AutoDL论文解读(三):基于层或块的搜索
自动化机器学习(AutoML)最近变得越来越火,是机器学习下个发展方向之一。其中的神经网络结构搜索(NAS)是其中重要的技术之一。人工设计网络需要丰富的经验和专业知识,神经网络有众多的超参数,导致其搜索空间巨大。NAS即是在此巨大的搜索空间里自动地找到最优的网络结构,实现深度学习的自动化。自2017年谷歌与MIT各自在ICLR上各自发表基于强化学习的NAS以来,已产出200多篇论文,仅2019年上半年就有100多篇论文。此系列文章将解读AutoDL领域的经典论文与方法,笔者也是刚接触这个领域,有理解错误的地方还请批评指正!
此系列的文章:
- AutoDL论文解读(一):基于强化学习的开创性工作
- AutoDL论文解读(二):基于遗传算法的典型方法
- AutoDL论文解读(三):基于块搜索的NAS
- AutoDL论文解读(四):权值共享的NAS
- AutoDL论文解读(五):可微分方法的NAS
- AutoDL论文解读(六):基于代理模型的NAS
- AutoDL论文解读(七):基于one-shot的NAS
本篇介绍两篇论文:谷歌的《Learning Transferable Architectures for Scalable Image Recognition》,商汤的《Practical Block-wise Neural Network Architecture Generation》。前两篇博文介绍的方法都是从最简单的初始化网络一点一点地增加基本操作如卷积、池化等,这样搜索空间巨大非常耗时。这里介绍的两篇论文是以搜索基本的层结构或块结构为主要目的,然后重复堆叠这些基本结构组成最终的网络。这相当于增加了先验知识,也较少了搜索空间,速度会比之前的方法快。
一、Learning Transferable Architectures for Scalable Image Recognition
1、引言
本文提出的方法叫做NASNet,是基于《Neural Architecture Search with Reinforcement Learning》(NAS)这篇论文的。直接用NAS在巨大的数据集上比如ImageNet是非常耗时的,因此作者提出现在小数据集上比如CIFAR-10上搜索,然后将搜索到的结构迁移至大数据及上。作者为了实现这种可迁移性,设计了新的搜索空间(称作NASNet搜索空间),使网络的复杂性与网络的深度和输入图像的大小无关。并且,搜索空间中的所有卷积网络都是由结构相同但权重不同的卷积层(或cell)组成的,搜索网络结构就相当于搜索最好的cell。搜索cell会比搜索整个结构更快,而且cell结构更容易泛化。
2、Normal cell 和 Reduction cell
在此方法中,卷积网的整体架构是人工确定的。它们由重复多次的卷积cell组成,每个卷积cell具有相同的结构,但是不同的权重。用控制器RNN去预测卷积cell,然后将卷积cell按顺序堆叠,以处理任意大小的输入和过滤器的深度。这里作者指定两种类型的卷积cell:(1)Normal cell,输入和输出的特征图维度相同;(2)Reduction cell,输出特征图长宽减半。当降低特征图大小时,将输出中的过滤器数量增加一倍,以保持大致恒定的隐藏状态维数。
3、搜索步骤
在搜索空间里,每个cell接受两个初始的隐藏状态 h i h_{i} hi和 h i − 1 h_{i-1} hi−1,他们是前面两个较低层中的两个cell的输出或输入图像。给定这两个隐藏状态,控制器RNN循环地预测对他们的操作,如下图所示:

在图左边是控制器RNN,会预测5种操作,灰色的两个框是选择哪两个隐藏状态,黄色的两个框是选择对两个隐藏状态的操作比如卷积或池化,绿色的框是选择连接两个隐藏状态的方式。右边是预测出来的一个例子,这样的一个结构称为block,然后连续预测B次,形成B个block,组成一个卷积cell。也就是说,一个卷积cell里有B个这样的block。RNN的预测步骤可以总结如下:

下图是预测出来的两种cell结构,作者选择B=5,可以看出每个cell都由5个block组成:
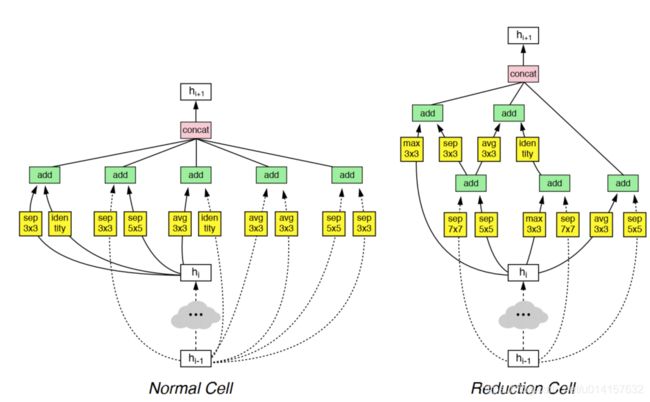
关于隐藏空间的选择,具体如下图所示:
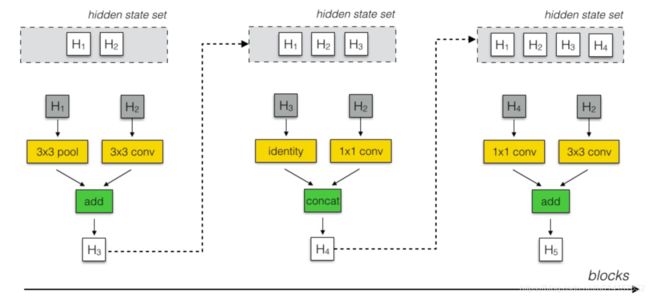
在最左边的图,初始会有两个隐藏状态H1和H2,RNN预测出一个block,H1和H2分别经过3X3 pool和3X3 conv再相加,得到H3,然后H1、H2和H3作为下一步预测的初始状态集合,从中选择两个初始状态作为下个block的输入。在中间这个图,选择了H3和H2,然后预测出block的结构,得到H4,连同H1、H2和H3作为下一步预测的初始状态集合,以此类推。为了使控制器RNN能预测出Normal cell 和 Reduction cell,作者让RNN总共有2X5XB个预测,前5XB个预测的是Normal cell,后5XB个预测的是Reduction cell。
4、搜索空间
在上述的 step 3 和 step 4 中,RNN需要选择对隐藏状态的操作,这里预定义的操作包括如下几种:

在 step 5 中需要选择对两个隐藏状态的连接方式,这里包括两种:(1)元素相加;(2)沿深度这个轴组合两个隐藏状态。最后,在cell里没有被用到的隐藏状态沿深度这个轴组合起来作为cell的输出。
其他关于搜索空间的细节:所有的卷积都使用ReLU激活函数;为了保证卷积cell的形状匹配,必要情况下会插入1X1的卷积;所有深度可分离卷积都不采用批归一化和(或)深度分离卷积和元素操作之间的ReLU;所有的卷积遵循ReLU、卷积操作、批归一化这样的顺序;当一个可分离卷积作被选为操作时,可分离卷积被两次应用于隐藏状态,作者发现这可以提高整体性能。
5、训练
不同于NAS方法,这里的控制器RNN是用近端策略优化(Proximal Policy Optimization,PPO)算法,PPO算法实现过程简单同时具有优秀的性能,使用PPO速度比较快且稳定。
在学习了卷积cell之后,可以探索几个超参数来构建给定任务的最终网络:(1)cell重复数N;(2)初始卷积cell中的滤波器数目。在选择了初始过滤器的数量之后,在步幅为2时将过滤器的数量增加一倍。作者定义了一个简单的符号来表示所有网络中的这两个参数,例如,4 @ 64,其中4和64分别表示网络倒数第二层的细胞重复数和过滤器数。
控制器RNN是一个一层的100个隐层单元的LSTM,有2X5XB个softmax预测。
在训练时,作者还使用了ScheduledDropPath策略,这是DropPath 策略的改进版本。在DropPath中,cell内的每条路径在训练过程中以一定的概率随机丢弃。而在ScheduledDropPath中,cell中的每条路径都以一个在训练过程中线性增加的概率被删除。作者发现DropPath并不能很好地用于NASNet,而ScheduledDropPath在实验中显著提高了NASNet的最终性能。
二、Practical Block-wise Neural Network Architecture Generation
1、引言
大多数的现代网络如Inception、残差网络等都是block堆叠的结构,作者也以生成block为基础,堆叠这些块来生成网络。这里的block和上篇论文里的block不太一样,这里的block结构上相当于上篇里的cell。作者使用Q-learning、经验回放、epsilon-贪婪策略等方法去生成block结构,然后生成整个网络。作者还提出了一种早停策略,以加快搜索收敛。重新设计了奖励函数,使早停的网络的准确率和充分训练的网络的准确率有正相关性。相当于用此奖励函数去预测最终的准确率。
2、Network Structure Code
为了将网络表示成有向无环图,作者提出了一种新的层表示方法,称作network structure code(NSC),如下表所示:
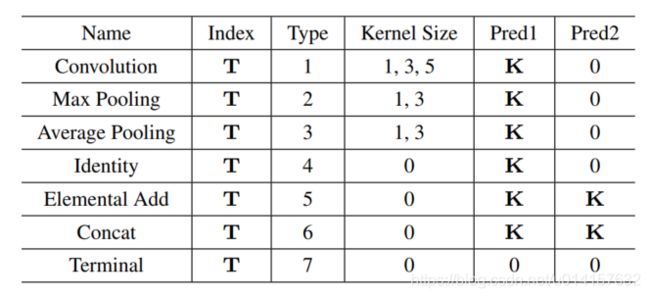
