既然返回的是单行两列的数据,那么就可以在where中使用这两个字段。
select * from emp where (job,sal) = (select job, sal from emp where ename = 'SCOTT');
步骤三:清楚SCOTT,只需要增加一个过滤条件即可。
select * from emp where (job,sal) = (select job, sal from emp where ename = 'SCOTT') and ename != 'SCOTT';
2.5 子查询——范例
查询与雇员7566从事同一工作并且领导相同的全部雇员信息。
select * from emp where (job,mgr) = (select job,mgr from emp where empno = 7566) and empno != 7566;
分析:
步骤一:找到7566的工作和领导 。
select job, mgr from emp where empno = 7566;
步骤二:继续判断信息。
select * from emp where (job, mgr) = (select job, mgr from emo where empno = 7566) and empno != 7566;
2.3 子查询——范例
查询与ALLEN从事同一工作并且雇佣时间为同一年的全部雇员信息。
select * from emp where (job,extract(year from hiredate)) = (select job, extract(year from hiredate) from emp where ename = 'ALLEN') and ename != 'ALLEN';
分析:
步骤一:查询ALLEN的工作和雇佣日期。
select job, hiredate from emp where ename = 'ALLEN';
步骤二:继续判断雇佣年分和工作。
select * from emp where (job, extract(year from hiredate) = (select job, extract(year from hiredate) from emp where ename = 'ALLEN') and ename != 'ALLEN';
2.4 子查询返回多行单列的数据。
在使用多行子查询时,主要使用三种操作符:in any all。
in操作符:
在之前所学习过的限定查询之中已经使用过in操作符了,主要是设置范围,也就是说如果子查询返回的是多行单列数据,就相当于定义了数据的查询范围,既然是范围的查询,就需要使用in或not in操作符了。
2.5 子查询——范例
查询出每个部门中工资最低的全部雇员信息。
select * from emp where sal in (select min(sal) from emp group by deptno);
分析:
步骤一:按照部门分组,统计出每个部门的最低工资。
select min(sal) from emp group by deptno;
步骤二:使用in进行范围查询。
select * from emp where sal in (select min(sal) from emp group by deptno);
2.6 子查询——范例
查询出与每个部门中工资不是最低的全部雇员信息。
select * from emp where sal not in (select min(sal) from emp group by deptno);
分析:
相当于对上一个结果进行求反操作。
既然说到了in以及not in的操作,那么就有一点需要注意,关于null的问题,如果在in之中自查询返回的数据有null,那么不会影响查询,但是如果在not in之中自查询返回的数据包含null,那么就不会返回任何的数据。
select * from emp where mgr not in (select mgr from emp);
not in表示不在此范围中,所以因为mgr包含null,所以不会返回任何数据。
2.7 any操作符
any操作符有如下三种使用形式:
= any:表示与子查询中的每个元素进行比较,功能与in类似。(等于任何一个)(<> any 不等价与not in)
> any:比子查询中返回结果的最小值要大。(大于任意一个)(包含了>= any)
< any:比子查询中返回结果的最大值要小。(小于任意一个)(包含了<= any)
2.8 子查询——范例
查询每个部门经理的最低工资(假设每个部门有多个经理)
使用= any操作符完成查询。
select * from emp where sal = any (select min(sal) from emp where job = 'MANAGER' group by deptno);
= any表示匹配其中任意一个值。
如果此时使用了<> any,则表示表中的数据全部返回了,无意义。
2.9 子查询——范例
使用>any操作符完成查询,>any表示比子查询的最小值要大。
select * from emp where sal > any(select min(sal) from emp where job = 'MANAGER' group by deptno);
2.10 子查询——范例
使用
2.11 some操作符
在Oracle中(SQL之中),some和any的功能是相同的,这是后来添加的。
2.12 all操作符
all操作符有以下三种用法:
<>all:等价于not in。(全部不等于)(=all并不等价于in)。
>all:比子查询中最大的值还要大。(大于全部)
2.13 子查询——范例
使用<>all操作符完成查询。
查询每个部门中的经理工资不是最低工资的雇员信息。
select * from emp where sal != all(select min(sal) from emp where job = 'MANAGER' group by deptno);
这个功能和not in是完全一样的,可是如果使用的是=all,是没有数据返回的。
2.14 子查询——范例
使用>all操作符完成查询(大于全部子查询返回的数据)
select * from emp where sal > all(select min(sal) from emp where job = 'MANAGER' group by deptno);
2.15 子查询——范例
使用
总结:
对于in操作符,了解in和not in就可以了。
any操作符:
* =any:功能与in相同
* >any:表示比子查询中返回的最小值要大。
*
* !=all:功能与not in相同
* >all:比子查询中返回的最大值要大。
*
2.16 空数据判断
在SQL之中提供了一个exists结构用于判断子查询是否有数据返回,如果子查询中有数据返回,则exists结构返回true,反之返回false。
结构:
select * from emp where exists(select * from emp where empno = 9999);
此时由于不存在9999编号的雇员,所以在这个地方exists()判断返回的就是false,就不会有全部的结果返回了。
如果现在有结果返回,也就是说子查询有内容,exists结构满足,数据就会返回。
2.17 子查询——范例
使用not exists。
select * from emp where not exists(select * from emp where empno = 9999);
对exists求反。
2.18 小结
where子句可以判断单个数值、多个数值。
使用in、any、all可以处理多行单列的子查询。
利用exists()可以判断查询结果是否为null。
3、having子句中的子查询
having子句一定是结合group by子句一起使用的,其主要的目的是进行分组后数据的再次过滤,与where子句不同的是,having子句在分组后可以使用统计函数,而where是在分组前,不能使用统计函数。
要求:
掌握having子句使用子查询的形式。
一般而言在having子句中出现子查询,子查询返回的数据往往是单行单列的,它是按照一个数值的方式返回,再通过统计函数进行过滤。也就是说,因为having子句中可以使用统计函数,而统计函数中需要一个参数,所以子查询返回的单行单列的数值可以当做统计函数的参数使用。
3.1 子查询——范例
查询部门编号、雇员人数、平均工资,并要求这些部门的平均工资高于公司平均薪资。
select deptno,count(empno),round(avg(sal)) from emp group by deptno having round(avg(sal)) > (select round(avg(sal)) from emp);
分析:
步骤一:查询出公司的平均薪水。
select round(avg(sal)) from emp;
步骤二:按照deptno字段进行分组,并且统计部门的信息。
select deptno, count(empno), avg(sal) from emp group by deptno;
步骤三:使用having子句执行分组后的数据过滤,所以需要在having子句中执行子查询。
select deptno, count(empno), round(avg(sal)), from emp group by deptno having avg(sal) > (select avg(sal) from emp);
3.2 子查询——范例
查询出每个部门平均工资最高的部门名称及平均工资。
select D.dname,round(avg(sal)) from emp E, dept D where E.deptno = D.deptno group by D.dname having avg(sal) = (select max(avg(sal)) from emp group by deptno);
分析:
如果是最高的平均工资,那么肯定使用统计函数的嵌套来完成,在统计函数嵌套使用的时候,select子句中是不允许出现任何的字段,包括分组字段。
步骤一:求出平均工资最高的工资。
select max(avg(sal)) from emp;
步骤二:现在已经知道了最高的平均工资,但是需要知道部门名称,所以需要使用部门表。
3.3 小结
在having子句中使用子查询,子查询返回的都是单行单列数据,同时也可以在having中利用统计函数进行判断。
4、在from子句之中使用子查询
from子句的主要功能是确定数据的来源,那么来源都是数据表,表的特征是:行 + 列的集合,只要是在from子句之中出现的内容一般都是多行多列的子查询返回的内容,
要求:
掌握from子句中子查询的使用。
4.1 子查询——范例
要求查询出每个部门的编号、名称、位置、部门人数、平均工资。
在之前学习分组统计的时候学习过多字段分组操作,当时的基本实现如下:
select D.deptno, D.dname, D.loc, count(E.empno), round(avg(E.sal)) from emp E, dept D where E.deptno(+) = D.deptno group by D.deptno,D.dname, D.loc;
但是除了以上做法之外,现在还有另外一种做法,那就是使用子查询完成。
分析:
步骤一:查询出每个部门的基本信息,只需要查询dept表即可。
select * from dept;
步骤二:统计信息,按照部门编号分组统计。
select deptno, count(empno), avg(sal) from emp group by deptno;
注意:在子查询中,统计函数必须使用别名。
select deptno dno, count(empno) count, round(avg(sal)) avgsal from emp group by deptno;
步骤三:
第一个步骤返回的是dept的信息,第二个步骤是部门的统计结果,现在可以发现,将第一个步骤的结果和第二个步骤的结果相结合就可以得到最终结果,而这个时候的结合一定是属于表的结合,只不过一个是dept实体表,另一个是统计的查询结果,是一个临时表。
select D.deptno, D.dname, D.loc, temp.count, temp.avg from dept D, (select deptno dno, count(empno) count, cound(avg(sal)) avg from emp group by deptno) temp where D.deptno = temp.dno(+);
问题:两种操作都可以实现同样的效果,那么使用哪种操作呢?
