beautifulsoup如何只爬取直接标签的内容而不爬取子标签的内容
对于这个问题,在网上大概找到两种靠谱点的回答,但实际上也是有问题的。
第一种方法
调用find(text=True).strip()
第二种方法
调用stripped_strings
测试代码
from bs4 import BeautifulSoup
html1 = """
hello
world
hi
good
"""
html2 = """
world
hello
good
hi
"""
a = BeautifulSoup(html1, "lxml").find('li').find(text=True).strip()
print("a=%s"%a)
b = BeautifulSoup(html1, "lxml").find('li').stripped_strings
print("b=%s"%list(b)[1])
a = BeautifulSoup(html2, "lxml").find('li').find(text=True).strip()
print("a=%s"%a)
b = BeautifulSoup(html2, "lxml").find('li').stripped_strings
print("b=%s"%list(b)[1])输出结果
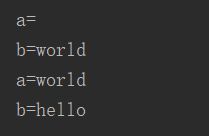
可以看到,这两种方法都不满足要求!
有知道的大神么,请告知小弟一下,感激不尽!!!