爬取知乎碰到的问题-----------------------3、关于url中出现sign的解决办法

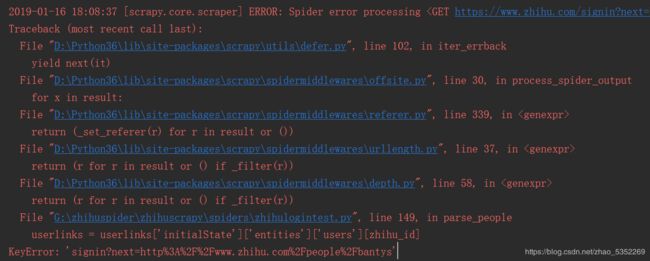
2019-01-16 18:08:37 [scrapy.core.scraper] ERROR: Spider error processing
Traceback (most recent call last):
File "D:\Python36\lib\site-packages\scrapy\utils\defer.py", line 102, in iter_errback
yield next(it)
File "D:\Python36\lib\site-packages\scrapy\spidermiddlewares\offsite.py", line 30, in process_spider_output
for x in result:
File "D:\Python36\lib\site-packages\scrapy\spidermiddlewares\referer.py", line 339, in
return (_set_referer(r) for r in result or ())
File "D:\Python36\lib\site-packages\scrapy\spidermiddlewares\urllength.py", line 37, in
return (r for r in result or () if _filter(r))
File "D:\Python36\lib\site-packages\scrapy\spidermiddlewares\depth.py", line 58, in
return (r for r in result or () if _filter(r))
File "G:\zhihuspider\zhihuscrapy\spiders\zhihulogintest.py", line 149, in parse_people
userlinks = userlinks['initialState']['entities']['users'][zhihu_id]
KeyError: 'signin?next=http%3A%2F%2Fwww.zhihu.com%2Fpeople%2Fbantys'
解决办法:
在试了几次之后发现这个链接url,放到知乎的页面会显示该用户已停用,找不到该用户,但是有时候你直接复制的id,也会出现这种问题,所以目前就是直接将访问不到的记录下来,放到文件做最后的处理。