为了解决此问题,可以将数据扩大一百倍,即emp表中的数据为1400条记录,dept表中的数据为400条记录。
实现一:多字段分组。
当dept和emp表关联的时候一定会存在笛卡尔积,此时数据量为1400*400 = 560000条记录。
实现二:子查询。
* 统计:emp表的1400条记录,而且最终的统计结果的行数不可能超过400行(因为dept表只有400条)。
* 多表关联:dept表的400行记录 * 子查询的400条记录 = 160000条记录。
* 最终结果:160000 + 1400 = 161400条记录。
使用子查询实际上是解决多表查询所带来的性能问题,所以在开发之中一定会大量使用子查询。
4.2 子查询——范例
查询出所有在部门“SALES”工作的员工的编号、姓名、基本工资、奖金、职位、雇用日期、部门的最高和最低工资。
select empno, ename, sal, comm, job, hiredate, temp.max, temp.min from emp E, (select deptno dno, max(sal) max, min(sal) min from emp group by deptno) temp where E.deptno = (select deptno from dept where dname = 'SALES')
分析:
确定所需要的数据表:
dept表:销售部(SALES),最终是根据销售部来统计的,所以需要知道销售部的部门编号。
emp表:编号、姓名、职位、雇用日期、基本工资、奖金。
emp表:统计最高和最低工资。
步骤一:查询出销售部的部门编号。
select deptno from dept where dname = 'SALES';
步骤二:找到在此部门的全部雇员信息。
select empno, ename, sal, comm, job, hiredate from emp where deptno = (select deptno from dept where dname = 'SALES');
步骤三:如果要统计出最高和最低工资,使用的一定是max()和min()函数,但是对于统计函数的使用限制:
* 统计函数要么单独使用,要么结合group by使用,单独使用的时候select子句中不允许出现其他字段。
* 结合group by子句使用的时候select子句中允许出现分组字段。
* 统计函数嵌套的时候不允许出现任何字段。
发现在整个select查询中需要使用统计函数,但是却无法直接使用统计查询,那么就可以在子查询中完成,而且子查询一定返回多行多列的数据,也就是在from子句中出现。
select empno, ename, sal, comm, job, hiredate, temp.max, temp.min from emp E, (select deptno dno, max(sal) max, min(sal) min from emp group by deptno) temp where deptno = (select deptno from dept where dname = 'SALES') and E.deptno = temp.dno;
4.3 子查询——范例
查询出所有薪资高于公司平均薪资的员工编号、姓名、基本工资、职位、雇佣日期、所在部门名称、位置、上级领导姓名、公司的工资等级、部门人数、部门平均工资、部门平均服务年限。
select E1.empno, E1.ename, E1.sal, E1.job, E1.hiredate, D1.dname, D1.loc, E2.ename 领导, S1.grade, E2.count, E2.avg1, E2.avg2 from emp E1, dept D1, emp E2, salgrade S1, (select deptno dno, count(empno) count, round(avg(sal)) avg1, round(avg(months_between(sysdate,hiredate)/12)) avg2 from emp group by deptno) E2 where E1.sal > (select avg(sal) from emp) and E1.deptno = D1.deptno and E1.mgr = E2.empno(+) and E1.sal between S1.losal and S1.hisal and E1.deptno = E2.dno;
分析:
确定所需要的数据表:
emp表:员工编号、姓名、基本工资、职位、雇佣日期。
dept表:部门名称、位置。
emp表:上级领导姓名。
salgrade表:工资等级。
emp表:统计出部门人数、平均工资、平均服务年限。
确定已知的关联字段:
雇员和部门:emp.deptno = dept.deptno;
雇员和领导:emp.mgr = emp.deptno;
雇员和工资等级:emp.sal between slagrade.losal and salgrade.hisal;
步骤一:使用avg()函数统计公司的平均薪资。
select avg(sal) from emp;
结果返回单行单列的数值,一定是在where或者having中出现,但是根据分析,只能在where中出现。
步骤二:查询出高于此平均工资的员工编号、姓名、基本工资、职位、雇用日期。
select E1.empno, E1.ename, E1.sal, E1.job, E1.hiredate from emp E1 where E1.sal > (select avg(sal) from emp);
步骤三:需要知道部门的名称、位置,所以增加dept表
select E1.empno, E1.ename, E1.sal, E1.job, E1.hiredate, D1.dname, D1.loc from emp E1, dept D1 where E1.sal > (select avg(sal) from emp) and E1.deptno = D1.deptno;
步骤四:需要找到领导的姓名,一定是自身关联,一定要想到KING的问题,因为KING没有领导,mgr为null,需要使用外连接。
select E1.empno, E1.ename, E1.sal, E1.job,E1.hiredate, D1.dname, D1.loc, E2.ename from emp E1, dept D1 where E1.sal >(select avg(sal) from emp) and E1.deptno = D1.deptno and E1.mgr = E2.empno(+);
步骤五:查询工资等级。
select E1.empno, E1.ename, E1.sal, E1.job,E1.hiredate, D1.dname, D1.loc, E2.ename, S1.grade from emp E1, dept D1, salgrade S1 where E1.sal >(select avg(sal) from emp) and E1.deptno = D1.deptno and E1.mgr = E2.empno(+) and E1.sal between S1.losal and S1.hisal;
步骤六:加入统计结果。
见查询。
4.4 子查询——范例
查询出薪资比“ALLEN”或“CLARK”高的所有员工的编号、姓名、基本工资、部门名称、领导姓名和部门人数。
select E1.ename, E1.ename, E1.sal, D1.dname, E2.ename, temp.count from emp E1, dept D1, emp E2, (select deptno dno, count(empno) count from emp group by deptno) temp where E1.sal > any (select sal from emp where ename in ('ALLEN', 'CLARK'))
分析:
确定所需要的数据表:
emp表:员工编号、姓名、基本工资。
dept表:部门名称。
emp表:领导姓名。
emp表:部门人数统计。
确定已知的关联字段:
部门和雇员:emp.deptno = dept.deptno;
雇员和领导:emp.mgr = memp.empno(+);
步骤一:找到ALLEN或CLARK的工资。
因为存在或操作,所以可以使用any操作符。
此时返回的是多行单列数据,那么多行单列的判断只能够使用in、any或all进行操作,所以根据分析应该使用any进行操作,因为只要比其中一个大即可。
步骤二:查询雇员信息。
select E1.empno, E1.ename, E1.sal from emp E1 where E1.sal > any (select sal from emp where ename in ('ALLEN', 'CLARK')) and E1.ename not in ('ALLEN', 'CLARK');
步骤三:加入部门表,列出部门名称。
select E1.empno, E1.ename, E1.sal, D1.dname from emp E1, dept D1 where E1.sal > any (select sal from emp where ename in ('ALLEN', 'CLARK')) and E1.ename not in ('ALLEN', 'CLARK') and E1.deptno = D1.deptno;
步骤四:使用emp表进行自身关联,查询出领导姓名。
select E1.empno, E1.ename, E1.sal, D1.dname, E2.ename from emp E1, dept D1, emp E2 where E1.sal > any (select sal from emp where ename in ('ALLEN', 'CLARK')) and E1.ename not in ('ALLEN', 'CLARK') and E1.deptno = D1.deptno and E1.mgr = E2.empno(+);
步骤五:此时的select子句中不可能直接使用统计查询了,只能够使用from子句进行子查询来完成。
select E1.empno, E1.ename, E1.sal, D1.dname, E2.ename, temp.count from emp E1, dept D1, emp E2, (select deptno dno, count(empno) count from emp group by deptno) temp where E1.sal > any (select sal from emp where ename in ('ALLEN', 'CLARK')) and E1.ename not in ('ALLEN', 'CLARK') and E1.deptno = D1.deptno and E1.mgr = E2.empno(+) and E1.deptno = temp.dno;
4.5 子查询——范例
列出公司各个部门的经理的姓名、薪资、部门名称、部门人数、部门平均工资。
select E.ename, E.sal, temp.count, D.dname, temp.avg from emp E, (select deptno dno, count(empno) count, round(avg(sal),2) avg from emp group by deptno) temp, (select deptno dno, dname dname from dept) D where job = 'MANAGER' and E.deptno = temp.dno and E.deptno = D.dno;
分析:
确定所需要的数据表:
emp表:经理的姓名、薪资。
dept表:部门名称。
emp表:部门人数、部门的平均工资。
确定已知的关联字段:
雇员(经理):emp.deptno = dept.deptno;
步骤一:找到经理的姓名和薪资。
select ename, sal from emp where job = 'MANAGER';
步骤二:找到部门名称。
select ename, sal, D1.dname from emp E1, dept D1 where E1.job = 'MANAGER' and E1.deptno = D1.deptno;
步骤三:需要统计结果,此时select子句中无法直接使用统计查询,那么就使用子查询。
select ename, sal, D1.dname, temp.count, temp.avg from emp E1, dept D1, (select deptno dno, count(empno) count, round(avg(sal)) avg from emp group by deptno) temp where E1.job = 'MANAGER' and E1.deptno = D1.deptno and temp.dno = E1.deptno;