每个block用一个5-D的NSC向量集合表示。表中index表示层的编号, T = { 1 , 2 , 3 , … , M a x L a y e r I n d e x } T= \{1,2,3, \dots , {\rm Max LayerIndex} \} T={1,2,3,…,MaxLayerIndex},每个block里有多个层,每个层有唯一有序的编号,每个block有MaxLayerIndex个层。Type表示层的类型,如表中所示1表示卷积层,2表示最大池化层,3表示平均池化层,等等。Kernel Size只在卷积层和池化层里有。Pred1和Pred2表示连接到当前层的层编号, k = { 1 , 2 , 3 , … , M a x L a y e r I n d e x − 1 } k= \{1,2,3, \dots , {\rm Max LayerIndex-1} \} k={1,2,3,…,MaxLayerIndex−1} ,如pred1=1表示编号为1的层连接到了当前层,若只有一个层连接到当前层,则pred2=0。NAS的例子可以看下图:
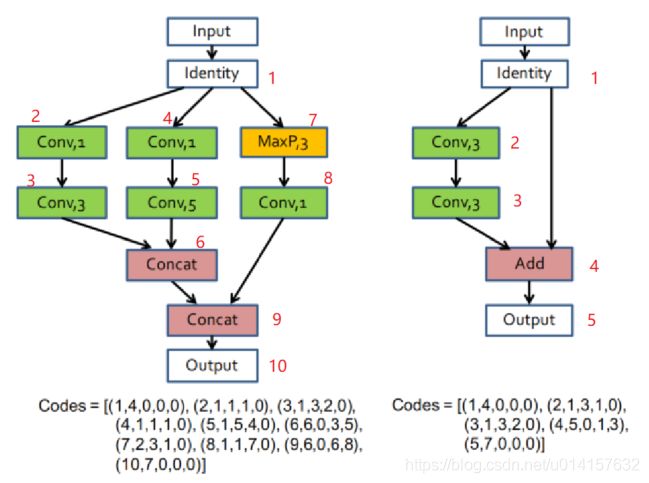
上图中每个层我用红色数字表上了号,和codes里的编号是一致的。以左图的codes为例,(1,4,0,0,0)表示编号为1,此层类型为4即Identity,没有kernel size,没有被连接的层(实际上它是此block的第一个层,默认pred1和pred2为0);(2,1,1,1,0)表示编号为2,此层类型为1即Convolution,kernel size为1,编号为1的层连接到此层;以此类推。
此外,block里所有没有后继连接的层都被连接起来作为输出。所有的Convolution都为Pre-activation Convolution Cell(PCC),即包括ReLU、卷积、批归一化三个部分。
2、Q-learning
在这篇论文里, s ∈ S s \in S s∈S表示当前层的NSC,是个5-D向量:{later index,layer type,kernel size,pred1,pred2}。动作 a ∈ A a \in A a∈A是下一个层的决策。状态转移的过程 ( s t , a ( s t ) ) → ( s t + 1 ) (s_{t}, a(s_{t})) \rightarrow (s_{t+1}) (st,a(st))→(st+1)如下图所示:
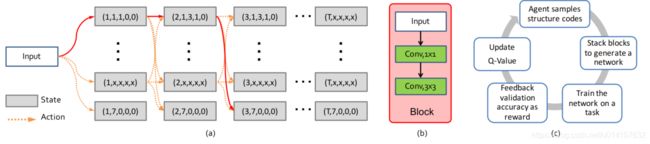
图(b)是沿图(a)中的红线生成的,block的结构可以看做一个NSCs序列的动作选择策略 T a 1 : T {\mathcal T}_{a1:T} Ta1:T,选择的过程是马尔科夫决策过程,基于在一个block中表现好的层在另一个层中也应该表现好的假设。为了找到最优结构,这里最大化所有搜索轨迹的期望奖励:
R T = E P ( T a 1 : T ) [ R ] R_{\mathcal T}={\Bbb E}_{P({\mathcal T}_{a1:T})}[{\Bbb R}] RT=EP(Ta1:T)[R]
R \Bbb R R是累积的奖励。使用贝尔曼方程取解这个最大化问题,这里给出了迭代解法:
Q ( s T , a ) = 0 Q ( s T − 1 , a T ) = ( 1 − α ) Q ( s T − 1 , a T ) + α r T Q ( s t , a ) = ( 1 − α ) Q ( s t , a ) + α [ r t + γ max a ′ Q ( s t + 1 , a ′ ) ] , t ∈ { 1 , 2 , … T − 2 } \begin{aligned} Q\left(s_{T}, a\right) &=0 \\ Q\left(s_{T-1}, a_{T}\right) &=(1-\alpha) Q\left(s_{T-1}, a_{T}\right)+\alpha r_{T} \\ Q\left(s_{t}, a\right) &=(1-\alpha) Q\left(s_{t}, a\right) +\alpha\left[r_{t}+\gamma \max _{a^{\prime}} Q\left(s_{t+1}, a^{\prime}\right)\right], t \in\{1,2, \ldots T-2\} \end{aligned} Q(sT,a)Q(sT−1,aT)Q(st,a)=0=(1−α)Q(sT−1,aT)+αrT=(1−α)Q(st,a)+α[rt+γa′maxQ(st+1,a′)],t∈{1,2,…T−2}
α \alpha α是学习率,决定新信息所占的比例, γ \gamma γ是折扣因子,决定长期奖励的重要性。 r t r_{t} rt表示在当前状态 s t s_{t} st下的奖励, s T s_{T} sT是最终状态,也就是NSC里的Terminal层。 r T r_{T} rT是针对 a T a_{T} aT后整个网络训练收敛后验证集的准确率。由于奖励 r t r_{t} rt不能在我们的任务中明确测量,我们使用下式来加速训练:
r t = r T T r_{t}=\frac{r_{T}}{T} rt=TrT
而之前的一些工作将 r t r_{t} rt设置成了0,这会使收敛变慢,这就是所谓的时间信用分配问题,这使得强化学习非常耗时。
3、早停策略
按搜索block的方式生成网络确实可以有效地加速搜索,但整个搜索过程还是比较费时的。为了加速学习过程,作者使用了早停策略。早停策略可能会导致准确率比较低。如下图所示:

图中黄色的线是使用早停的准确率,橘色的线是训练收敛后的准确率,使用早停的准确率要低很多。同时从图中发现,FLOPs、block的密度和最终准确率成负相关。因此,最终定义奖励函数为:
reward = A C C Earlystop − μ log ( FLOPs ) − ρ log ( Density ) \begin{aligned} \text {reward}=\mathrm{ACC}_{\text {Earlystop }} &-\mu \log (\text { FLOPs }) \\ &-\rho \log (\text { Density }) \end{aligned} reward=ACCEarlystop −μlog( FLOPs )−ρlog( Density )
FLOPs是block计算复杂度的估计,Density是block这个有向无环图中边数比上顶点数。
4、训练细节
- epsilon-贪婪策略:这里作者根据下表来逐渐降低epsilon值,使智能体从探索平滑地过度到利用:

- 经验回放:在每一次迭代后存储验证集准确率和block的描述。在每一次训练迭代里,智能体从经验回放采样64个block以及对应的验证集准确率,更新Q值64次。
- BlockQNN生成:在更新过程中,学习率 α = 0.01 \alpha=0.01 α=0.01,折扣因子 γ = = 1 \gamma ==1 γ==1,奖励函数中的参数 μ = 1 , ρ = 8 \mu =1, \rho=8 μ=1,ρ=8。智能体一次采样64个NSC的集合作为一个mini-batch,一个block里的最大层编号为23。训练智能体178轮,也就是说一共会采样178*64=11392个block。对于每个生成的完整的网络,训练12轮。在得到一个最优的块结构后,我们用堆叠的块构建整个网络,并对网络进行训练直到收敛,以验证集准确率作为选择最优网络的标准。
参考文献
[1] Zoph B, Vasudevan V, Shlens J, et al. Learning Transferable Architectures for Scalable Image Recognition[J]. 2017.
[2] Zhong Z , Yang Z , Deng B , et al. BlockQNN: Efficient Block-wise Neural Network Architecture Generation[J]. 2018.
[3] http://baijiahao.baidu.com/s?id=1600615825111400186&wfr=spider&for=pc
[4] https://wenku.baidu.com/view/eb78122d814d2b160b4e767f5acfa1c7aa008292.html
