Mac系统下, hadoop 2.6.2 完全分布式 配置
背景
本人最近在学习hadoop的相关内容,感觉在一个伪分布式环境下研究、学习总是感觉不伦不类的,于是想配一个基于OSX平台的完全分布式环境。在网上看了很多配置教程,发现几乎都是同时开三个虚拟机实现的三节点分布式环境,而我想用我的macbook作为master节点,并在此笔记本上开两个ubuntu虚拟机作为node1,node2节点,一番摸索下终于成功,特此写下此文章,以便不想完全用虚拟机作为分布式节点的同学分享交流。
参考链接:http://www.w2bc.com/Article/19645
环境
了解一些HDFS知识的同学应该清楚,从HDFS的角度来看,集群中的机器主要分为两种角色: NameNode和DataNode。此次配置的环境中,由macbook本身充当NameNode, 而两个虚拟机中运行的ubuntu系统分别充当两个DataNode。
- os x EI Capitan 10.11.5
- 虚拟机:Parallels Desktop
- ubuntukylin 14.04 64bit * 2
- hadoop 2.6.2
- os x上的jdk版本:1.8.0_73,ubuntu上的jdk版本:1.8.0_91(不同机器上的jdk版本不要求一样)
安装虚拟机
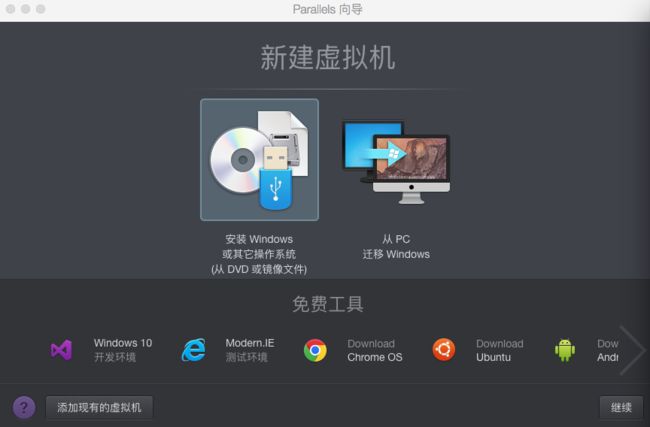
- 打开Parallels Desktop,点击右上角的“+”号添加虚拟机;
- 选择由现有的镜像文件添加系统还是自动下载,如图所示:
安装JDK
先检查在系统中是否安装有JDK,在控制台输入: java -version,如果出现如下提示,则证明本系统上已安装有JDK,否则需要自己手动安装。
mac系统上的JDK默认安装路径在:/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home,最好在ubuntu系统上也按如此路径存放JDK,如果对应的文件夹不存在,则自己在ubuntu上创建即可,不使用相同的路径也可,不过需要在各个ubuntu系统上的相关配置文件所有关于$JAVAHOME的位置更改为相应的JDK路径。
如果需要手动安装JDK,请自行搜索安装JDK的方法,同时配置好相应的环境变量。环境变量输入的位置在:/etc/profile下。
修改各自的hostname
为了方便起见,最好将三个系统上的hostname修改为:master(mac上)、node1(其中一个ubuntu系统上)、node2(另一个ubuntu系统)。
可以通过在控制台输入hostname来显示当前系统的hostname。
1. 在mac上设置hostname:在控制台输入
sudo scutil --set HostName master 2. ubuntu上设置hostname:
修改/etc/hostname文件,在其中把之前的名字删除,只留下node1(在另一个ubuntu上修改为node2)。
修改完hostname后,注销或重启一下系统,以使得新的hostname生效。之后可以通过在控制台输入 hostname 来验证hostname是否更改过来。
修改各个系统的hosts文件
此方法由于在Mac和ubuntu上步骤相同,所以统一说了,之后需要在每个机器上均执行此过程。
1. 使用ifconfig命令,查看各个系统的ip地址,并保证通过ping命令互相可以ping通,并记录各自的ip地址。或者,也可以通过手动方式指定各自系统的ip地址。
2. 修改/etc/hosts文件,在其中添加三条记录:master的IP地址 master,node1的IP地址 node1,node2的IP地址 node2。我自己的配置如下: 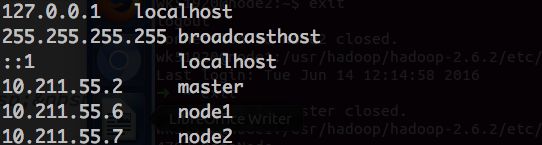
注意:此步骤需要在三个系统上均执行一遍,且填入的内容也相同。
安装及测试SSH
由于hadoop各个节点之间通过ssh方式进行通信,因此必须在各个系统上安装好ssh,并且为了避免每次登录均输入密码,还需要进行一定的配置实现ssh免密码登录。
1. 在控制台输入:ssh,如果出现如下提示,则证明本系统上已安装好了ssh,无须再去安装。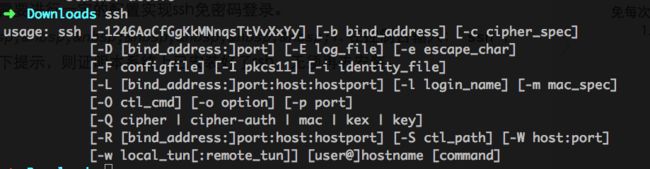
2. mac系统上已经默认安装了openSSH,如果ubuntu上没有安装,可参考如下方式安装:在控制台输入 sudo apt-get install openssh-server ,安装完成后在控制台输入:sudo service ssh start启动ssh服务。
3. 在控制台输入:ssh localhost 第一次登录会提示让你输入密码,最终显示Last login: ……表示登录成功。
配置ssh免密码登录
此过程在各个系统上均需要执行一遍。
1. 产生秘钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa此时会在~/.ssh文件夹下出现如下两个文件:id_dsa id_dsa.pub
2. 导入authorized_keys:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
#保证authorized_keys的chmod为6003. 测试是否安装成功:
#查看是否有sshd进程
ps -e | grep ssh
#尝试登录本地
ssh localhost4. 远程无密码登陆:
#进入master的.ssh目录
scp authorized_keys wk51920@node1:~/.ssh/authorized_keys_master
#wk51920是我目前在node1虚拟机上登录系统的用户名,建议三个系统使用相同的用户名
#进入node1、node2的.ssh目录
cat authorized_keys_master >> authorized_keys注意:第四步要在slave上重复,要使三者都能够无密码相互登录,重复完后可以利用如下命令试验,第一次需要输入密码绑定。
