分布式发布订阅消息系统Kafka--
文章目录
- Kafka概述
- 名词解释
- 应用场景
- kafka的特点
- Kafka架构及核心概念
- Kafka单节点单Broker部署之Zookeeper安装
- 单节点单Broker部署
- 单节点多Broker部署及使用
- Kafka容错性测试
- 在scala-maven的IDEA下Kafka Java API编程测试
- Kafka实战之整合Flume和Kafka完成实时数据采集
Kafka概述
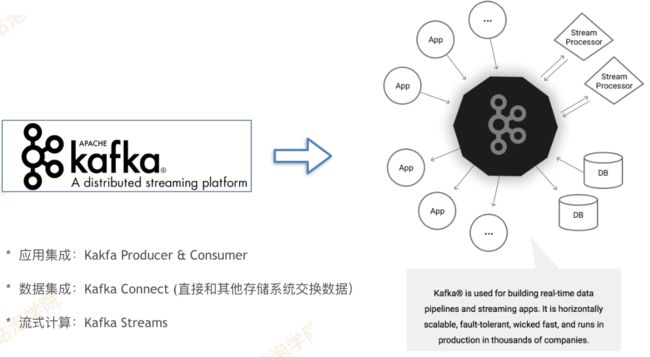
Kafka最初是LinkedIn公司开发的MQ系统,未来的⽬目标是打造成⼀一站式流式数据处理理平台
- kafka是世界著名作家的名字(弗兰兹·卡夫卡),代表作:《变形记》
- 2010年年底,Kafka作为开源项⽬目在GitHub上发布。
- 2011年年7⽉月,成为Apache的孵化器器项⽬目。
- 2012年年10⽉月,Kafka从孵化器器项⽬目毕业。
- 2014年年秋,原创团队离开LinkedIn,创办Confluent。
- 最新版本:2.0.0,源码⽤用Scala开发
- Apache⽹网址:http://kafka.apache.org
- Confluent⽹网址:https://www.confluent.io
卡夫卡是用于构建实时数据管道和流媒体应用。它是水平可伸缩的,容错的,快速的,并运行在数千家公司的生产。
- PUBLISH & SUBSCRIBE
像消息传递系统一样读写数据流。 - PROCESS
编写可伸缩的流式处理应用程序,实时响应事件。 - STORE
存储数据流安全分布,复制。容错集群。
Kafka概述和消息系统类似
消息中间件:生产者和消费者
妈妈:生产者
你:消费者
馒头:数据流、消息
正常情况下: 生产一个 消费一个
其他情况:
一直生产,你吃到某一个馒头时,你卡主(机器故障), 馒头就丢失了
一直生产,做馒头速度快,你吃来不及,馒头也就丢失了
拿个碗/篮子,馒头做好以后先放到篮子里,你要吃的时候去篮子里面取出来吃
篮子/框: Kafka
当篮子满了,馒头就装不下了,咋办?
多准备几个篮子 === Kafka的扩容
流处理平台有三个关键功能:
- 发布和订阅数据流,类似于消息队列或企业消息传递系统。
- 以容错的持久方式存储记录流。
- 处理实时产生的数据流。
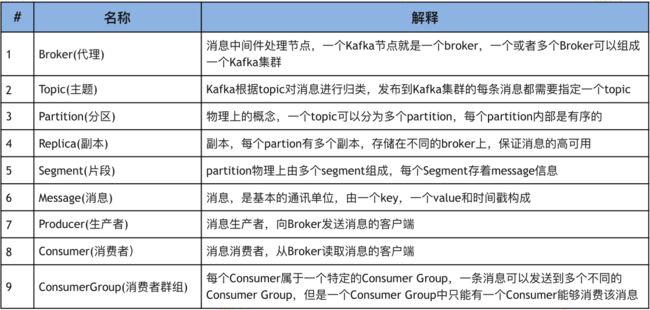
名词解释
应用场景
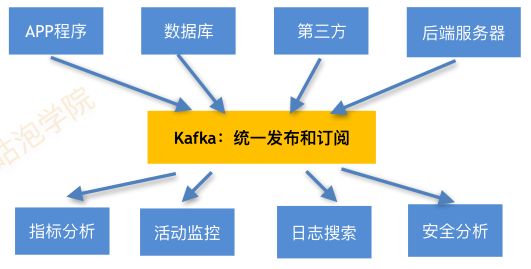
- 活动追踪:跟踪⽹网站⽤用户与前端应⽤用程序发⽣生的交互
如:⽹网站PV/UV分析 - 传递消息:系统间异步的信息交互
如:营销活动(注册后发送券码福利利) - ⽇日志收集:收集系统及应⽤用程序的度量量指标及⽇日志
如:应⽤用监控和告警 - 提交⽇日志:将数据库的更更新发布到kafka上
如:交易易统计
kafka的特点
Kafka是⼀一种分布式的,基于发布/订阅的消息系统
- 集群模式:动态增减节点,伸缩性
- 多个⽣生产者
- 多个消费者
- 消息持久化:基于磁盘的数据存储
通过横向扩展⽣生产者、消费者和broker,kafka可以轻松处理理巨⼤大的消息流,具有很好的性能和吞吐量量。
Kafka架构及核心概念
producer:生产者,就是生产馒头(老妈)
consumer:消费者,就是吃馒头的(你)
broker:篮子
topic:主题,给馒头带一个标签,topica的馒头是给你吃的,topicb的馒头是给你弟弟吃
首先是几个概念:
- Kafka作为一个集群运行在一个或多个服务器上,这些服务器可以跨多个数据中心。
- Kafka集群将记录流存储在称为topic的类别中。
- 每个记录由一个key、一个value和一个 timestamp组成。
Kafka单节点单Broker部署之Zookeeper安装
kafka部署方式:
- 单节点单Broker部署及使用
- 单节点多Broker部署及使用
- 多节点多Broker部署及使用
单节点单Broker部署
1、zk直接解压;配置环境变量(vi ~/.bash_profile)
![]()
修改ZK_HOME下的conf下的zoo.cfg
数据存储路径
2、下载解压kafka;配置环境变量
![]()
修改配置文件-$KAFKA_HOME/config/server.properties
broker.id=0
listeners //监听的端口
host.name //启动在本台机器ip
log.dirs //日志存储路径
zookeeper.connect //外部zk
启动Kafka
kafka-server-start.sh
USAGE: /home/hadoop/app/kafka_2.11-0.9.0.0/bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
kafka-server-start.sh $KAFKA_HOME/config/server.properties

