BERT(Bidirectional Encoder Representation from Transformers)及其发展史
文章参考了比较多博客,直接想了解bert的,可以直接看 2.Bert细则
文章目录
- 1. word2vec,ELMo,BERT亮点与区别
- 1.1 发展史
- word2vec——>ELMo
- ELMo——>BERT
- 1.2. Elmo
- 优点
- 不足
- 1.3. Bert
- 特点
- 1.4. 三者对比
- 2. BERT细则
- 2.1. Masked Language Model
- 2.2 Next Sentence Predictio(NSP)
- 2.2. Transformer —— attention is all you need
- 2.2.1. multi-head attention
- 2.2.2. self-attention
- 2.2.3. position encoding
- 2.3. sentence-level representation
- 2.3.1. 句子级负采样
- 2.3.2. 句子级表示
- 3. 迁移策略
- 4. 运行结果
- 4.1. GLUE数据集-句子关系判断及分类
- 4.2. SQuAD抽取式任务-CoNLL2003命名实体识别
- 4.3. SWAG-分类任务
- 5. [BERT的可能改进方向](http://baijiahao.baidu.com/s?id=1647838632229443719&wfr=spider&for=pc)(from 张俊林)
- 5.1. 文本生成模型
- 5.2. 结构化知识引入
- 5.3. 多模态融合
- 5.4. 更大、更高质量的训练数据
- 5.5. 更合适的训练目标和训练方法
- 5.6. 多语言融合
- 6. 探寻黑盒系统的方法
- 6.1. 可视化(2D t-SEN),用2D图的方式展示
- 6.2. Attention图
- 6.3. Probing Classifier
- 6.4. Edge Probing Classifier
- 6. 参考文献
1. word2vec,ELMo,BERT亮点与区别
1.1 发展史

word2vec——>ELMo
结果:上下文无关的static向量变成上下文相关的dynamic向量,比如苹果在不同语境vector不同。
操作:encoder操作转移到预训练产生词向量过程实现。
ELMo——>BERT
结果:训练出的word-level向量变成sentence-level的向量,下游具体NLP任务调用更方便,修正了ELMo模型的潜在问题(ELMo模型在与下游具体NLP任务拼接时需要每层加上权重做全局池化,BERT可以直接获得一整个句子的唯一向量表示)。
操作:使用句子级负采样获得句子表示/句对关系,Transformer模型代替LSTM提升表达和时间上的效率,masked LM解决“自己看到自己”的问题。
- 负采样
由于训练词向量模型的目标不是为了得到一个多么精准的语言模型,而是为了获得它的副产物——词向量。所以要做到的不是在几万几十万个token中艰难计算softmax获得最优的那个词(就是预测的对于给定词的下一词),而只需能做到在几个词中找到对的那个词就行,这几个词包括一个正例(即直接给定的下一词),和随机产生的噪声词(采样抽取的几个负例),就是说训练一个sigmoid二分类器,只要模型能够从中找出正确的词就认为完成任务。
这种负采样思想也应用到之后的BERT里,只不过从word-level变成sentence-level,这样能获取句子间关联关系。
1.2. Elmo
- 2018年8月发布
- 上下文无关模型
- encoder模型是Bi-LSTM
优点
- 双向
不足
- 不完全双向
是指模型的前向和后向LSTM两个模型是分别训练的,前向遍历一遍获得左边的LSTM,后向遍历一遍获得右边的LSTM,最后得到的隐层向量直接拼接得到结果向量,在最后的Loss function中也是前向和后向的loss function直接相加,并非完全同时的双向计算。 - 自己看见自己
双向模型会导致预测的下一词已经在给定序列中出现了的问题,这就是“自己看见自己”。
1.3. Bert
BERT模型进一步增加词向量模型泛化能力,充分描述字符级、词级、句子级甚至句间关系特征。
特点
-
真正的双向encoding
Masked LM,类似完形填空,尽管仍旧看到所有位置信息,但需要预测的词已被特殊符号代替,可以放心双向encoding。 -
Transformer做encoder实现上下文相关(context)
使用transformer而不是bi-LSTM做encoder,可以有更深的层数、具有更好并行性。并且线性的Transformer比lstm更易免受mask标记影响,只需要通过self-attention减小mask标记权重即可,而lstm类似黑盒模型,很难确定其内部对于mask标记的处理方式。 -
提升至句子级别
学习句子/句对关系表示,句子级负采样。首先给定的一个句子,下一句子正例(正确词),随机采样一句负例(随机采样词),句子级上来做二分类(即判断句子是当前句子的下一句还是噪声),类似word2vec的单词级负采样。
1.4. 三者对比
| 模型 | 预训练encoding(上下文相关) | 模型 | 预测目标 | 下游具体任务 | 负采样 | 级别 |
|---|---|---|---|---|---|---|
| word2vec | No | CBOW/Skip-Gram | next word | 需要encoding | Yes | word-level |
| Elmo | Yes | bi-lstm | next word | 需要设置每层参数 | No | word-level |
| Bert | Yes | Transformer | masked | 简单MLP | Yes | sentence-level |
2. BERT细则
介绍Bert的三个亮点:Masked LM / transformer / sentence-level
2.1. Masked Language Model
随机mask语料中15%的token(所以训练很慢),最终隐层向量送入softmax,来预测masked token。
Input : The man went to [MASK] store with [MASK] dog
Target: the his
对于盖住词的特殊标记,在下游NLP任务中不存在。因此,为了和后续任务保持一致,作者按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。如:my dog is hairy
- 有80%的概率用“[mask]”标记来替换——my dog is [MASK]
- 有10%的概率用随机采样的一个单词来替换——my dog is apple
- 有10%的概率不做替换——my dog is hairy
2.2 Next Sentence Predictio(NSP)
为了让模型捕捉两个句子的联系,这里增加了Next Sentence Prediction的预训练方法,即给出两个句子A和B,B有一半的可能性是A的下一句话,训练模型来预测B是不是A的下一句话.
