网络爬虫:基于有道的文本翻译
参考书籍:《零基础入门学习Python》小甲鱼 编著
1.下载网络上图片
现要在百度上下载一张图片,直接给出Python代码:
import urllib.request
#图片的网络地址
url = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1504341479&\
di=dd995208aedd77555292d2752ffcd5d8&imgtype=jpg&er=1&src=http%3A%2F%2Fimg.taopic.com%2Fuploads%2Fallimg%2F140606%2F318757-1406060S35991.jpg"
response = urllib.request.urlopen(url)
img = response.read()
with open('img.jpg','wb') as f:
f.write(img)代码运行后,代码所在的文件夹中出现了img.jpg这张图片:

图 1
代码分析:
1)、python访问互联网可通过urllib模块实现,具体的,可通过urllib.request.urlopen()函数访问网页;
urlopen函数原型为:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
2)、urllib.request.urlopen()函数的url参数即可以是一个字符串(如上面的代码),也可以是Request对象,如果传入一个字符串,那么python会默认先将目标字符串转换成Requset对象,然后再传给urlopen函数。
因此,这一行代码:
response = urllib.request.urlopen(url)可以改为:
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
urlopen的函数原型为:urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None),是一个抽象的URL请求。
3)、response实际返回时一个类文件对象,因此可以用read()方法来读取内容。
2.基于有道的文本翻译
2.1 翻译文本
2.2.1 前期准备
首先进入有道翻译官网(http://www.youdao.com),在浏览器右击,选择“审查元素”(或“审查”,各浏览器不一样)命令,切换到NetWork窗口,如下图所示:
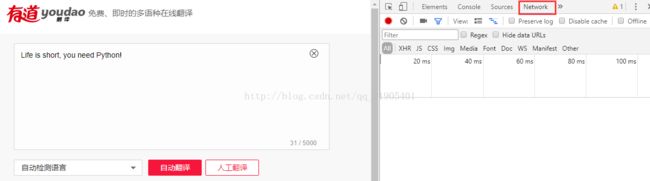
图 2
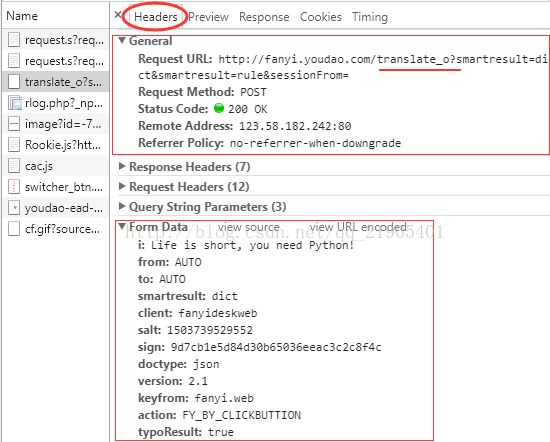
图 3

图 4
2.1.2 代码编写
import urllib.request #导入模块
import urllib.parse
import json
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom="
def main():
while True:
content = input("请输出需要翻译的内容(退出输入q):")
if content == 'q':
break
data = {};
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '1503581407033'
data['sign'] = '67472a1b3638989677f7aca9af3be0aa'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
tar = json.loads(html)
print("翻译结果是:%s"%tar['translateResult'][0][0]['tgt'])
if __name__=="__main__":
main() 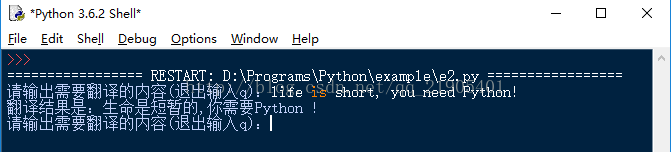
图 5
2.1.3 代码分析
1)在客户端和服务器之间进行请求-响应时,最常被用到的方法是GET和POST。通常,GET是从指定的服务器请求数据,而POST是向指定的服务器提交要被处理的数据。上述点击“自动翻译”按钮后,使用了POST方法提交数据;
2)urlopen( )函数有一个data参数。如果给这个参数赋值,那么HTTP的请求是使用POST方式;如果data的值是NULL(也即默认值),那么HTTP的请求的是GET方式。这里需要指出的是,这个data参数的值必须符合application/x-www-form-urlencoded的格式,而我们可以使用urllib.parse.urlencode()函数将字符串转换为这个格式;
data = urllib.parse.urlencode(data).encode('utf-8')3)data为一个字典,其中的数据来自于图3中的From Data中数据;
4)Python爬取的对象是以utf-8编码的bytes对象,要还原为带中文的html代码,需要对其进行解码,将它变成Unicode编码。代码27行得到的html是字符串形式:
>>> print(html) {"type":"EN2ZH_CN","errorCode":0,"elapsedTime":8,"translateResult":[[{"src":"life is short, you need Python!","tgt":"生命是短暂的,你需要Python !"}]]}
#判断html类型
>>> type(html)
字符串在python内部的表示是Unicode编码,因此,在进行编码转换时,通常需要以Unicode作为中间编码,即先将返回的bytes对象的数据解码(decode)成Unicode。
得到的字符串是一个JSON格式的字符串(JOSN是一种轻量级的数据交换格式),因此需要对这个JOSN格式的字符串进行解析:
>>> import json
>>> tar = json.loads(html)
>>> print(tar){'type': 'EN2ZH_CN', 'errorCode': 0, 'elapsedTime': 8, 'translateResult': [[{'src': 'life is short, you need Python!', 'tgt': '生命是短暂的,你需要Python !'}]]}
查看tar的类型:
>>> type(tar)可以看出,html经过处理后已变成了一个字典格式,因此现在只需要按照字典格式操作方式取出所需数据即可:
>>> tar['translateResult'][0][0]['tgt']
5)URL格式一定要正确,我在浏览器得到的URL为:
http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule&sessionFrom=
但将该URL复制到浏览器,显示{"errorCode":50}错误。

