2020最新51job招聘网爬取保姆式教程,带你打造自己的职业信息库!
Python爬虫实战:最新51job爬取教程
- 爬取前准备
- 网页查看
- 建立mysql数据库及表
- 完整代码及代码分析
- 图片辅助分析
- 运行结果
爬取前准备
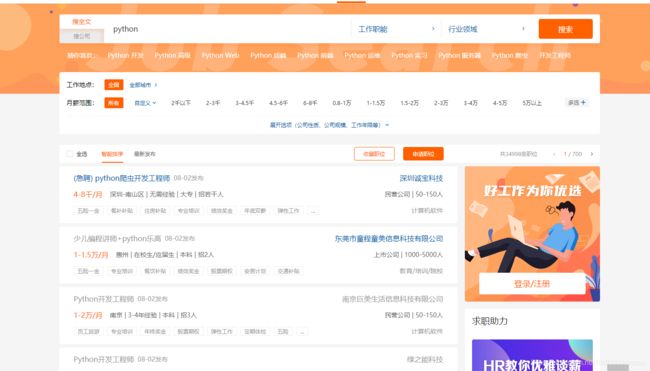
网页查看
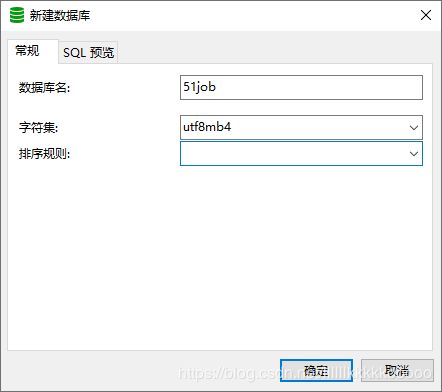
建立mysql数据库及表
建立数据库
建立表
CREATE TABLE `51job` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) DEFAULT NULL,
`company` varchar(100) DEFAULT NULL,
`price` varchar(100) DEFAULT NULL,
`education` varchar(100) DEFAULT NULL,
`experience` varchar(100) DEFAULT NULL,
`welfare` varchar(100) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`text` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=124 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
完整代码及代码分析
from selenium import webdriver
import time
import pymysql
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
from urllib import parse
num = 2
sql = "insert into 51job(id,title,company,price,education,experience, welfare,address,text) values(null,%s,%s,%s,%s,%s,%s,%s,%s)"
name = ""
#初始化浏览器
def init():
global name
# 实现无可视化界面得操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置chrome_options=chrome_options即可实现无界面
driver = webdriver.Chrome(chrome_options=chrome_options)
time.sleep(0.5)
# 把浏览器实现全屏
# driver.maximize_window()
time.sleep(0.5)
#发送请求
driver.get("https://search.51job.com/list/000000,000000,0000,00,9,99,"+str(name)+",2,1.html")
source = driver.page_source
# 返回driver和页面源码
return driver,source
#解析
def download(driver,page_text,conn,cur):
#引入全局变量
global num
global name
global sql
# 使用lxml XML解析器
bs = BeautifulSoup(page_text, "lxml")
#参考图1
div_list = bs.find(class_="j_joblist").find_all(class_="e")
for li in div_list:
bs = BeautifulSoup(str(li), "lxml")
#参考图2
#职位名称
title = bs.find(class_="jname at").text
#工资
price = bs.find(class_="sal").text
#抛异常的是因为有的公司是没有该值的
try:
#公司福利
welfare = bs.find(class_="tags")["title"]
except:
welfare = "无福利"
#公司名称
company = bs.find(class_="cname at")['title']
#详情页URL
url = bs.find(class_="el")['href']
#经验
experience = bs.find(class_="d at").text.split("|")[1]
try:
#学历
education = bs.find(class_="d at").text.split("|")[2]
except:
education = "无介绍"
#51job有的详情页URL对应的网页跟大多数详情页是不一样的没有对应的数据,可参考图3
#请求详情页
if "https://jobs.51job.com/" in url:
time.sleep(0.5)
#请求详情页URL
driver.get(url)
page_source = driver.page_source
bs_page = BeautifulSoup(page_source, "lxml")
#参考图4
text = bs_page.find(class_="bmsg job_msg inbox").text.replace("微信分享","").strip()
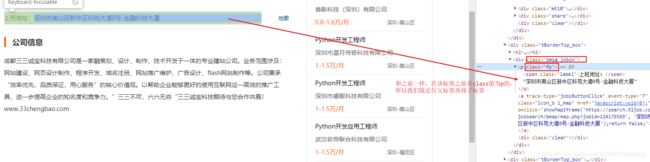
try:
#参考图5
address = bs_page.find(class_="bmsg inbox").find(class_="fp").text.replace("上班地址:","")
except:
address = "无说明"
#print(title)
#执行插入语句
cur.execute(sql, (title, company, price, education, experience, welfare,address,text))
#提交事务
conn.commit()
#进行多页爬取
#num控制页数
if num <= 3:
next_url = "https://search.51job.com/list/000000,000000,0000,00,9,99,"+str(name)+",2,"+str(num)+".html"
time.sleep(0.5)
driver.get(next_url)
num += 1
download(driver,driver.page_source,conn,cur)
return conn,cur
def init_mysql():
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': 'wad07244058664',
'database': '51job',
'charset': 'utf8'
}
conn = pymysql.connect(**dbparams)
cur = conn.cursor()
return conn,cur
def close_mysql(conn,cur):
cur.close()
conn.close()
if __name__ == "__main__":
name = input("请输入爬取职位名称:")
#进行二次转码,具体可参考博主文章
text1 = parse.quote(name)
name = parse.quote(text1)
#浏览器初始化
driver,source = init()
#mysql初始化
conn,cur = init_mysql()
#数据爬取
conn,cur = download(driver,source,conn,cur)
#关闭MySQL链接
close_mysql(conn,cur)
图片辅助分析
图1
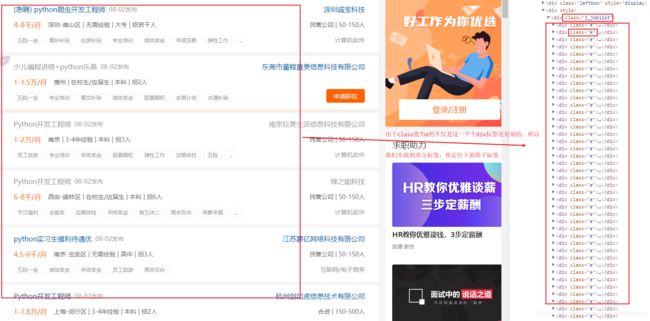
图2
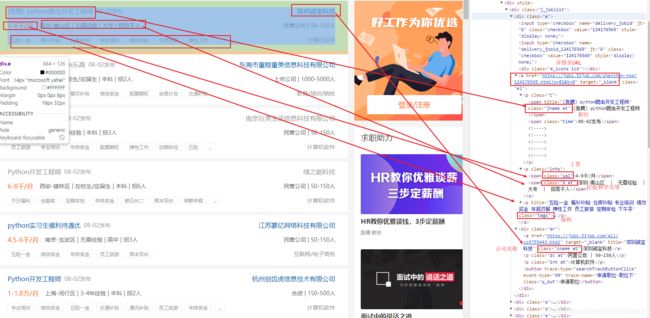
图3
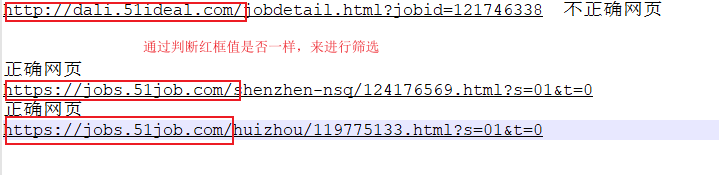
图4
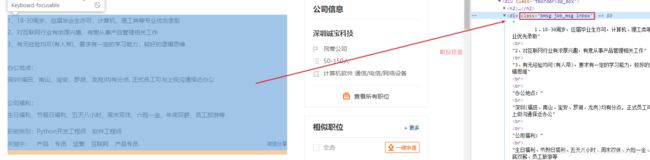
图5
运行结果

博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!
更多Python爬虫有关文章
