【网络爬虫】实现有道翻译提取
利用python 实现有道翻译提取
原料
有道翻译网页:http://fanyi.youdao.com/
具备检查元素的浏览器:基本所有浏览器都有,推荐使用谷歌Chrome
Python版本2.7以上
按照以下操作
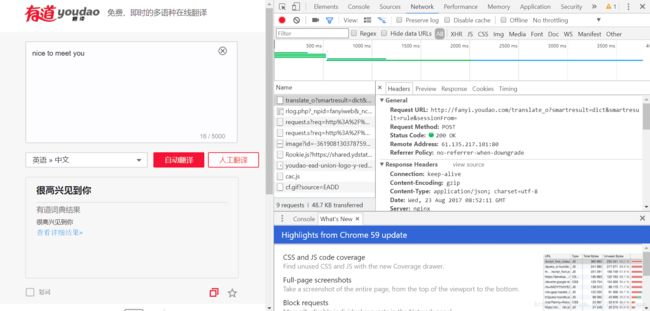
在左侧翻译栏中,加入输入你需要翻译的内容,点击Network按自动翻译按钮,在Name栏中选中一个以translate开头的(post方式提交)
关注 Request URL
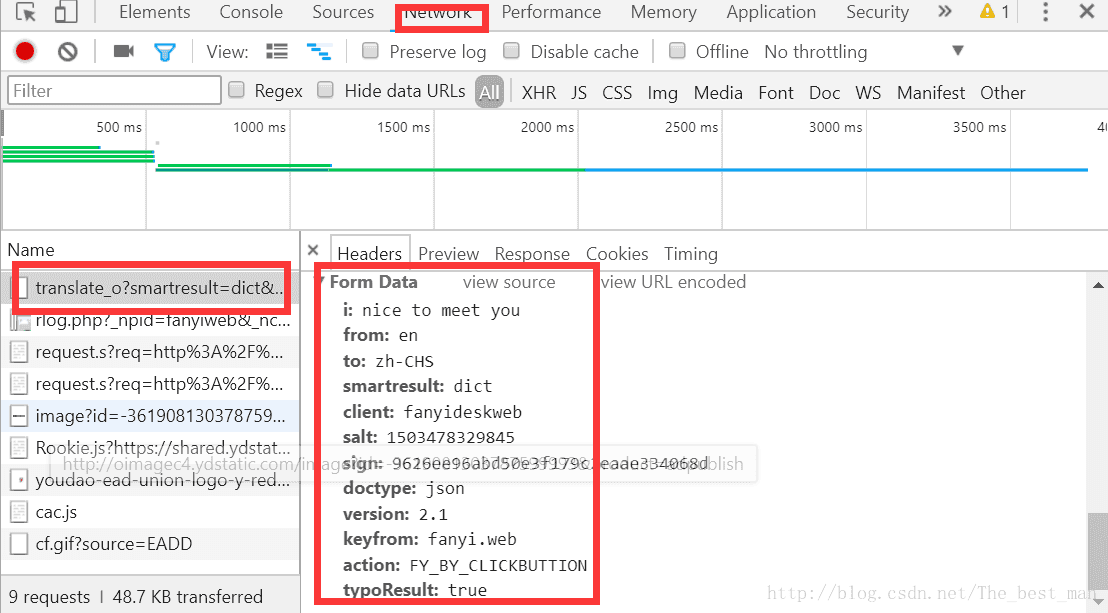
关注from data (提交的表单数据)
代码
#-*- coding:utf-8-*-
import urllib
import json
import sys
#解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128)
defaultencoding = 'utf-8'
if sys.getdefaultencoding() != defaultencoding:
reload(sys)
sys.setdefaultencoding(defaultencoding)
content = raw_input("请输入需要翻译的内容:")
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
data={}
data['i'] = content
data['from'] = 'zh-CHS'
data['to'] = 'en'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '1503458227455'
data['sign'] = 'a68a9d5b5868f2501eb445ded808cec4'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'true'
data = urllib.urlencode(data).encode('utf-8')
#print "打印数据:", data
response = urllib.urlopen(url, data)
html = response.read().decode('utf-8')
#print html
target = json.loads(html)
#print target
print ("翻译结果:%s" % (target['translateResult'][0][0]['tgt']))