创建topic: zk
kafka-topics.sh --create --zookeeper hadoop000:2181 --replication-factor 1 --partitions 1 --topic hello_topic
查看所有topic
kafka-topics.sh --list --zookeeper hadoop000:2181

注意要分别在不同的控制台执行
发送消息: broker
kafka-console-producer.sh --broker-list hadoop000:9092 --topic hello_topic
消费消息: zk
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic --from-beginning
--from-beginning的使用是从头消费
查看所有topic的详细信息:kafka-topics.sh --describe --zookeeper hadoop000:2181
查看指定topic的详细信息:kafka-topics.sh --describe --zookeeper hadoop000:2181 --topic hello_topic

单节点多Broker部署及使用

分别修改三个配置文件
server-1.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-1
listeners=PLAINTEXT://:9093
broker.id=1
server-2.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-2
listeners=PLAINTEXT://:9094
broker.id=2
server-3.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-3
listeners=PLAINTEXT://:9095
broker.id=3
启动kafak
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-1.properties &
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-2.properties &
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-3.properties &
测试:
//创建一个topic
kafka-topics.sh --create --zookeeper hadoop000:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
//生产端发送消息
kafka-console-producer.sh --broker-list hadoop000:9093,hadoop000:9094,hadoop000:9095 --topic my-replicated-topic
//消费者消费消息
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic my-replicated-topic
//查看topic的消息
kafka-topics.sh --describe --zookeeper hadoop000:2181 --topic my-replicated-topic
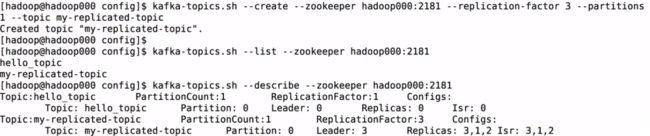
Kafka容错性测试
![]()
kill掉server2

