爬虫爬取中国大学排名top100并简单可视化分析
爬虫爬取中国大学排名top100并简单可视化分析。
目标链接
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html
实践环境
pycharm2018+python3.7
实践思路
首先进入目标链接,查看目标数据是否为动态变化。
确认非动态变化后,对页面进行解析,提取需要的相关数据信息。
将数据存入csv文件中并保存。
后对保存的数据进行简单的数据分析并可视化。
实践过程
一、 数据抓取
判断目标数据非动态变化后,可进行数据抓取。
代码如下:
(1)获取网站页面’’’
def getHTMLText(url):
try:
resp = request.urlopen(url)
html_data = resp.read().decode('utf-8')
return html_data
except:
return ""
'''(2)处理页面,提取相关信息'''
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: # 搜索'tbody'后面的子节点
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string,tds[2].string, tds[3].string])
二、数据存储
本次数据存储利用CSV库对数据进行写入并保存。
代码:
def write_to_file(items):
# with open('daxuedata.csv', 'a', encoding='utf_8_sig') as f:
# f.write(json.dumps(items, ensure_ascii=False) + '\n')
# pass
with open('daxuedata3.csv', 'a', encoding='utf_8_sig',newline='') as f:
fieldnames = ['index','schoolname','area','score',]
w = csv.DictWriter(f,fieldnames = fieldnames)
w.writerow(items)
pass
pass
三、数据简单分析且可视化
1、对大学评分前十的学校进行排名并画出图形。
代码:
def dataanly1():
df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; desc
name1 = df_score.schoolname[:10] # x轴坐标
score1 = df_score.score[:10] # y轴坐标
plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致
plt.ylim(10,100)
plt.title("大学评分最高Top10",color=colors1)
plt.xlabel("大学名称")
plt.ylabel("评分")
# 标记数值
for x,y in enumerate(list(score1)):
plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)
pass
pl.xticks(rotation=270) # 旋转270°
plt.tight_layout() # 去除空白
plt.show()
pass
2、对各地区的大学数量统计并画出简单图形。
代码:
def DXAnly2():
area_count = df.groupby(by='area').area.count().sort_values(ascending=False)
# 绘图方法1
area_count.plot.bar(color='#4652B1') # 设置为蓝紫色
pl.xticks(rotation=0) # x轴名称太长重叠,旋转为纵向
for x, y in enumerate(list(area_count.values)):
plt.text(x, y + 0.5, '%s' % round(y, 1), ha='center', color=colors1)
plt.title('各地区大学数量排名')
plt.xlabel('地区')
plt.ylabel('数量(所)')
plt.show()
pass
实践结果:
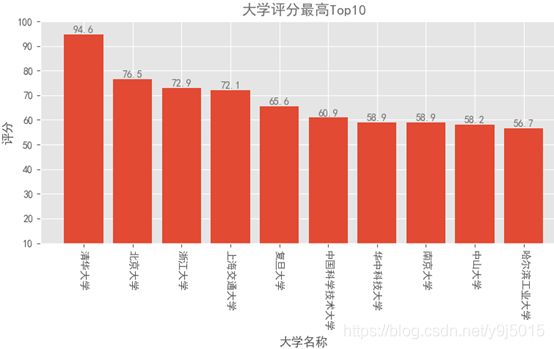
图 1大学评分最高前十名
由图可以简单看出大学评分在90分以上的只有一所清华大学,前十名的大学中只有6所大学的评分超过60。
前三名的大学分别是清华大学、北京大学、浙江大学。

图 2各个地区的大学数量排名
由图可以简单看出评分前100名的大学中,北京就占了23所。说明北京作为我国的首都,其中的高素质教育水平远远超过其他地方。
其中前三名的地区是北京、江苏、上海,这也是我国经济水平较为发达的地区,可以简单的看见高素质教育水平可以影响地区经济的发展。