pytorch 实现inception 最简单上手的写法
inception模型的讲解
本文主要是针对模型而言,后续会陆续发布model,比如inception,resnet,densenet各种经常使用的,最好自己手动实现,这些基础模型的掌握是为了你能够随意的组合,没有一个现成的模型能够训练到比赛拿第一的水平,所以需要你去掌握,精通每一个模型,然后按照自己的思路根据训练数据集来写网络,去创新更加适应此数据集的模型,好,先看下大致的代码。
import torch
import torch.nn as nn
import torch.nn.functional as F
#全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
class Inception(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(Inception,self).__init__()
self.p1 = nn.Sequential(
nn.Conv2d(in_c,c1,kernel_size=1),
nn.ReLU()
)
self.p2 = nn.Sequential(
nn.Conv2d(in_c,c2[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0], c2[1], kernel_size=3,padding=1),
nn.ReLU()
)
self.p3 = nn.Sequential(
nn.Conv2d(in_c, c3[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0], c3[1], kernel_size=5,padding=2),
nn.ReLU()
)
self.p4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_c,c4,kernel_size=1),
nn.ReLU()
)
def forward(self, x):
p1 = self.p1(x)
p2 = self.p2(x)
p3 = self.p3(x)
p4 = self.p4(x)
return torch.cat((p1,p2,p3,p4),dim=1)
class GoogModel(nn.Module):
def __init__(self):
super(GoogModel,self).__init__()
self.b1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b3 = nn.Sequential(
Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(16,32),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b4 = nn.Sequential(
Inception(480,192,(96,208),(16,48),64),
Inception(512,160,(112,224),(24,64),64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112,(144,288),(32,64),64),
Inception(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.b5 = nn.Sequential(
Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
GlobalAvgPool2d()
)
self.feature = nn.Sequential(
self.b1,self.b2,self.b3,self.b4,self.b5
)
self.fc = nn.Sequential(
nn.Linear(3*3*1024,10) #这里使用的图像大小224*224的
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
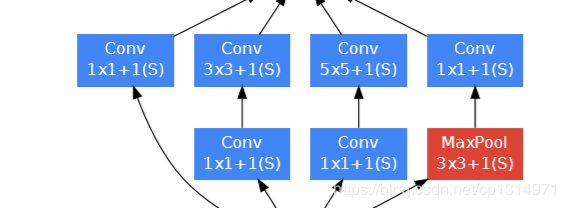
好了现在是理解代码的时候了,首先要知道Inception这个类,看下面的照片更加明白,一共有四种卷积通道,它的输入层的特征图都是同一个,唯一不同的就是中间经历不同的卷积层。该结构采用了四个分支,每个分支分别由1x1卷积、3x3卷积、5x5卷积和3x3maxpooling组成,既增加了网络的宽度,也增加了网络对不同尺度的适用性。四个分支输出后在通道维度上进行叠加,作为下一层的输入。四个分支输出的featuremap的尺寸可由padding的大小进行控制,以保证它们的特征维度相同(不考虑通道数)
class Inception(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(Inception,self).__init__()
#线路1 1*1的卷积层
self.p1 = nn.Sequential(
nn.Conv2d(in_c,c1,kernel_size=1),
nn.ReLU()
)
#线路2 1*1卷积层后接3*3的卷积
self.p2 = nn.Sequential(
nn.Conv2d(in_c,c2[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0], c2[1], kernel_size=3,padding=1),
nn.ReLU()
)
#线路3 1*1卷积层后接5*5的卷积层
self.p3 = nn.Sequential(
nn.Conv2d(in_c, c3[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0], c3[1], kernel_size=5,padding=2),
nn.ReLU()
)
#线路4 3*3最大池化后接1*1卷积层
self.p4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_c,c4,kernel_size=1),
nn.ReLU()
)
def forward(self, x):
p1 = self.p1(x)
p2 = self.p2(x)
p3 = self.p3(x)
p4 = self.p4(x)
return torch.cat((p1,p2,p3,p4),dim=1)
#这里是通道(#`O′(#`O′维上的合并
对应图片的样式,有四种卷积方式,c1_c4是每条线路里的输出通道数,重点是要知道一个图片经过这个模块图片大小的变化,这个设计很巧妙,每进过一次inception模块大小变为原来的二分之一,理解这一点也很重要,尺寸大小的计算公式是(n+2p+1-k)/s,n是图片原本大小尺寸,p是padding,k是kernel_size。这个是卷积的计算,举个例子,比如输入的图像大小为96*96的,输入的格式是[1,3,96,96]下面我把经过各个阶段变化的尺寸大小变化写出来,b1=[1,64,24,24], b2=[1,192,12,12], b3=[1,480,6,6], b4=[1,832,3,3], b5=[1,1024,1,1], b6=[1,1024], b7=[1,10].
要自己会算出进过卷积之后的特征图大小,
nn.Linear(3*3*1024,10)
这段代码是在输入图片224* 224的输入下进过卷积层得到的特征图变为3* 3,大家可以自己计算下,不同大小的照片经过相同的卷积得到的特征图大小不一样。这点很重要。
下面这个代码可以用来计算特征图经过卷积之后的大小
import torch.nn as nn
import torch
class Unit(nn.Module):
def __init__(self, in_channels, out_channels):
super(Unit, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=7,stride=2, padding=3)
self.bn = nn.BatchNorm2d(num_features=out_channels)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(3,2,1)
def forward(self, input):
output = self.conv(input)
output = self.bn(output)
output = self.relu(output)
output = self.pool(output)
return output
class A(nn.Module):
def __init__(self, num_classes=2):
super(A, self).__init__()
self.unit1 = Unit(3, 64)
self.net = nn.Sequential(self.unit1)
def forward(self, input):
output = self.net(input)
return output
net = A()
x = torch.rand(1,3,224,224)
for name,unit in net.named_children():
x =unit(x)
print(name,'output shape:',x.shape)
通过改变x的不同尺寸和设置不同的kernel_size,stride,padding可以计算卷积之后的特征图大小,这个是辅助理解特征图大小计算过程的。使用这个会报错但是没关系,我们已经算出来了,报错的地方不用管