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
训练模型,使模型具备理解长序列上下文的联系的能力
2.2. Transformer —— attention is all you need
transformer模型结构
- 左边Nx框框的encoder
- 右边Nx框框的decoder
- attention(上边的一个橙色框)
- self-attention(下边的两个橙色框)
- position encoding加入没考虑过的位置信息
一个老外的讲解 transformer link
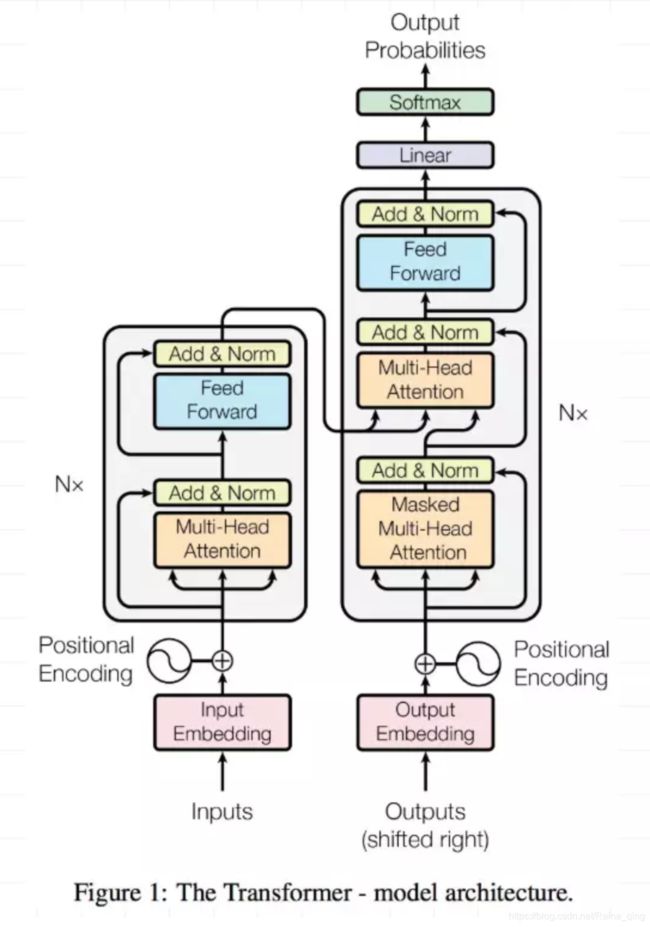
2.2.1. multi-head attention
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
2.2.2. self-attention
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。
2.2.3. position encoding
transformer计算token的位置信息这里使用正弦波↓,类似模拟信号传播周期性变化。这样的循环函数可以一定程度上增加模型的泛化能力。
但BERT直接训练一个position embedding来保留位置信息,每个位置随机初始化一个向量,加入模型训练,最后就得到一个包含位置信息的embedding(简单粗暴。。),最后这个position embedding和word embedding的结合方式上,BERT选择 直接拼接。
2.3. sentence-level representation
在很多任务中,仅仅靠encoding是不足以完成任务的(这个只是学到了一堆token级的特征),还需要捕捉一些句子级的模式,来完成SLI、QA、dialogue等需要句子表示、句间交互与匹配的任务。
2.3.1. 句子级负采样
句子级别的连续性预测任务,即预测输入BERT的两端文本是否为连续的文本。训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。在该sentence-level上来做二分类(即判断句子是当前句子的下一句还是噪声)。
2.3.2. 句子级表示
它在每个input前面加一个特殊的记号[CLS],然后让Transformer对[CLS]进行深度encoding,由于Transformer是可以无视空间和距离的把全局信息encoding进每个位置的,而[CLS]的最高隐层作为句子/句对的表示直接跟softmax的输出层连接,因此其作为梯度反向传播路径上的“关卡”,可以学到整个input的上层特征。 看不懂!!!
