Python学习笔记--Python 爬虫入门 -18-3 Scrapy架构+案例(IT之家)
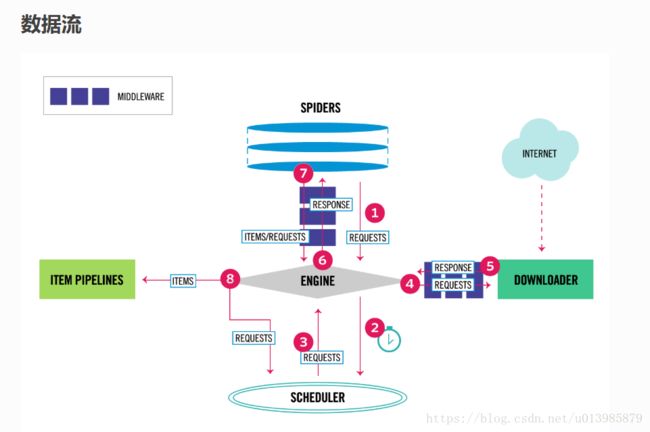 图1.png
图1.png
图片来源:https://doc.scrapy.org/en/master/topics/architecture.html
下面的流程图或许更清晰:
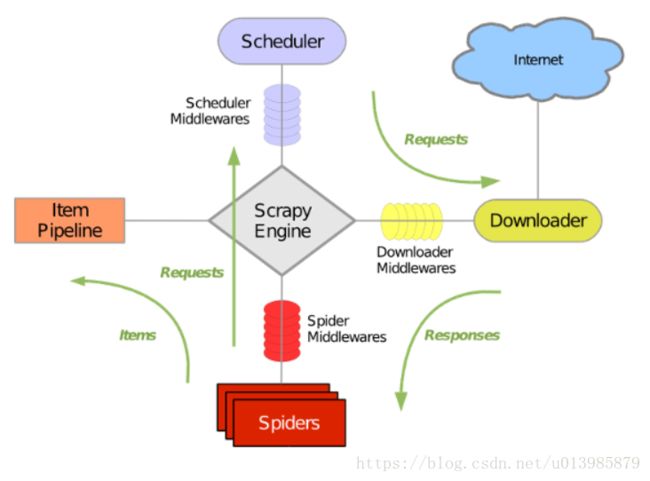 图2.png
图2.png
Scrapy主要包括了以下组件:
-
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
- 引擎(Scrapy)
Scrapy运行流程大概如下:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器),用于接下来的抓取
2.Scheduler (排序,入队) 处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)把URL封装成一个请求(Request)交给Downloader。
3.Downloader向互联网发送请求,接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders解析response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取出url重新经ScrapyEngine交给Scheduler进行下一个循环。把URL交给调度器等待抓取
Scrapy 如何帮我们抓取数据呢:
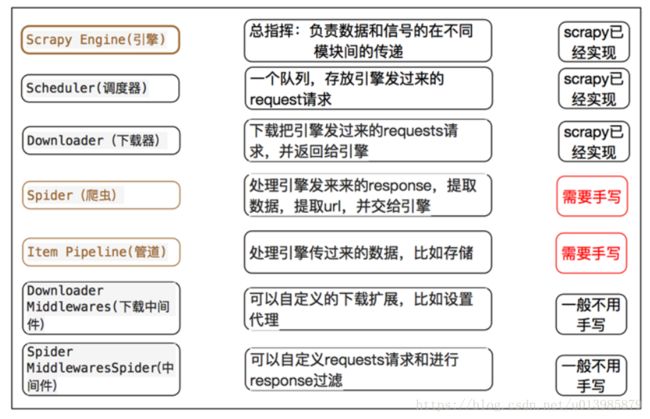 图3.png
图3.png
参考:https://www.cnblogs.com/x-pyue/p/7795315.html
案例:
一.爬取IT之家
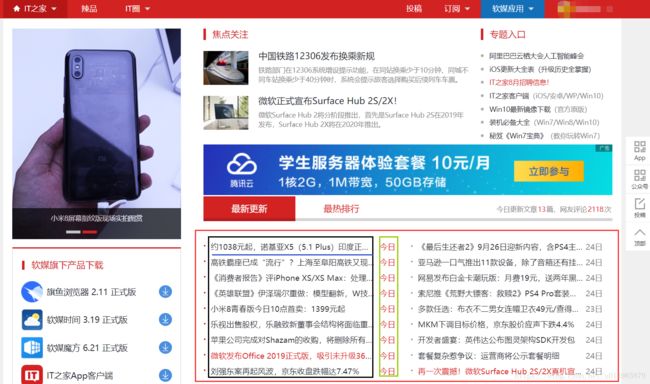
需求:获取正文内容的时间+新闻主题+url
scrapy环境搭建不再细说,若有问题请查看
Python学习笔记--Python 爬虫入门 -18-1 Scrapy
Python学习笔记--Python 爬虫入门 -18-2 Scrapy-shell
1.>scrapy startproject scrapy_project

2.>cd scrapy_project
>scrapy genspider ithome_spider ithome.com
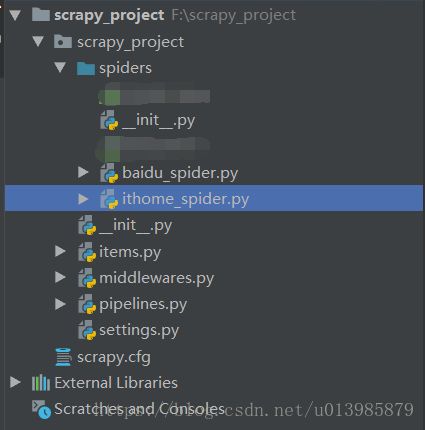
3.请看如上图3.png所示:编写spider爬虫
# -*- coding: utf-8 -*-
import scrapy
from scrapy_project.items import ScrapyProjectItem
class IthomeSpiderSpider(scrapy.Spider):
name = 'ithome_spider'
allowed_domains = ['ithome.com']
start_urls = [
# 'https://www.ithome.com/html/it/385033.htm',
'https://ithome.com'
]
def parse(self, response):
bodydata = response.xpath('//div[@class="lst lst-1 new-list"]')
for i in bodydata:
item = ScrapyProjectItem()
# class='block 6645 new-list-1'
list1 = i.xpath("div[@class]")
for j in list1:
li_li_list = j.xpath("ul/li")
for k in li_li_list:
item['tdate1'] = k.xpath("span[@class='date']/text()").extract()[0]
item['title_url1'] = k.xpath("span/a/@href").extract()
item['title1'] = k.xpath("span/a[@href]/text()").extract()
print("tdate1=",item['tdate1'],)
print("title_url1=", item['title_url1'])
print("title1=", item['title1'])
print("*"*20)
yield itemitems.py 文件
class ScrapyProjectItem(scrapy.Item):
# define the fields for your item here like:
tdate1 = scrapy.Field()
title1 = scrapy.Field()
title_url1 = scrapy.Field()4.运行爬虫 scrapy crawl ithome_spider
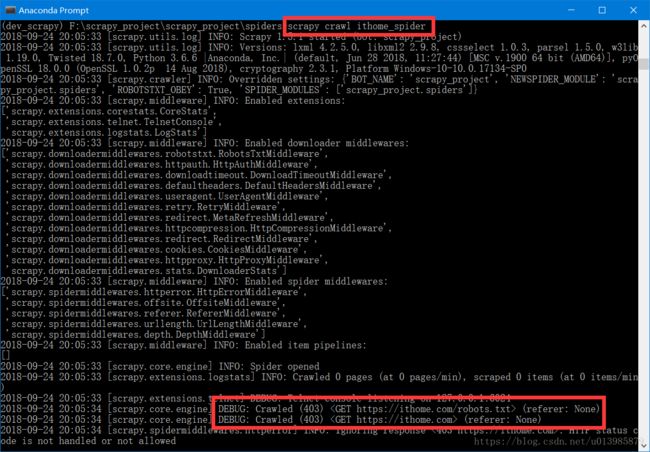
5.出现如此信息,说明需要设置headers,伪装一下爬虫
请先参考一下这个文章 Python学习笔记--Python 爬虫入门 -18-2 Scrapy-shell
此处需要设置一下settings 文件 把DEFAULT_REQUEST_HEADERS 注释放开
DEFAULT_REQUEST_HEADERS = {
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}6.运行 scrapy crawl ithome_spider

7.现在有个新需求,怎么保存到本地(Pipeline 负责持久化)
pipelines.py
# -*- coding: utf-8 -*-
import json
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class ScrapyProjectPipeline(object):
def __init__(self):
self.filename=open(r'E:\0802\data\home.json','wb')
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False)+",\n" #ensure_ascii=False 注意
self.filename.write(text.encode("utf-8"))
# return item
def close_spider(self,spider):
self.filename.close()8.注意:settings.py 以下注释放开,不然pipeline 不生效
ITEM_PIPELINES = {
'scrapy_project.pipelines.ScrapyProjectPipeline': 300,
}9.在运行 >>scrapy crawl ithome_spider
生成json文件,部分截图如下