4.6 小结
from子句出现的子查询返回结果为多行多列。
利用子查询可以解决多表查询所带来的性能问题。
5、select子句中的子查询
要求:了解select子句使用子查询操作的代码形式。
子查询可以出现在任意位置上,不过从实际的项目来讲,在where、from、having子句中使用子查询的情况还是比较多的,而对于select子句,只是以一种介绍的形式进行说明。
5.1 子查询——范例
查询出公司每个部门的编号、名称、位置、部门人数、平均工资。
select D.deptno, D.dname, D.loc, (select count(empno) from emp where deptno = D.deptno) count, (select avg(empno) from emp where deptno = D.deptno) avg from dept D;
这类子查询完全可以通过其他的形式来实现,所以意义并不大。
5.2 小结
select子句中出现子查询的情况一般比较少见,了解即可。
6、with子句
要求:可以使用with子句创建临时查询表。
临时表实际上就是一个查询结果,如果一个查询结果返回的是多行多列,那么就可以将其定义在from子句之后,表示为一张临时表。但是除了在from子句之中出现临时表之外,也可以利用with子句直接定义临时表,也就是绕开了from子句。
6.1 子查询——范例
使用with子句将emp表中的数据定义为临时表。
with E as (select * from emp) select * from E;
E就表示整个查询结果
6.2 子查询——范例
查询每个部门的编号、名称、位置、部门平均工资、人数。
with E as (select deptno dno, round(avg(sal)) avg, count(empno) count from emp group by deptno)
6.3 子查询——范例
查询每个部门工资最高的雇员编号、姓名、职位、雇佣日期、工资、部门编号、部门名称、显示的结果按照部门编号降序排序。
with temp as (select deptno dno, max(sal) max from emp group by deptno) select E1.deptno, E1.empno, E1.ename, E1.job, E1.hiredate, E1.sal, D.dname from emp E1, temp, dept D where E1.sal = temp.max and E1.deptno = D.deptno forder by E1.deptno desc;
分析:
步骤一:使用with定义临时表,统计每个部门的最高工资。
6.4 小结
with子句可以创建一个临时表供查询使用。
7、分析函数
要求:
理解分析函数的主要语法;
理解分窗操作的使用;
了解基本分析函数。
传统SQL问题:
虽然利用SQL之中提供的各种查询命令可以完成大部分的查询需求,但是还有许多功能是无法实现的,例如:
计算运行总量:逐一累加当前行与其之前行的每行记录数据。
查找当前行数据占总数据的百分比。
分区显示:按照不同的部门或职位进行排列、统计。
计算流动数据行的平均值。
传统SQL就是SQL标准规定的语法:select、from、where、group by、having、order by,但是传统SQL所能够完成的功能实际上并不多。
在分析函数之中也可以使用若干统计函数count()等进行操作。
7.1 分析函数基本语法
基本语法:
函数名称([参数,...]) over (
partition by子句 字段, ...
[order by 子句 字段, ... [asc | desc] [nulls first | nulls last]]
[windowing子句]
);
本语法组成如下:
函数名称:类似于统计函数(count() sum()等),但是在此时有了更多的函数支持。
over子句:为分析函数指明一个查询结果集,此语句在select子句之中使用。
partition by子句:将一个简单的结果集分为N组(或称为分区),然后按照不同的组对数据进行统计。
order by子句:明确指明数据在每个组内的排列顺序,分析函数的结果与排列顺序有关;
nulls first | nulls last:表示返回数据行中包含null值是出现在排序序列前还是序列尾。
windowing子句(代名词):给出在定义变化的固定的数据窗口方法,分析函数将对此数据进行操作。
组合顺序:
在分析函数之中存在三种子句:partition by、order by、windowing,这三种子句的组合顺序有如下几种:
第一种组合:
函数名称([参数, ...]) over (partition by子句, order by子句 windowing子句);
第二种组合:
函数名称([参数, ...]) over (partition by子句 order by子句);
第三种组合:
函数名称([参数, ...]) over (partition by子句);
第四种组合:
函数名称([参数, ...]) over (order by子句 windowing子句);
第五种组合:
函数名称([参数, ...]) over (order by子句);
第六种组合:
函数名称([参数, ...]) over();
7.2 分析函数——范例
使用partition by子句。
传统问题:
select deptno, ename, sal from emp;
这只是一个简单查询,但是在这个select子句中,是不可能出现统计函数的,因为统计函数于要么单独使用,要么结合group by使
用。但是如果现在使用分析函数,那么就不一样了。
select ename, sal, sum(sal) over (partition by deptno) from emp;
现在的数据是按照部门的范畴进行了统计,每行数据之后都会有统计的结果存在。
如果不进行分区操作:
select ename, sal, sum(sal) over () from emp;
如果没有分区,则会把所有的数据当做一个区,一起进行统计。
使用partition by子句设置多个分区:
select deptno, job, ename, sal, sum(sal) over(partition by deptno, job) sum from emp;
7.3 分析函数——范例
使用order by子句。
order by子句的作用主要就是进行排序,现在实现的是分区内的数据排序,而这个排序会直接影响到最终的查询结果。
按照部门编号分区,然后按照工资进行降序排序:
select deptno, ename, sal, rank() over(partition by deptno order by sal desc) from emp;
设置多个排序字段:
select deptno, ename, sal, hiredate, rank() over(partition by deptno order by sal, hiredate desc) from emp;
直接利用order by排序所有数据:
select deptno, ename, sal, hiredate, sum(sal) over(order by ename desc) from emp;
现在如果不写分区操作,那么就表示为所有数据进行排序。
它现在是将所有的数据变为一组,然后按照姓名进行排序操作。
order by子句选项:
在order by子句之中还存在两个选项:nulls first和nulls last,其中nulls first表示在进行排序时,出现null值的数据行排列在最前面,而nulls last则表示出现的null值数据行排列在最后。
select deptno, ename, sal, comm, rank() over(order by comm desc nulls last), sum(sal) over(order by comm nulls last) from emp;
7.4 Windowing子句
分窗子句主要是用于定义一个变化或固定的数据窗口方法,主要用于定义分析函数在操作行的集合,分窗子句有两种实现方式:
实现一:值域窗(range window),逻辑偏移,当前分区之中当前行的前N行到当前行的记录集。
10~15就是值域。
实现二:行窗(rows window),物理偏移,以排序的结果顺序计算偏移当前行的起始行记录集。
3~5行是行域。
而如果要想指定range或rows的偏移量,则可以采用如下的几种排序列:
range | rows 数字 preceding;
range | rows between unbounded preceding and current row;
range | rows between current row and unbounded following;
以上的几种排列之中包含的概念如下:
preceding:主要是设置一个偏移量,这个偏移量可以是用户设置的数字,也可以是其他标记。
between...and:设置一个偏移量的操作范围。
unbounded preceding:不限制偏移量的大小。
following:如果不写此语句则表示使用上N行与当前行指定数据进行比较,如果编写此语句,表示当前行与下N行数据进行比较。
7.5 分析函数——范例
验证range子句:
range子句设置的是一个逻辑偏移量。
select deptno, ename, sal, sum(sal) over(partition by deptno order by sal range 300 preceding) sum from emp;
现在的结果是按照向上N行的记录进行偏移,也可以采用向下匹配方式进行处理。
设置偏移量为300,采用向下匹配方式进行处理:
select deptno, ename, sal, sum(sal) over (partition by deptno order by sal range between 0 preceding and 300 following) sum from emp;
发现现在显示结果还是与后面的N行数据进行匹配。同时也可以匹配当前行:
select deptno, ename, sal, sum(sal) over (partition by deptno order by sal range between 0 preceding and current row) sum from emp;
使用unbounded不设置边界:
select deptno, ename, sal, sum(sal) over(partition by deptno order by sal range between unbounded preceding and current row) sum from emp;
现在的结果就是在一个区域内进行逐行的操作,并不设置偏移量。
current row表示当前行。
如果是物理偏移,使用rows子句即可:
设置2行的物理偏移量。
select deptno, ename, sal, sum(sal) over(partition by deptno order by sal rows 2 preceding) sum from emp;
现在就是按照部门编号分组,然后采用当前行与前两行数据进行计算。
设置查询行范围:
select deptno, ename, sal, sum(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following) sum from emp;
此时与最早的按照部门分区,进行求和运算道理是相同的。
7.6 数据统计函数
sum([distinct | all] 表达式) 计算分区(分组)中的数据累加之和。
min([distinct | all] 表达式) 查找分区(分组)中的最小值。
max([distinct | all] 表达式) 查找分区(分组)中的最大值。
avg([distinct | all] 表达式) 计算分区(分组)中的数据平均值。
count([distinct | all] | * ) 计算分区(分组)中的数据量。
数据统计函数和之前的分组统计中所使用的函数区别不大。
7.7 分析函数——范例
查询雇员编号是7369的雇员姓名、职位、基本工资、部门编号、部门的人数、平均工资、最高工资、最低工资和总工资。
分析:
第一反应肯定是采用多表查询来完成操作,但是现在有了分析函数,就可以利用分区来完成。
步骤一:统计出全部数据。
select empno, ename, job, sal, deptno, count(empno) over (partition by deptno) count, round(avg(sal) over (partition by deptno)) avg, sum(sal) over (partition by deptno) sum, max(sal) over (partition by deptno) max, min(sal) over (partition by deptno) min from emp;
必须先求出全部的数据,否则加入where empno = 7369之后,部门人数就为1,因为分析函数是根据现有数据进行操作的。
步骤二:以上的结果返回的是多行多列,所以就是一张数据表的结构,可以通过from子查询来进行操作。
select * from (select empno, ename, job, sal, deptno, count(empno) over (partition by deptno) count, round(avg(sal) over (partition by deptno)) avg, sum(sal) over (partition by deptno) sum, max(sal) over (partition by deptno) max, min(sal) over (partition by deptno) min from emp) temp where temp.empno = 7369;
如果子查询外部需要使用子查询中的字段,例如:where empno = 7369,那么在子查询中必须出现该字段。
7.8 分析函数——范例
查询每个雇员的编号、姓名、基本工资、所在部门的名称、部门位置以及此部门的平均工资、最高和最低工资。
select E.empno, E.ename, E.sal, D.dname, D.loc, count(empno) over (partition by E.deptno order by sal range between bnbounded preceding and unbounded following) count, round(avg(sal) over (partition by E.deptno order by sal range between unbounded preceding and unbounded following)) avg, max(sal) over (partition by E.deptno order by sal range between unbounded preceding and unbounded following) max, min(sal) over (partition by E.deptno order by sal range between unbounded preceding and unbounded following) min from emp E, dept D where E.deptno = D.deptno;
分析:
确定所需要的数据表:
dept表:部门编号、名称、位置。
emp表:雇员编号、姓名、工资、统计信息。
确定已知的关联字段:
雇员和部门:emp.deptno = dept.deptno;
步骤一:进行多表关联,查询雇员的编号、姓名、基本工资、部门名称和部门位置。
select E.empno, E.ename, E.sal, D.dname, D.loc from emp E, dept D where E.deptno = D.deptno;
步骤二:加入统计信息。
7.9 等级函数
rank()函数:
根据order by子句的排序字段,从分区(分组)查询的每一行数据,按照排序生成序号,大小相同时,会出现相同序号。
dense_rank()函数:
根据order by子句的排序字段,从分区(分组)查询的每一行数据,按照排序生成序号,大小相同时,不会出现相同序号。
first:
取出dense_rank()函数返回集合中的第一行数据。
last:
取出dense_rank()函数返回集合中的最后一行数据。
first_value(列)函数:
返回分区(分组)中的第一个值。
last_value(列)函数:
返回分区(分组)中的最后一个值。
lag(列名称 [, 行数字] [, 默认值])函数:
访问分区(分组)中指定前N行的记录,如果没有则返回默认值。
lead(列名称 [, 行数字] [, 默认值])函数:
访问分区(分组)中指定后N行的记录,如果没有则返回默认值。
row_number()函数:
返回每组中的行号。
7.10 分析函数——范例
使用rank()函数和dense_rank()函数。
select deptno, ename, sal, rank() over (partition by deptno order by sal) ranl_result, dense_rank() over (partition by deptno order by sal) dense_rank_result from emp;
7.11 分析函数——范例
使用row_number()函数。
select deptno, ename, sal, row_number() over (partition by deptno order by sal) row_result_deptno, row_number() over order by sal) row_result_all from emp;
row_number()函数的功能就是用于生成行号。
针对于所有的数据(row_result_all),row_number()函数会根据所有的数据自动生成顺序行号,但是在每一个分区中,也存在一类行号,该行号随着排序的不同而分开,但是在每一个分组中依然保持顺序排序。
7.12 keep语句
keep语句的功能是保留满足条件的数据。
keep语句必须结合group by使用。
分组函数
keep (dense_rank() first | last order by 表达式 [asc | desc] [nulls [first | last]], ...) [over () 分区查询];
查询每个部门的最高工资和最低工资。
select deptno, max(sal) keep (dense_rank first order by sal desc) max_salary, min(sal) keep (dense_rank last order by sal desc) min_salary from emp group by deptno
keep语句的功能是保留满足条件的数据,而且必须在使用dense_rank()函数确定集合后才可以使用,通过first或last取得集合中的数据。
7.13 分析函数——范例
验证first_value()与last_value()函数。
select deptno, empno, ename, sal, first_value(sal) over (partition by deptno order by sal range between unbounded preceding and unbounded following) first_result, last_value(sal) over (partition by deptno order by sal range between unbounded preceding and unbounded following) last_result from emp;
over()是声明一个数据集合,而first_value()或last_value()函数取得的是集合中的首行或尾行。
7.14 分析函数——范例
观察lag()和lead()函数。
select deptno empno, sal, lag(sal,2,0) over (partition by deptno order by sal) lag_result, lead(sal,2,0) over (partition by deptno order by sal) lead_result from emp
7.15 报表函数
cume_dist()函数:
计算一行在分区(分组)中的相对位置。
ntile(数字)函数:
将一个分区(分组)分为“表达式”的散列表示。
ratio_to_report(表达式)函数:
该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比。
7.16 cume_dist()函数
计算相对位置。
例如:假设分区有5条记录,那么这些记录会按照:1、0.8、0.6、0.4、0.2的方式进行划分。
select deptno, ename, sal, cume_dist() over (partition by deptno order by sal)cume from emp where deptno in(10,20);
7.17 ntile()函数
ntile()函数是针对数据分区中的有序结果集进行划分。
select deptno, sal, sum(sal) over(partition by deptno order by sal) sum_result, ntile(3) over(partition by deptno order by sal) ntile_result_a, ntile(6) over(partition by deptno order by sal)ntile_result_b from emp;
7.18 ratio_to_report()函数
ratio_to_report()函数是按照整体数据的百分比显示。
select deptno, sum(sal), round(ratio_to_report(sum(sal)) over(),3) * 100 ||'%' precent from emp group by deptno;
7.19 小结
使用分析函数可以进行更为复杂的查询报表显示。
8、行列转换
要求:
了解行列转换的基本概念。
了解pivot和unpivot函数的使用。
行列转换严格来讲是一种小技巧,为了说明问题,下面首先通过一个程序演示。
8.1 行列转换——范例
查询每个部门中各个职位的总工资,按照部门编号以及职位进行分组。
select deptno,job, sum(sal) from emp group by deptno,job
如果按照原始的方式实现,那么只需要利用decode()函数就可以了:
select deptno, sum(decode(job, 'PRESIDENT', sal, 0)) PRESIDENT_job, sum(decode(job, 'MANAGER', sal, 0)) MANAGER_job, sum(decode(job, 'ANALYST', sal, 0)) ANALYST_job, sum(decode(job, 'CLERK', sal, 0)) CLERK_job, sum(decode(job, 'SALESMAN', sal, 0)) SALESMAN_job from emp group by deptno;
以上的方式是使用decode()函数,但是这个函数是属于Oracle自己的特色函数,那么如果没有decode()函数呢?
只能利用select子句的子查询来完成:
select deptno dno, (select sum(sal) from emp where job = 'PRESIDENT' and empno = E.empno) PRESIDENT_job, (select sum(sal) from emp where job = 'MANAGER' and empno = E.empno) MANAGER_job, (select sum(sal) from emp where job = 'ANALYST' and empno = E.empno) ANALYST_job, (select sum(sal) from emp where job = 'CLERK' and empno = E.empno) CLERK_job, (select sum(sal) from emp where job = 'SALESMAN' and empno = E.empno) SALESMAN_job from emp E;
此时列出的是各个职位的统计信息,但是结果还是存在差异,那么则继续嵌套子查询:
select temp.dno, sum(PRESIDENT_job), sum(MANAGER_job), sum(ANALYST_job), sum(CLERK_job), sum(SALESMAN_job)
虽然实现了功能,但是从感觉上讲,觉得还是有些过于复杂了。
8.2 pivot()函数
在Oracle11g版本之后,专门增加了pivot和unpivot两个转换函数。
pivot函数:
select * | 列 from 子查询 pivot( 统计函数(列) for 转换列名称 in (内容1 [[as]别名]), 内容2[[as]别名] ) where 条件....