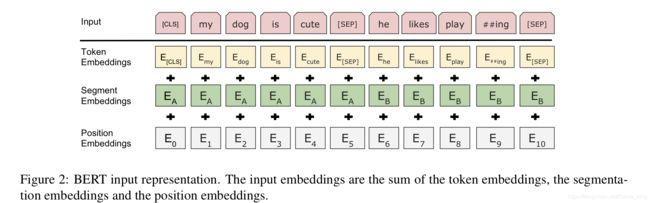
如下图所示,最终输入结果会变成下面3个embedding 拼接 的表示。
3. 迁移策略

- a——句子关系判断(句对匹配)
MultiNLI文本蕴含识别(M推理出N,蕴含/矛盾/中立),QQP(文本匹配),QNLI(自然语言问题推理),STS-B(语义文本相似度1-5),MRPC(微软研究释义语料库,判断文本对语音信息是否等价)、RTE(同MNLI,小数据),SWAG(113k多项选择问题组成的数据集,涉及丰富的基础情境)
- b——分类任务(文本匹配):
SST-2(斯坦福情感分类树),CoLA(语言可接受性预测)
对于左三图抽取式任务,用两个线性分类器分别输出span的起点和终点
- c——序列标注(文本抽取):
SQuAD(斯坦福问答数据集,从phrase中选取answer)
对于左四图序列标注任务,就只需要加softmax输出层
- d——序列标注:
NER命名实体识别
4. 运行结果
4.1. GLUE数据集-句子关系判断及分类
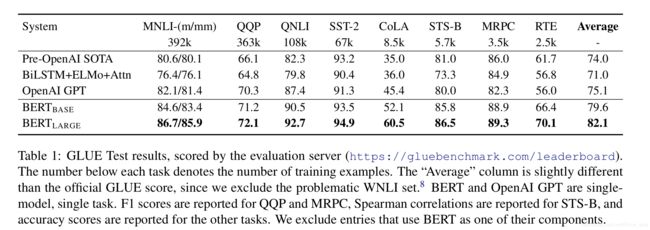
4.2. SQuAD抽取式任务-CoNLL2003命名实体识别

4.3. SWAG-分类任务

只在生成式任务中留了活路。
5. BERT的可能改进方向(from 张俊林)
5.1. 文本生成模型
5.2. 结构化知识引入
5.3. 多模态融合
5.4. 更大、更高质量的训练数据
5.5. 更合适的训练目标和训练方法
5.6. 多语言融合
6. 探寻黑盒系统的方法
6.1. 可视化(2D t-SEN),用2D图的方式展示
用Transformer的每层的特征,各自把名词、短语进行聚类,同一颜色代表同一类的短语,如果聚类效果好,说明这层编码了这类知识。通过这种方法,进而知道哪一层适合解决什么问题,编码哪些知识,这是典型的可视化方法。
6.2. Attention图
对探索Transformer所学到知识的探寻手段来说,Attention图是非常关键的方法,它可以形象地观察一个单词和其它单词的关系,联系的紧密程度。如下图所示,看一看介词’at’和谁的关系更密切?连接线越粗,表示联系越紧密,值越大边就画得更粗一点,发现跟’Auction’更粗,证明了BERT学到了介词和主名词之间的关系,更重要是通过Attention图的方式能够知道学到了哪些知识。
6.3. Probing Classifier
对于Transformer某一层某个单词的Embedding节点,如果想知道它学到了什么东西,怎么做?
我们把Transformer结构参数固定住,保持不变,知识已经编码在参数中,最高层Transformer对应的单词有个Embedding,在上面加入一个小分类网络,这个网络结构很简单,我们不希望它自身学习过多的知识,只希望它利用Transformer已经编码好的知识去进行词性标注,如果能标注正确,表明Transformer这一层已经编码学到了词性标注相关知识,如果标注错误表明没有编码这个知识。
6.4. Edge Probing Classifier
它和Probing Classifier的区别是: Probing Classifier只能判断一个单词对应的Embedding节点学到了什么,而它能够同时侦测多节点编码的知识。通过Edge Probing Classifier方式, Transformer仍然固定参数,简单分类器的输入变成多节点输入,上面的Span可能覆盖一个片段,如一个单词,两个单词,然后构建一个简单的分类器解决分类任务,进而观测预测的精准性,根据预测准确性,来获知到底学到了什么知识。
6. 参考文献
https://mp.weixin.qq.com/s/pCRpVwUI7uFaFXWNRO-bKQ