经过尝试发现,将"translate_o"中“_o”去掉即可,即修改后的URL为:
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom="
2.2 隐藏
图 3中,Request headers是客户端发送请求的Header,这个常常被服务器端用来判断是否来自于“非人类”的访问。“非人类”的访问会给服务器其造成一定的压力,因此服务器会对“非人类”访问进行一定的限制。
一般是通过User-Agent来识别,普通浏览器会通过该内容向访问网站提供你所使用的浏览器类型、操作系统、浏览器内核等信息标识:
2.2.1 修改 User-Agent
import urllib.request
import urllib.parse
import json
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom="
def main():
while True:
content = input("请输出需要翻译的内容(退出输入q):")
if content == 'q':
break
data = {};
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '1503581407033'
data['sign'] = '67472a1b3638989677f7aca9af3be0aa'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
##第一种方法
#headers = {};
#headers['Referer'] = 'http://fanyi.youdao.com'
#headers["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36 "
#req = urllib.request.Request(url,data,headers)#创建Request对象时将headers参数传入
##第二种方法,Requset对象生成之后通过add_header()方法添加
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
tar = json.loads(html)
print("翻译结果是:%s"%tar['translateResult'][0][0]['tgt'])
if __name__=="__main__":
main()通过修改User-Agent实现隐藏是最简单的方法。但用于抓取网页的爬虫如果是只使用这种方式,那么一个IP地址在短时间内连续进行网页访问,会不符合普通人类的行为标准,同时也会对服务器造成压力。因此,服务器只需记录每个IP地址的访问频率,在单位时间内,如果访问频率超过一个阈值,便认为该IP地址很有可能是爬虫,于是可以跳出一个验证码页面,要求用户填写验证码,通过这种方式可简单的规避掉爬虫访问。
怎么避免因单位时间内访问频率过高被服务器规避掉呢?同样有两种方法:1)使用定时器;2)使用IP地址代理,即使用不同的IP地址进行访问。
2.2.2 延时提交数据
延时提交的时间,这个比较简单,使用time模块即可。如下面代码,5s提交一次数据。但是通过延时的方式,会降低程序的工作效率。
import urllib.request
import urllib.parse
import json
import time #导入time模块
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom="
def main():
while True:
content = input("请输出需要翻译的内容(退出输入q):")
if content == 'q':
break
data = {};
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '1503581407033'
data['sign'] = '67472a1b3638989677f7aca9af3be0aa'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
##第二种方法,Requset对象生成之后通过add_header()方法添加
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
tar = json.loads(html)
print("翻译结果是:%s"%tar['translateResult'][0][0]['tgt'])
time.sleep(5) #延时5s
if __name__=="__main__":
main()2.2.3 使用代理
可以查找免费代理IP:
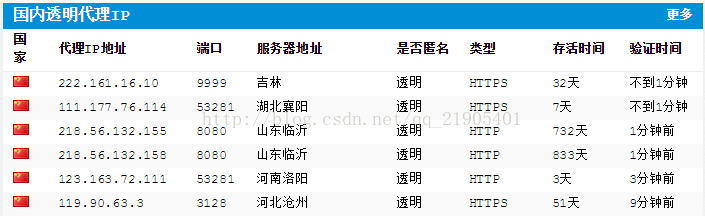
图 7
使用的代理步骤如下:
1) proxy_support = urllib.request.ProxyHandler({ })
参数是一个字典,字典的键是处理的类型,例如http、ftp或https,字典的值就是代理的IP地址和对应的端口号。
2) opener = urllib.request.build_opener(proxy_support)
当使用urlopen()函数打开一个网页时,是使用默认的opener在工作。但这个opener是可以定制的,例如给它定制特殊的headers,或者给它定制指定的代理IP。
3)urllib.request.install_opener(opener)
将定制好的opener安装到系统中,是一劳永逸的方法。因为在此之后,只需要调用普通的urlopen()函数,就是以定制好的opener进行工作。
这里需要指出的是,安装后会替换掉默认的opener。如果你不想替换默认的opener,你可以在每次特殊需要的时候,用opener.open()的 方法打开网页:
req = urllib.request.Request(url,data)
response = opener.open(req)
import urllib.request
import urllib.parse
import json
import time #导入time模块
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom="
def main():
while True:
content = input("请输出需要翻译的内容(退出输入q):")
if content == 'q':
break
data = {};
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '1503581407033'
data['sign'] = '67472a1b3638989677f7aca9af3be0aa'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
proxy_support = urllib.request.ProxyHandler({"https": "222.161.16.10:9999"})
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')]
urllib.request.install_opener(opener)
req = urllib.request.Request(url,data)
#req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
tar = json.loads(html)
print("翻译结果是:%s"%tar['translateResult'][0][0]['tgt'])
if __name__=="__main__":
main()