使用pivot函数进行行列转换:
select * from ( select deptno, job, sal from emp ) pivot( sum(sal) for job in ( 'PRESIDENT' as PRESIDENT_job, 'MANAGER' as MANAGER_job, 'ANALYST' as ANALYST_job, 'CLERK' as CLERK_job, 'SALESMAN' as SALESMAN_job ) ) order by deptno;
发现使用pivot()函数操作起来实现的转换更加容易理解,这个函数还可以使用一个any变为XML数据显示。
select * from (select deptno, job, sal from emp) pivot XML(sum(sal) for job in (any)) order by deptno;
8.3 行列转换——范例
查询更多统计信息,包括最高和最低工资,只需要利用分析函数即可。
select * from (select job, deptno, sal, sum(sal) over (partition by deptno) sum_sal, max(sal) over (partition by deptno) max_sal, min(sal) over (partition by deptno) min_sal from emp ) pivot ( sum(sal) for job in( 'PRESIDENT' as PRESIDENT_job, 'MANAGER' as MANAGER_job, 'ANALYST' as ANALYST_job, 'CLERK' as CLERK_job, 'SALESMAN' as SALESMAN_job)) order by deptno;
现在查询的不再是一个纯粹的职位,之后还包含了其他的统计信息,在之前所设置的都属于一个统计函数,也可以使用多个统计函数。
select * from (select job, deptno, sal, sum(sal) over (partition by deptno) sum_sal, max(sal) over (partition by deptno) max_sal, min(sal) over (partition by deptno) min_sal from emp) pivot (sum(sal) as sum_sal, max(sal) max_sal for job in('PRESIDENT' as PRESIDENT_job, 'MANAGER' as MANAGER_job, 'ANALYST' as ANALYST_job, 'CLERK' as CLERK_job, 'SALESMAN' as SALESMAN_job)) order by deptno;
此时发现数据被拆分了。
现在只是针对job字段实现的分组,这样并不是很好,希望有多个字段进行分组,为了满足要求,可以这么写,增加一个sex列,同时更新81年雇佣的雇员性别都为女,于是有了如下几个语句:
alter table emp add(sex varchar2(10) default '男');
update emp set sex = '女' where to_char(hiredate,'yyyy') = 1981; commit;
这个时候就增加了一个性别的列。
8.4 行列转换——范例
设置多个统计列。
select * from (select deptno, job, sex, sal from emp) pivot (sum(sal) as sum_sal, max(sal) max_sal for (job,sex) in (('MANAGER','男') as MANAGER_male_job, ('MANAGER','女') as MANAGER_female_job, ('CLERK','男') as CLERK_male_job ('CLERK','女') as CLERK_female_job)) order by deptno;
9、设置数据层次
要求:
了解level...connect by子句的使用。
设置层次函数:
层次查询是一种较为确定数据行之间关系结构的一种操作,例如:在现实社会的工作之中一定会存在“管理层”、“职员层”这样额基本分层关系,幸运的是在Oracle之中用户也可以利用其自身所带的工具实现这样的层次组织。
语法:
level ... connect by [nocycle] prior 连接条件 [start with 开始条件]
语法组成:
level:可以根据数据所处的层次结构实现自动的层次编号,例如:1、2、3;
connect by:指的是数据之间的连接,例如:雇员数据依靠mgr确定其领导,就是一个连接条件,其中nocycle需要结合connect_by_iscycle伪劣确定出父子节点循环关系;
start with:根节点数据的开始条件。
9.1 数据层次——范例
观察分层的基本关系。
select empno, ename, mgr, level from emp connect by prior empno = mgr start with mgr is null;
select empno, lpad('|-', level * 2, ' ') || ename, mgr, level from emp connect by prior empno = mgr start with mgr is null;
现在的操作是从KING开始的(mgr = null),然后按照领导的结构进行分层。
9.2 connect_by_isleaf伪列
在一个树状结构之中,节点会分为两种:根节点和叶子节点,用户可以利用“connect_by_isleaf”伪列判断某一节点是根节点还是叶子节点,如果此列返回的是数字0,则表示根节点,如果返回1,则表示叶子节点。
select empno, lpad('|-', level * 2, ' ') || ename, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, ' 叶子节点') from emp connect by prior empno = mgr start with mgr is null;
9.3 connect_by_root列
connect_by_root的主要作用是取得某一字段在本次分层之中的根节点数据名称,例如:如果按照领导层次划分,则所有数据的根节点都应该是KING。
select empno, lpad('|-', level * 2, ' ') || ename, mgr, level, connect_by_root ename from emp connect by prior empno = mgr start with mgr is null;
最大的根节点的数据就是KING的信息,现在换一种方式,从一个指定的雇员信息开始。
select empno, lpad('|-', level * 2, ' ') || ename, mgr, level, connect_by_root ename from emp connect by prior empno = mgr start with empno = 7566;
9.4 sys_connect_by_path(列, char)函数
利用“sys_connect_by_path()”函数按照给出的节点关系,自动将当前根节点中的所有相关路径进行显示。
使用sys_connect_by_path()函数取得节点路径信息。
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点') isleaf from emp connect by prior empno = mgr start with mgr is null;
9.5 数据层次——范例
去掉某一节点,将7698节点去掉。
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点') isleaf from emp connect by prior empno = mgr and empno != 7698 start with mgr is null;
9.6 order siblings by 字段
在使用层次查询进行数据显示时,如果用户直接使用order by子句进行指定字段的排序,有可能会破坏数据的组成结构。
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点') isleaf from emp connect by prior empno = mgr start with mgr is null order by ename;
那么现在希望保持结构的排序,可以使用order siblings by字段:
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点') isleaf from emp connect by prior empno = mgr start with mgr is null order siblings by ename;
9.7 connect_by_iscycle伪列
在进行数据层次设计的过程之中,最为重要的是根据指定的数据列确定数据间的层次关系,但是有时候也可能出现死循环,例如:KING的领导是BLAKE,而BLAKE的领导是KING就表示一个循环关系,为了判断循环关系的出现,在ORacle中也提供了一个connect_by_iscycle伪列,来判断是否会出现循环,如果出现循环,则显示1,否则显示0,同事如果想要判断是否为循环节点,则还需要“nocycle”的支持。
原本KING没有领导,但是为了发现问题,给KING添加一个领导,将领导设置为BLAKE。
update emp set mgr = 7698 where empno = 7839;
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点') isleaf from emp connect by prior empno = mgr start with empno = 7839 order siblings by ename;
错误提示:ORA-01436: 用户数据中的 CONNECT BY 循环
此时由于存在了循环关系,所以无法显示数据,可以设置nocycle禁止循环:
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点')isleaf from emp connect by nocycle prior empno = mgr start with empno = 7839 order siblings by ename;
设置了nocycle之后循环就取消了,至少可以正常显示了。
当不确定是否存在循环时,可以通过connect_by_iscycle伪列来判断是否存在循环:
select empno, lpad('|-', level * 2, ' ') || sys_connect_by_path(ename, '=>') empname, mgr, level, decode(connect_by_isleaf, 0, '根节点', 1, '叶子节点')isleaf, decode(connect_by_iscycle, 0, '【√】没有循环', 1, '【×】存在循环') from emp connect by nocycle prior empno = mgr start with empno = 7839 order siblings by ename;
九、数据更新
在SQL语句之中,数据的操作语言(DML)由两个部分组成:查询(DQL)、更新操作(增加、修改、删除)。
在Oracle数据库中,一直使用的数据表就是emp表和dept表,那么这两张表日后还会有其他用处,为了保证表中的数据不被破坏,所以现在将将使用到的表复制一份,主要使用的是emp表。
1、更新前的准备操作
1.1 复制emp表
create table emp1 as select * from emp;
需要注意的是,数据存在,但是却没有约束,所以更新的时候可以自由一些。
2、数据的增加操作
目标:
可以为数据表添加新的数据。
将子查询结果作为增加数据。
对于所有的更新操作,与查询操作最大的不同在于其语法几乎都是固定的。
语法:
数据增加操作指的是向数据表中添加一条新的记录,而对于数据的插入通常有两种形式:
形式一:插入一条新的数据
insert into 表名 [(列1, 列2, ... )] values (值1, 值2, 值3, ... );
形式二:插入子查询的返回结果
insert into 表名 [(列1, 列2, ... )] 子查询;
所接触到的数据主要有三种(varchar2、number、date),所以此时对于这三种数据在增加于法之中的编写要求如下:
number类型:直接编写,如:123;
varchar2类型:使用“ ' ”声明,例如:'Oracle'(clob类型也按照同样的方式进行);
date类型:可以按照已有的日期格式编写字符串,例如:'08-10月 -2016',或者是使用to_date()函数将字符串变为date类型数据,而如果为当前日期时间,则直接使用sysdate即可。
2.1 增加数据——范例
向emp1数据表之中增加一条新的数据。
推荐:使用完整语法进行操作,数据增加时需要写上要增加数据的列的名称。
insert into emp1 (empno, job, hiredate, ename, mgr, sal, comm, deptno) values (8888, 'CLERK', sysdate, '王彦超', 7369, 800, 100, 20);
不推荐:使用简化语法进行操作,增加数据时需要按照列的顺序增加,否则将出现错误。
完整写法必须要加上要插入的列名称。
可以发现,如果没有写上列名称,实际上处理起来的复杂度是很高的,因为必须考虑顺序,所以在开发中,建议使用完整语法,而且在标准项目开发中,一定要使用完整语法。
2.2 增加数据——范例
增加一个没有领导、部门、奖金的新雇员。
推荐:使用完整语法完成,编写时只编写所需要的数据列。
insert into emp1 (empno, ename, job, hiredate, sal) values (6616, '李楠', 'CLERK', to_date('2016-10-07', 'yyyy-mm-dd'), 600);
insert into emp1 values (6616, '李楠', 'CLERK', null, to_date('2016-10-07', 'yyyy-mm-dd'), 600, null, null);
对于没有增加数据的部分,自动使用null值来表示。
2.3 增加子查询结果数据
子查询的数据实际上也是一张表的结构,所以可以直接将这些数据保存到指定表中。
通过子查询增加emp1表数据。
编写完整格式将所有20部门雇员的信息插入到emp1表之中:
insert into emp1 (empno, ename, job, mgr, hiredate, sal, comm, deptno) select * from emp where deptno = 20;
编写简写格式将10部门雇员的信息插入到emp1表之中:
insert into emp1 select * from emp where deptno = 10;
2.4 小结
增加数据时建议使用完整语法,这样可以增加代码的可维护性。
3、数据的更新操作
目标:
掌握数据更新操作的语法。
如果说现在发现表中的数据需要修改,那么就必须使用update语句进行更新操作。
数据库的更新操作主要是指的对数据表中的数据进行修改,与数据的增加一样,在数据修改的时候有两种形式:
形式一:由用户自己指定要更新数据的内容
update 表名 set 字段 = 值 [, 字段 = 值] [where 更新条件]
形式二:基于子查询的更新
update 表名 set (column, column, ... ) = (select column, column, ... from table where 查询条件)
3.1 数据更新——范例
将smith(雇员编号为7369)的工资修改为3000元,并且每个月有500元的奖金。
update emp1 set sal = 3000, comm = 500 where ename = 'SMITH';
3.2 数据更新——范例
将工资低于公司平均薪金的雇员的基本工资上涨20%。
update emp1 set sal = sal * 1.2 where sal < (select avg(sal) from emp);
公司的平均薪金需要通过avg()函数统计得到。
如果此时在更新时,没有写出更新条件,那么表示所有记录都被更改,如果真的执行了这样的操作,那么会出现一个问题:
假设现在数据表中有500万条记录,那么按照每一条更新的时间为0.01s,那么这500万条记录的更新时间是50000秒,等于883分钟,等于13小时,那么就意味着在这13个小时之内,所有的数据都无法被其他用户修改(数据库的锁机制)。所以这种更新全部的操作是不可能出现的,但是如果在现实生活中出现了此类问题并非没有办法。对于软件问题的解决,实际上就只有两句话:时间换空间,空间换时间。例如3D的动画渲染,一定要花费很长的时间,假设一部动画片需要一个月才可以全部渲染完成,但是有可能已经成功了29天,但是在第30天的时候发现出错了,之前所花费的时间就都浪费了。如果此时不希望等待,那么就增加电脑(空间换时间)。
3.3 数据更新——范例
将雇员7369的职位、基本工资、雇用日期更新为与7839相同的信息。
update emp1 set (job, sal, hiredate) = (select job, sal, hiredate from emp where empno = 7839) where empno = 7369;
3.4 小结
数据更新时可以直接设置更新数据也可以通过子查询取得更新数据。
4、数据的删除操作
目标:
掌握删除的操作语法。
当数据表中的某些数据不再需要时,就可以通过删除语句进行删除,删除语句的语法如下所示。
delete from 表名 [where 删除条件];
在删除数据时如果没有指定删除条件,那么就表示删除全部数据,而对于删除条件,用户也可以编写子查询完成。
4.1 数据删除——范例
删除雇员编号是7566的雇员信息。
delete from emp1 where empno = 7566;
4.2 数据删除——范例
删除30部门的所有雇员。
delete from emp1 where deptno = 30;
4.3 数据删除——范例
删除雇员编号为7369、7566、7788的雇员信息。
delete from emp1 where empno in (7369, 7566, 7788);
4.4 数据删除——范例
删除公司工资最高的雇员。
delete from emp1 where sal = (select max(sal) from emp);
除了这些之外,对于日期类型的数据也可以在删除中作为条件进行判断。
4.5 数据删除——范例
删除所有在1987年雇佣的雇员。
delete from emp1 where extract(year from hiredate) = '1981';
4.6 小结
设置的删除条件可以指定具体的数值也可以设置子查询。
对于更新的三个操作:增加、修改、删除,每一次都一定会返回当前操作所影响到的数据行,如果学习过Java,一定要与JDBC操作联系在一起,在JDBC操作中更新数据的操作Statement和PrepareStatement两个接口,调用的方法还是executeUpdate(),返回的是一个int型数据,就是接收更新的行数。
十、事务
1、事务处理
目标:
了解事务的特性;
掌握Oracle中事务处理的相关操作命令。
如果现在断开已有的连接,会出现以上的窗口,实际上这个就表示询问是否处理事务问题,这一特征在Oracle11g版本的时候还没有。
1.1 什么是事务:
事务处理在数据库开发中有着非常重要的作用,所谓事务核心概念就是指一个SESSION所进行的所有更新操作要么全部成功,要么全部失败。事务本身具有:原子性(Atomicity)、一致性(Consistency)、隔离性或独立性(Isolation)、持久性(Durability),以上的四个特征,也被称为ACID特征。
原子性:
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:
一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
隔离性:
类似于Java中的同步锁。
隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
持久性:
当系统崩溃,事务依然可以提交,不受系统控制,受磁盘文件的控制。在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
Oracle中事务操作命令:
set autocommit = off
取消自动提交处理,开启事务处理。
set autocommit = on
打开自动提交处理,关闭事务处理。
commit
提交事务。
rollback to [回滚点]
回滚操作。
savepoint 事务保存点名称
设置事务保存点。
1.2 关于SESSION:
在Oracle数据库之中,每一个连接到此数据库的用户都是一个“SESSION”,每一个SESSION都拥有独立的事务,都可以使用事务操作命令,不同的SESSION事务是完全隔离的。
为了更好的观察事务的特点,所以使用多个SQLPLUS窗口进行功能的展示:
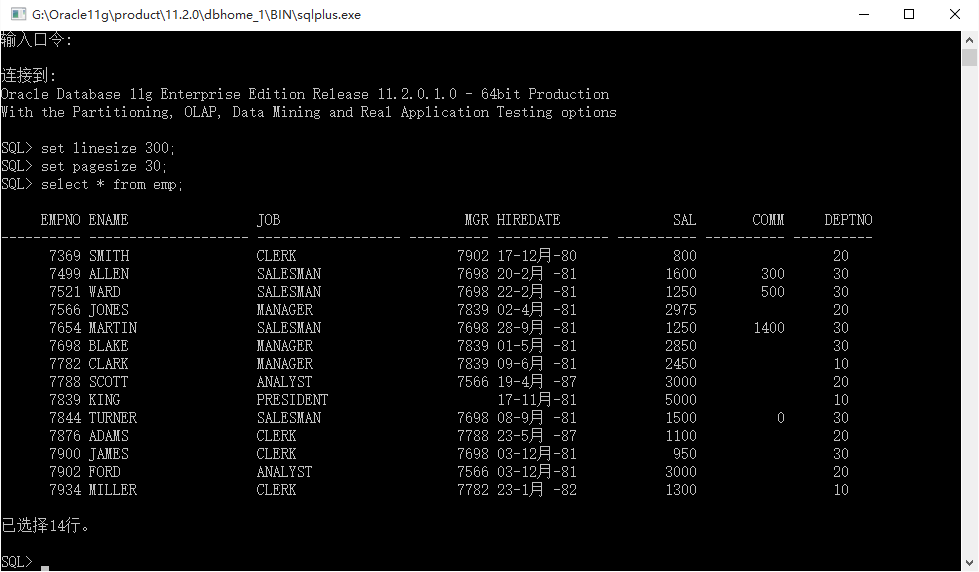
此时emp1一共存在了14行记录,第一个SESSION将执行以下的删除操作:
删除雇佣年数超过32年的员工。
delete from emp1 where months_between(sysdate,hiredate)/12 > 32;
可以发现第一个SESSION删除了12行数据,同时查看一下第一个SESSION中emp1表所剩数据。
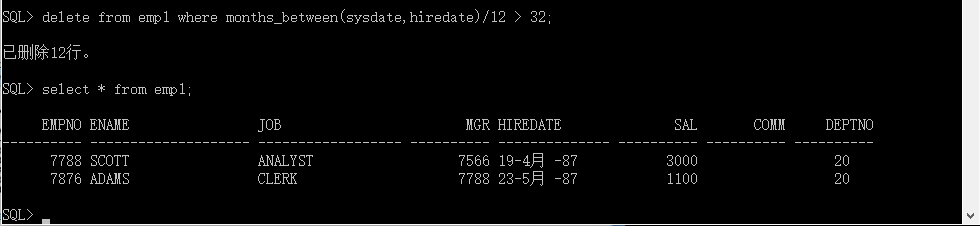
第二个SESSION打开窗口,执行查询操作。
select * from emp1;
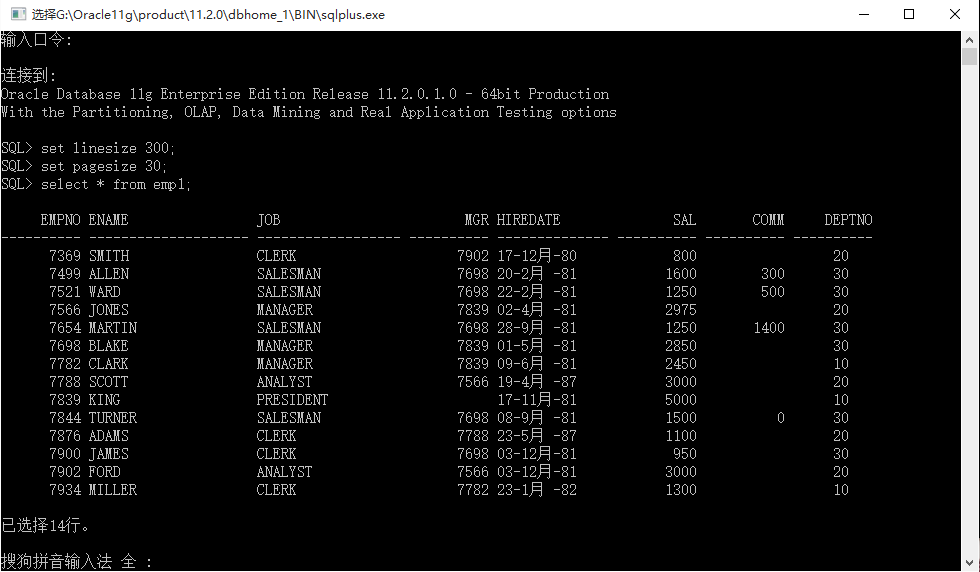
可以发现数据应该已经被删除了,但是现在依然存在,这就是事务的一个特征:更新缓冲。
1.3 更新缓冲
对于每一个SESSION而言,每一个数据库的更新操作在事务没有被提交之前都只是暂时保存在了一段缓冲区之中,并不会真正的向数据库发出命令,如果现在用户发现操作有问题了,则可以进行事务的回滚。
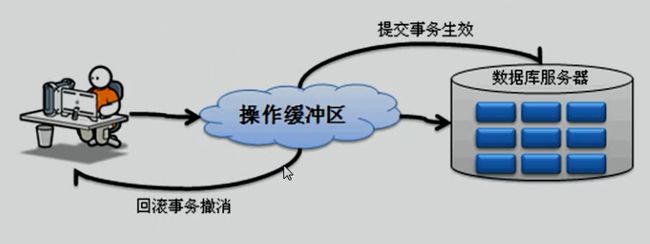
在第一个SESSION之中所执行的更新操作并没有真正发出,因为如果出现错误,要留有一个挽回的余地,所以在其他SESSION使用的时候,数据都是原始的数据。
如果觉得删除操作有误,那么可以在第一个SESSION中使用rollback回滚操作。
但是如果在删除操作的同时使用commit命令提交事务,那么就表示真正的向数据库发出了更新命令,此时第二个SESSION再查询emp1表的全部数据,会发现数据也被更改了,所以说,只有在commit之后,更新操作才会真正的执行。
在没有更新前,执行了rollback操作,那么会回滚到原点上,为了方便操作,Oracle数据库提供了保存点(SAVEPOINT)。
1.4 回滚存储点
在默认情况下,执行rollback命令意味着全部的操作都要回滚,如果现在希望可以回滚到指定操作的话,可以采用SAVEPOINT设置保存点,这样在回滚的时候,就可以通过rollback回滚到指定的保存点上。
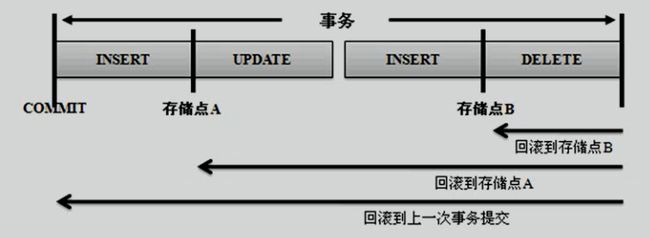
insert into emp1 (empno, ename, hiredate, job, sal) values (1234, '王彦超', sysdate, 'CLERK', 800);
update emp1 set job = '总监' where empno = 5678;
rollback 保存点;
可以发现,只要有保存点,就可以准确的回到保存点所保存的操作中。
1.5 事务自动提交
设置事务是否自动提交:
set autocommit [on | off];
默认情况下,所有的事务都不属于自动提交,必须由用户手动提交,如果希望自动提交,也就是说每执行一个原子性操作,就自动提交一次事务,就必须将事务设为自动提交。
1.6 小结
掌握事务的处理命令:commit、rollback。
2、锁
目标:
掌握所的基本概念。
理解行级锁定与表级锁定。
实际上所谓的锁指的就是不同的SESSION同时操作了同一资源所引发的问题。
2.1 范例
第一个SESSION执行了以下语句:
select * from emp1 where deptno = 10 for update;
第二个SESSION执行同样的语句:
可以看见程序进入阻塞状态。
因为数据只能够被一个SESSION操作,当锁中SESSION执行ROLLBACK之后,第二个SESSION就可以访问了。
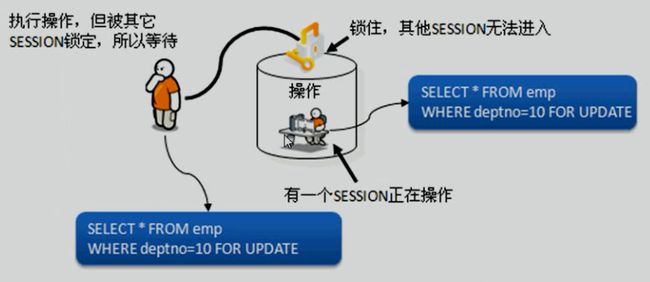
2.2 锁的分类
在Oracle中的锁有两种基本类型。
行级锁定:
又称为记录锁定,对当前事务中的一行数据以独占的方式进行锁定,在此事务结束之前,其他事务要一直等待该事务完结,例如2.1所演示的就是行级锁定。
当记录被锁定之后,依然可以进行查询操作,但是不能被另一个SESSION锁定。
表级锁定:
对整张数据表进行数据锁定,只允许当前事务访问数据表,其他事务无法访问。
2.3 行级锁定
当用户执行了insert、update、delete以及select for update语句时,Oracle将隐式的实现记录的锁定,这种锁定被称为排它锁。
这种锁的主要特点是:
当一个事务执行了相应的数据操作之后,如果此时事务没有提交,那么会一直以独占的方式锁定这些操作的数据,其他事务一直到此事务施放锁后才可以进行操作。
第一个SESSION更新7788的雇员信息。
update emp1 set sal = 6000 where empno = 7788;
第二个SESSION也更新7788的雇员信息。
update emp1 set job = 'MANAGER' where empno = 7788;
此时更新的记录和第一个SESSION的操作是相同的,而且第一个SESSION没有提交事务。
如果第二个SESSION更新了同一行记录,也会遇到锁,进入阻塞状态。
2.4 表级锁定
表级锁定需要用户明确的使用"LOCK TABLE"语句进行手动锁定。
语法:
LOCK TABLE 表名 | 视图名, 表名 | 视图名, ... in 锁定模式 mode [nowait];
nowait:
这是一个可选项,当试图锁定一张数据表时,如果发现已经被其它事务锁定,不会等待。
锁定模式有如下几种常见模式:
row share:
行共享锁,在锁定期间允许其他事务并发对表进行各种操作,但不允许任何事务对同一张表进行独占(禁止排它锁)。
row exclusive:
行排它锁,允许用户进行任何操作,与行共享锁不同的是它不能防止别的事务对同一张表进行手动锁定或独占操作。
share:
共享锁,其他事务只允许执行查询操作,不允许执行更新操作。
share row exclusive:
共享排它锁,允许任何用户进行查询操作,但不允许其他用户使用共享锁,之前所使用的"select from update"就是共享排它锁的常见应用。
exclusive:排它锁,事务将以独占方式锁定表,其他用户允许查询,但是不能修改,也不能设置任何的锁。
2.5 表级锁定——范例
在第一个SESSION对emp1表使用共享锁。
lock table emp1 in share mode nowait;
此时,锁定完成后,第二个SESSION如果想要执行查询操作是没有任何问题的。
第二个SESSION删除emp1表全部数据。
delete from emp1;
第二个SESSION进入阻塞状态。
2.6 解除锁定
尽管用户清楚了锁产生的原因,但是在很多时候由于业务量的增加,可能并不会为用户清楚的罗列出现锁的种种可能,所以此时就必须通过其他方式查看是否出现了锁定以及通过命令手动的解除锁定。
解除锁定语法:
alter system kill session 'sid, serial#'
在此格式之中发现如果想要结束一个SESSION(结束一个SESSION就表示解锁),则需要两个标记:SESSION ID(SID),另外一个就是序列号(SERIAL#),而这两个内容可以利用"v$locked_object"和"v$session"两个数据字典查询得到。
2.7 使用管理员查看锁的情况
第一个SESSION使用for update锁定数据:
select * from emp1 where deptno = 10 for update;
第二个SESSION执行相同操作:
select * from emp1 where deptno = 10 for update;
于是现在就出现了锁的情况,下面就查看锁的问题,但是普通用户无法查看,必须是超级管理员才能查看(SYS)。
查看数据字典:
select * from v$locked_object;

select session_id, oracle_username, process from v$locked_object;
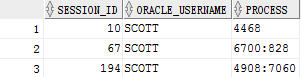
此处会查询到一个SESSION_ID(每一个用户的SESSION由管理员分配)。但是只知道SESSION_ID还无法解除锁定,所以还必须查看v$session的数据字典。
select * from v$session where sid in (67, 194);
但是因为数据太多,所以指定字段进行查询:
select sid, serial#, lockwait, status from v$session where sid in (67, 194);

active:
处于此状态的会话,表示正在执行,处于活跃状态。
inactive:
处于此状态的会话表示不是正在执行的。
killed:
处于此状态的会话,被标注为删除,表示出现了错误,正在回滚。
2.8 KILL一个线程(SESSION)(解除死锁)
alter system kill session '194, 185';
此时,锁定的一方就会出现被KILL SESSION的提示:
当管理员执行完该命令之后,如果该SESSION再执行其他命令,会显示:
SQL> select * from emp1 where deptno = 10 for update;
2.9 小结
锁是在多个SESSION访问同一资源时出现的状态。
锁分为两类:行级锁定和表级锁定。
十一、变量
1、替代变量
替代变量只是Oracle中的一种灵活概念,与实际的开发关系并不大。
目标:
理解替代变量的基本概念。
理解替代变量定义。
了解ACCEPT指令。
替代变量的操作就类似于键盘输入数据的操作。
1.1 替代变量——范例
验证替代变量的使用,查询工资大于2000的员工信息。
select * from emp where sal > 2000;
发现此时要进行操作的数据是固定的,能不能有一种方式,由用户动态的来决定数值呢?所以这就属于替代变量的应用范畴。
select * from emp where sal > &inputsal;
此时使用了一个替代变量,于是在SQLDeveloper中运行效果如下:
如果此处输入的值为2000,那么在替代变量的地方的数值就变为了2000。
但是发现利用此工具表现的不是很明显,所以还是使用sqlplus完成。
以上输入的是一个数字,还可以输入字符串。
1.2 替代变量——范例
查询一个雇员的雇员编号、姓名、职位、雇用日期、基本工资,查询的雇员姓名由用户输入:
select empno, ename, job, hiredate, sal from emp where ename = &inputename;
字符串还需要使用单引号“ ' ’”,所以此时还需要输入单引号,过于麻烦,那么就在定义替代变量的时候准备好单引号:
select empno, ename, job, hiredate, sal from emp where ename = '&inputename';
但是这个时候还存在一个问题,输入数据的时候肯定不会考虑大小写问题,既然数据表中的数据都使用了大写字母表示,那么就直接将用户输入的全部内容通过upper()函数转换为大写即可:
select empno, ename, job, hiredate, sal from emp where ename = upper('&inputename');
1.3 替代变量——范例
根据雇员姓名额关键字(由用户输入)查询雇员编号、姓名、职位、雇用日期、基本工资。
select empno, ename, job, hiredate, sal from emp where ename like '%&inputkeyword%';
由用户输入雇用日期,要求查询出所有早于此雇用日期的雇员编号、姓名、职位、雇佣日期、基本工资。
select empno, ename, job, hiredate, sal from emp where hiredate < to_date('&inputhiredate', 'yyyy-mm-dd');
如果输入的是日期,用户只能够输入字符串,而且中国的习惯是以“年 - 月 - 日”的方式输入,所以必须使用to_date()函数进行转换。
1.5 替代变量——范例
输入查询雇员的职位及工资(高于输入工资)信息,然后显示雇员编号、姓名、职位、雇用日期、基本工资。
select empno, ename, job, hiredate, sal from emp where job = '&inputjob' and sal > &inputsal;
1.6 替代变量的详细说明
在SELECT子句中使用替代变量:
select &inputColumnName from emp where deptno = &inputDeptno;
在FROM子句中使用替代变量:
select * from &inputTableName;
在order by子句中使用替代变量:
select * from emp order by &inputOrderByColumn desc;
在group by子句中使用替代变量:
select &inputGroupByColumn, sum(sal) from emp group by &inputGroupByColumn;
在分组查询之中,select子句里面可以出现的字段一定是group by子句中规定的分组字段。
分别输入:job,deptno
此时出现了错误,因为没有任何一个限定操作可以让两个输入保持一致,实际上也无法限定,但是如果现在只输入一次,那么这个问题就应该好解决了,可以使用“&&”替代变量。
select &&inputGroupByColumn, sum(sal) from emp group by &inputGroupByColumn;
输入:job,job
使用“&&”的替代变量,只要求在第一次使用它的时候进行输入,如果再次使用,那么就不需要重复输入。
但是现在也会出现一个问题,如果现在输入的不再是job,而是deptno,那么就无法输入了,因为&&inputGroupByColumn在一个SESSION内只有一个值。所以有两种操作来解决此问题:第一种是关闭窗口重新打开,第二种是执行UNDEFINE命令:
UNDEFINE inputGroupByColumn;
然后就可以正常操作了。
如果不需要任何的替代变量的定义,那么可以输入set define off命令:
set define off;
在SQL*Plus中默认的"&"表示替代变量,也就是说,只要在命令中出现该符号,SQL*Plus就会要你输入替代值。这就意味着你无法将一个含有该符号的字符串输入数据库或赋给变量,如字符串“SQL&Plus”系统会理解为以“SQL”打头的字符串,它会提示你输入替代变量 Plus的值,如果你输入ABC,则最终字符串转化为“SQLABC”。
1.7 定义替代变量
在Oracle中除了可以使用“&&”定义替代变量之外,还可以使用DEFINE命令来定义替代变量,用户可以利用DEFINE创建一个字符型的替代变量,而且这种方式定义的替代变量会一直保存到一个SESSION的操作结束或者使用UNDEFINE清除变量。
DEFINE命令格式:
DEFINE 替代变量名称 = 值;
范例:DEFINE inputdname = 'ACCOUNTING';
查询替代变量的内容:DEFINE inputdname;
使用DEFINE定义的替代变量:select * from dept where dname = '&inputdname';
UNDEFINE命令格式:
清除inputdname替代变量内容:UNDEFINE inputdname;
1.8 替代变量——范例
定义一个替代变量:
DEFINE inputdname = 'ACCOUNTING';
查询此替代变量:
define INPUTDNAME;
输出:DEFINE INPUTDNAME = "ACCOUNTING" (CHAR)
使用此定义的替代变量:
select * from dept where dname = '&inputdname';
清除替代变量:
如果现在不再需要指定的替代变量,那么就使用undefine命令完成。
undefine inputdname;
1.9 ACCEPT命令
使用ACCEPT命令可以指定替代变量的提示信息。
ACCEPT语法格式:
ACCEPT 替代变量名称 [数据类型] [FORMAT 格式] [PROMPT '提示信息'] [HIDE]
ACCEPT语法中各个参数的作用如下所示:
替代变量名称:
存储值的变量名称,如果该变量不存在,则由SQL*Plus创建该变量,但是在定义此替代变量名称前不能加“&”。
数据类型:
可以是NUMBER、VARCHAR或者是DATE类型数据。
FORMAT格式:
指定格式化模型,例如A10或9.99。
PROMPT提示信息:
用户输入替代变量时的提示信息。
HIDE隐藏输入内容:
例如在输入密码时隐藏输入内容。
如果想要使用ACCEPT命令,那么必须结合脚本文件完成。
1.10 观察ACCEPT命令的操作
将以下命令保存为sql脚本,放到D盘根目录下,起名为wyc.sql:
accept inputEname PROMPT '请输入要查询信息的雇员姓名:'select empno, ename, job, hiredate, sal from emp where ename
= upper('&inputEname');
使用:@d:\wyc.sql命令执行sql脚本。
1.11 使用Accept定义替代变量
accept inputGroupByColumn PROMPT '请输入要分组的字段:' select &&inputGroupByColumn, sum(sal) from emp group by &inputGroupByColumn;
1.12 使用HIDE隐藏输入
现在发现所有输入的数据都被明文显示了,有时候不希望其他用户知道输入内容,可以使用HIDE进行隐藏:
accept inputGroupByColumn PROMPT '请输入要分组的字段:' HIDE select &&inputGroupByColumn, sum(sal) from emp group by &inputGroupByColumn;
1.13 使用FORMAT格式化输入
使用FORMAT限定输入的数据长度:
accept inputGroupByColumn PROMPT '请输入要分组的字段:' FORMAT A10 select &&inputGroupByColumn, sum(sal) from
emp group by &inputGroupByColumn;
A10表示输入数据长度不能超过10个字符。
使用FORMAT格式化输入格式:
accept inputDate DATE FORMAT 'yyyy-mm-dd' PROMPT '请输入要查询的日期:' select empno, ename, job, hiredate from emp where hiredate = to_date('&inputDate', 'yyyy-mm-dd');
需要注意的是ACCEPT命令不能换行,否则出错。
1.14 小结
使用替代变量可以提高数据操作的交互性。