ssh node1并用同样的方式登录node2来测试是否可以免密码登录。需要实现三个系统之间互相能通过ssh方式免密码登录即算成功。实质就是:在各自.ssh文件夹下的authorized_keys中添加对方的id_dsa.pub公钥。
配置hadoop环境
此过程在master上配置。
1. 下载hadoop:http://hadoop.apache.org/releases.html;
2. 解压缩包:
#解压hadoop包
tar -zxvf hadoop压缩包名
#将安装包移到/usr目录下
mv hadoop解压后的文件夹 /usr/hadoop3. 新建文件夹:
#在/usr/hadoop目录下新建如下目录(root)
mkdir /dfs
mkdir /dfs/name
mkdir /dfs/data
mkdir /tmp 5. 配置文件:hadoop-env.sh(文件都在/usr/hadoop/etc/hadoop中)
修改JAVA_HOME值:
#注意此处是master中jdk的路径,也是mac系统的jdk安装路径,如果所有系统中jdk的路径均相同,则不用注意,否则需要在各自系统中,改为各自系统中jdk的路径。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home 6. 配置文件:yarn-env.sh
修改JAVA_HOME值:
#注意此处是master中jdk的路径,也是mac系统的jdk安装路径,如果所有系统中jdk的路径均相同,则不用注意,否则需要在各自系统中,改为各自系统中jdk的路径。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home 7. 配置文件:slaves
将内容修改为:
node1
node28. 配置文件:core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>hadoop.proxyuser.wk51920.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.wk51920.groupsname>
<value>*value>
property>
configuration>9. 配置文件:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/hadoop/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>10. 配置文件:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>11. 配置文件:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>12. 将hadoop传输到node1和node2根目录
#/usr/hadoop是master上hadoop的安装目录
#wk51920@node1:~/ 是:使用wk51920登录的hostname为node1的ubuntu系统上的~/目录
scp -r /usr/hadoop wk51920@node1:~/
scp -r /usr/hadoop wk51920@node2:~/
#如果在node1、node2中jdk的安装位置和master上不相同,则需要更改本系统上hadoop-env.sh和yarn-env.sh中的JAVA_HOME值。 13. 配置hadoop环境变量:
修改/etc/profile文件,在其中添加:
#root模式编辑/etc/profile
vim /etc/profile
#以上已经添加过java的环境变量,在后边添加就可以(注意此处是实际安装hadoop文件的路径,根据自己实际情况填写)
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin14. 启动hadoop
#注意最后单词带‘-’
hadoop namenode -format
start-all.sh15. 在master机器上输入
jps 如果显示如下几个进程表明成功:

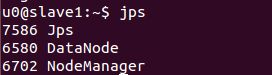
在node1、node2中分别输入
jps 如果现实如下几个进程表示成功:
执行测试程序wordcount
1. 进入到master的hadoop根目录(就是有README.txt的那个);
2. 在HDFS上创建input目录,用来存放README.txt文件:
hadoop fs -mkdir /input3. 将README.txt文件存入HDFS中的input文件夹下:
hadoop fs -copyFromLocal README.txt /input
#可通过hadoop fs -ls /input 命令查看是否成功将README.txt文件放入相应的HDFS文件夹。4. 进入/usr/hadoop/hadoop-2.6.2/share/hadoop/mapreduce文件夹下,执行:
#注意在执行此程序之前,在HDFS上一定不能存在output文件夹,如果存在,需要先删除
hadoop jar hadoop-mapreduce-examples-2.6.2.jar wordcount /input /output5. 查看程序运行结果:
hadoop fs -ls /output 显示结果如下:![]()
#通过此命令查看每个单词的统计结果
hadoop fs -cat /output/part-r-00000注意:执行hadoop命令时可能会提示:
![]()
这是由于使用的hadoopSDK是在32位的机器上编译的,而本机系统是64位造成的,想解决此提示,可以在本机上重新编译hadoop的SDK,如果不想编译,有此提示也不妨碍正常功能的使用!