经过测试消费者和生产者都可以正常进行
查询topic的详细信息发现活得节点就只剩3和1
![]()
继续kill掉server3
![]()
测试消费者和生产者都可以正常进行;虽然有warning日志;但是没有影响干活
在scala-maven的IDEA下Kafka Java API编程测试
加入kafka依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.11artifactId>
<version>0.9.0.0version>
dependency>
/**
* Kafka常用配置文件
*/
public class KafkaProperties {
public static final String ZK = "192.168.199.111:2181";
public static final String TOPIC = "hello_topic";
public static final String BROKER_LIST = "192.168.199.111:9092";
public static final String GROUP_ID = "test_group1";
}
Kafka Producer
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
/**
* Kafka生产者
*/
public class KafkaProducer extends Thread{
private String topic;
private Producer<Integer, String> producer;
public KafkaProducer(String topic) {
this.topic = topic;
Properties properties = new Properties();
properties.put("metadata.broker.list",KafkaProperties.BROKER_LIST);
properties.put("serializer.class","kafka.serializer.StringEncoder");
properties.put("request.required.acks","1");
producer = new Producer<Integer, String>(new ProducerConfig(properties));
}
@Override
public void run() {
int messageNo = 1;
while(true) {
String message = "message_" + messageNo;
producer.send(new KeyedMessage<Integer, String>(topic, message));
System.out.println("Sent: " + message);
messageNo ++ ;
try{
Thread.sleep(2000);
} catch (Exception e){
e.printStackTrace();
}
}
}
}
Kafka Consumer
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* Kafka消费者
*/
public class KafkaConsumer extends Thread{
private String topic;
public KafkaConsumer(String topic) {
this.topic = topic;
}
private ConsumerConnector createConnector(){
Properties properties = new Properties();
properties.put("zookeeper.connect", KafkaProperties.ZK);
properties.put("group.id",KafkaProperties.GROUP_ID);
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
@Override
public void run() {
ConsumerConnector consumer = createConnector();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
// topicCountMap.put(topic2, 1);
// topicCountMap.put(topic3, 1);
// String: topic
// List> 对应的数据流
Map<String, List<KafkaStream<byte[], byte[]>>> messageStream = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStream.get(topic).get(0); //获取我们每次接收到的数据
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while (iterator.hasNext()) {
String message = new String(iterator.next().message());
System.out.println("rec: " + message);
}
}
}
/**
* Kafka Java API测试
*/
public class KafkaClientApp {
public static void main(String[] args) {
new KafkaProducer(KafkaProperties.TOPIC).start();
new KafkaConsumer(KafkaProperties.TOPIC).start();
}
}
IDEA控制台

虚拟机Consumer控制台
![]()

Kafka实战之整合Flume和Kafka完成实时数据采集
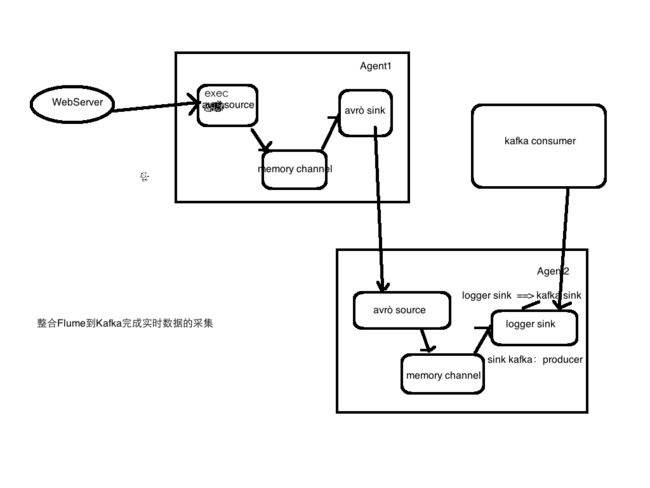
更改Flume实战案例三中的下半部分avro-memory-logger.conf为avro-memory-kafka.conf
avro-memory-kafka.conf
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
启动测试:
flume-ng agent \
--name avro-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic