【深度之眼吴恩达机器学习】打卡学习
【深度之眼吴恩达机器学习】打卡学习
- 第一周
- introduction
- What is Machine Learning?
- Supervised Learning
- Unsupervised Learning
- model and cost function
- Model Representation
- cost function
- parameter learning
- Gradient Descent
- 第二周
- multivariate linear regression
- Gradient Descent for Multiple Variables
- Gradient Descent in Practice I - Feature Scaling
- Features and Polynomial Regression
- computing parameters analytically
课程来自深度之眼,有兴趣的小伙伴下面是连接

第一周
introduction
What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as: “the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.
Supervised Learning
监督学习就是给你正确的标签叫你去拟合或者分类,打个比方,我们在做物理实验的时候会在直角坐标系上标注数据,最后把所有数据用一条线连起来,这就是监督学习。下面给出官方解释
1.在监督学习中,我们有一个数据集并且已经知道正确的输出应该是什么样子,因为我们知道输入和输出之间是有关系的。
2.监督学习问题分为“回归”问题和“分类”问题。在回归问题中,我们试图预测连续输出的结果,这意味着我们试图将输入变量映射到某个连续函数。在分类问题中,我们试着预测离散输出的结果。换句话说,我们试图把输入变量映射成离散的类别。
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
无监督学习更像是没人传授你经验,打个比方,一个从来没见过红豆绿豆的人,也没人把经验告诉他,他要如何分类呢,他就会考虑根据特征去给他分分类,拥有相似特征的会归为一类
model and cost function
Model Representation
先给出官方描述

大概意思就是我们给出一系列输入值和输出值(x,y)的集合,然后我们要去拟合一个函数X->Y的映射,能非常好的反应我们给出集合的关系,最简单的就行y=ax+b这种函数了,通过成对的(x,y)去拟合得出最佳的a和b。
cost function

以上就是均方误差的定义啦,吧预测值和真实值做一个差值取平方然后累加求平均,至于引入1/2,完全是为了计算方便啦。

课真的讲的太细了,不懂得看下这个截图哦,可以让你有一个直观感受
parameter learning
Gradient Descent

第二周
multivariate linear regression
Gradient Descent for Multiple Variables
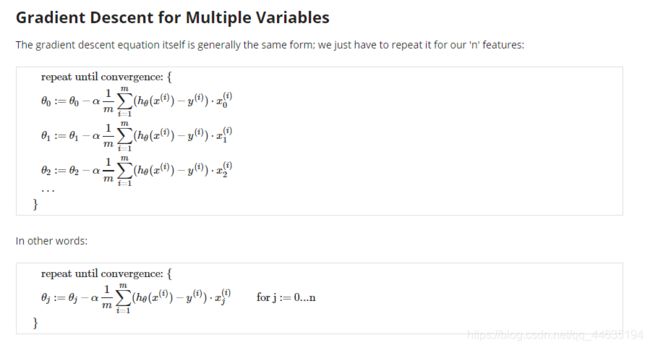
推导很简单,如下是损失函数的式子,当时为什么1/2m,求导就显现出来了
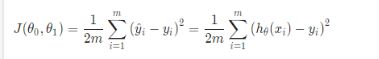
Gradient Descent in Practice I - Feature Scaling

这里说的就是归一化操作,把特征缩放,变量与数据集均值的差值除以数据集的最大值减最小值或者数据集的标准差
Features and Polynomial Regression

computing parameters analytically

