Python视频学习(三、网络编程, 四、多任务)
感谢传智dongge大神
目录
- 1. 背景知识
- 1.1 IP地址
- 1.2 端口号Port
- 2. Socket
- 创建Socket
- a. 创建UDP套接字
- b. 创建TCP套接字
- 2. UDP通信
- 2.1 发送
- 2.2 接收
- 地址绑定时的注意
- 2.3 简单的UDP聊天室
- 注意的漏洞
- 3. TCP通信
- 3.1 TCP客户端
- 3.2 TCP服务器
- 注意点:
- 3.3 下载程序案例
- 客户端参考代码
- 服务器端参考代码
- 4. 线程
- 4.1 使用`threading.Thread`创建线程
- 注意
- 4.2 通过继承`threading.Thread`创建线程
- 4.3 查看有几个线程
- 判断子线程全部结束
- 注意
- 4.4 线程共享全局变量
- a. 互斥锁同步
- b. 死锁问题
- 4.5 多线程版的udp聊天室
- 5. 进程
- 5.0 进程和线程的对比
- 5.1 创建使用进程
- a. Process使用
- 创建对象的参数
- 实例方法/属性
- b. 获取当前线程的pid
- 5.2 进程间的通信
- 使用Queue
- 5.3进程池
- 5.4 多进程拷贝文件夹内的文件+显示进度
- 6. 协程(Python特有)
- 6.1 可迭代对象
- 6.2 迭代器
- a. for循环调用过程
- b. 只用一个类
- c. 迭代器的应用——斐波拉契
- d. 使用可迭代对象生成list/tuple的原理
- 6.3 ★生成器
- a. 生成器表达式
- b. 生成器函数
- **生成器函数的几个特点**:
- 使用`send`来启动生成器
- 6.5 使用yield实现多任务
- 6.6 使用 greenlet完成协程
- 6.7 使用gevent协程
- a. 简单使用
- `gevent`的特点
- b. 延时自动切换
- c. ★打补丁自动包装gevent+ joinall
- 6.8 gevent协程下载案例
- 6.9 进程、线程、协程简单总结
1. 背景知识
1.1 IP地址
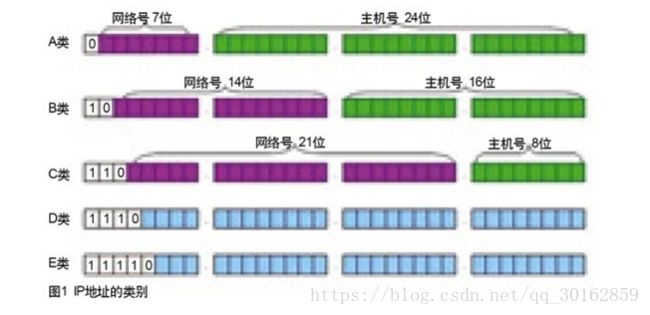
- A类IP地址
-
- 一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”,
地址范围1.0.0.1-126.255.255.254
- 一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”,
-
- 二进制表示为:00000001 00000000 00000000 00000001 - 01111110 11111111 11111111 11111110
-
- 可用的A类网络有126个,每个网络能容纳1677214个主机
- B类IP地址
-
- 一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,
-
- 地址范围128.1.0.1-191.255.255.254
-
- 二进制表示为:10000000 00000001 00000000 00000001 - 10111111 11111111 11111111 11111110
-
- 可用的B类网络有16384个,每个网络能容纳65534主机
- C类IP地址
-
- 一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”
-
- 范围192.0.1.1-223.255.255.254
-
- 二进制表示为: 11000000 00000000 00000001 00000001 - 11011111 11111111 11111110 11111110
-
- C类网络可达2097152个,每个网络能容纳254个主机
- D类地址用于多点广播
-
- D类IP地址第一个字节以“1110”开始,它是一个专门保留的地址。
-
- 它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中
-
- 多点广播地址用来一次寻址一组计算机 s 地址范围224.0.0.1-239.255.255.254
- E类IP地址
-
- 以“1111”开始,为将来使用保留
-
- E类地址保留,仅作实验和开发用
- 私有ip
-
- 在这么多网络IP中,国际规定有一部分IP地址是用于我们的局域网使用,也就是属于私网IP,不在公网中使用的,它们的范围是:
1. 10.0.0.0~10.255.255.255 2. 172.16.0.0~172.31.255.255 3. 192.168.0.0~192.168.255.255
- 在这么多网络IP中,国际规定有一部分IP地址是用于我们的局域网使用,也就是属于私网IP,不在公网中使用的,它们的范围是:
IP地址127.0.0.1~127.255.255.255用于回路测试,
1.2 端口号Port
端口号范围:
一般用到的是1到65535,其中0不使用,1-1023为系统端口,也叫BSD保留端口;
1024-65535为用户端口,又分为: BSD临时端口(1024-5000)和BSD服务器(非特权)端口(5001-65535).
0-1023: BSD保留端口,也叫系统端口,这些端口只有系统特许的进程才能使用;
1024-5000: BSD临时端口,一般的应用程序使用1024到4999来进行通讯;
5001-65535: BSD服务器(非特权)端口,用来给用户自定义端口
查看端口号:
netstat -an
lsof -i [tcp/udp]:2425
一般情况下,如果一个程序需要使用知名端口的需要有root权限
Linux中dhclient命令可以主动要求被分配一个IP地址
2. Socket
在网络中,ip地址,协议,端口就可以标识网络的进程了, 使用方法都是:
- 创建socket
- 使用socket
- 关闭socket
创建Socket
import socket
socket.socket(AddressFamily, Type)
- Address Family:可以选择
AF_INET(用于 Internet 进程间通信) 或者AF_UNIX(用于同一台机器进程间通信),实际工作中常用AF_INET - Type:套接字类型,可以是
SOCK_STREAM(流式套接字,主要用于 TCP 协议)或者SOCK_DGRAM(数据报套接字,主要用于 UDP 协议)
a. 创建UDP套接字
import socket
# 创建tcp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# ...这里是使用套接字的功能(省略)...
# 不用的时候,关闭套接字
s.close()
b. 创建TCP套接字
import socket
# 创建udp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# ...这里是使用套接字的功能(省略)...
# 不用的时候,关闭套接字
s.close()
2. UDP通信
socket是全双工的
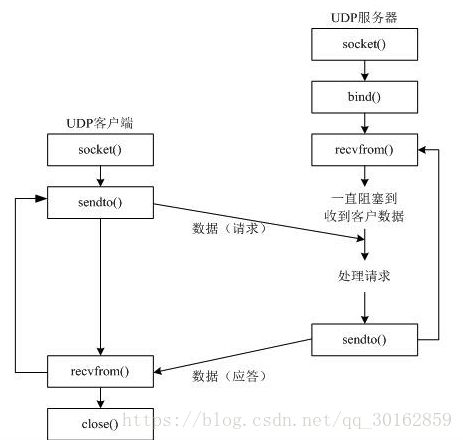
2.1 发送
- 发送方的端口号可以不绑定,不绑定的话系统就会在这次使用中随机分配一个端口号,程序结束就会释放端口号
- 地址是一个tuple,由IP+port组成
- 发送的内容是二进制
- 要记住关闭
- 绑定地址的时候如果输入
""空字符串,就代表本机IP
import socket
udp_send = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# local_addr = ("127.0.0.1", 8889)
# udp_send.bind(local_addr) --- 发送方也可以选择性的绑定端口,不绑定则随机分配一个
while True:
text = input("输入内容: ")
if text == "q":
udp_send.sendto(text.encode("utf-8"), address)
break
address = ("192.168.3.2", 8888) # 地址为一个tuple,由 IP+port组成
udp_send.sendto(text.encode("utf-8"), address) # sendto函数发送,第一个参数是二进制
udp_send.close() # 要记住关闭
2.2 接收
- recv/recvfrom 函数用来接收数据,接收的是二进制
- 接收的函数是会阻塞的
import socket
udp_recv = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
local_addr = ("192.168.3.2", 8888)
udp_recv.bind( local_addr) # 接收方一定要绑定端口
while True:
text = udp_recv.recv(1024).decode('utf-8') # 数字参数为一次接收的字节数
# 也可以使用 recvfrom函数,这样返回值是一个tuple,第二个元素为发送方地址
# binarydata, remote_addr = upd_recv.recvfrom(1024)
print(text)
if text == "q":
break
udp_recv.close()
windows上使用串口调试工具的时候,它们的默认编码方式都是gbk
地址绑定时的注意
在同一台机器上使用udp发送和接收时:
- 接收方使用实际IP,发送方使用
127.0.0.1,无法发送给接收方 - 接收方使用
127.0.0.1,发送方使用实际IP,无法发送给接收方 - 接收方使用
"",而发送方无论使用实际IP还是127.0.0.1,都可以发送成功
2.3 简单的UDP聊天室
import socket
def send_msg(udp_socket):
"""获取键盘数据,并将其发送给对方"""
# 1. 从键盘输入数据
msg = input("\n请输入要发送的数据:")
# 2. 输入对方的ip地址
dest_ip = input("\n请输入对方的ip地址:")
# 3. 输入对方的port
dest_port = int(input("\n请输入对方的port:"))
# 4. 发送数据
udp_socket.sendto(msg.encode("utf-8"), (dest_ip, dest_port))
def recv_msg(udp_socket):
"""接收数据并显示"""
# 1. 接收数据
recv_msg = udp_socket.recvfrom(1024)
# 2. 解码
recv_ip = recv_msg[1]
recv_msg = recv_msg[0].decode("utf-8")
# 3. 显示接收到的数据
print(">>>%s:%s" % (str(recv_ip), recv_msg))
def main():
# 1. 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2. 绑定本地信息
udp_socket.bind(("", 7890))
while True:
# 3. 选择功能
print("="*30)
print("1:发送消息")
print("2:接收消息")
print("="*30)
op_num = input("请输入要操作的功能序号:")
# 4. 根据选择调用相应的函数
if op_num == "1":
send_msg(udp_socket)
elif op_num == "2":
recv_msg(udp_socket)
else:
print("输入有误,请重新输入...")
if __name__ == "__main__":
main()
注意的漏洞
socket在接收数据的时候,先是由操作系统接收并且缓存起来,然后socket再去取。如果接收的时候只是调用一次recv/recvfrom,那么这个可以被别人利用起来,发送大量数据来消耗对方电脑的内存。所以最好使用While True来不断的接收,清除缓存区内容。
3. TCP通信
udp好比写信,tcp好比打电话
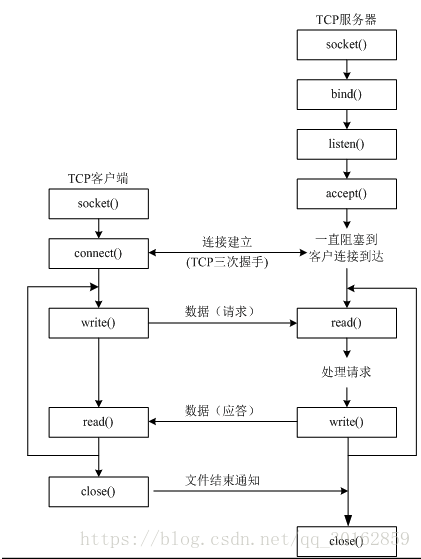
3.1 TCP客户端
步骤:
- 创建socket
- connect尝试连接服务器
- recv/send收发信息
- close
import socket
tcp_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_addr = "127.0.0.1", 8889
tcp_sk.connect(server_addr) # 尝试连接服务器,阻塞
while True:
text = input("输入内容: ")
if text == "q":
break
tcp_sk.send(text.encode("utf-8"))
# 也可以同时接收内容
# recvData = tcp_client_socket.recv(1024)
tcp_sk.close() # 记得关闭
3.2 TCP服务器
步骤:
- socket创建一个套接字
- bind绑定ip和port
- listen使套接字变为可以被动链接
- accept等待客户端的链接
- recv/send接收发送数据
- close
import socket
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
local_addr = ("", 8889)
tcp_server.bind(local_addr) # 服务器端记住绑定地址
# 使用socket创建的套接字默认的属性是主动的,使用listen将其变为被动的,这样就可以接收别人的链接了
tcp_server.listen(128) # 改变为被动监听
# 返回内容为新的 连接socket,客户端地址
# accept也可以放在 while True中,接收多个连接
connecting_sk, client_addr = tcp_server.accept()
while True:
text = connecting_sk.recv(1024)
# 当客户端断开连接(close)的时候,服务器端会 无限接收到空字符串
# 所以判断,如果接收到空的时候,则服务完成,断开
# 客户端那边,无法发送空字符串,最少要发一个字符,所以不会有假的断开连接出现
if text:
print(text.decode("utf-8"))
else:
break
# 一定记住关闭
connecting_sk.close()
tcp_server.close()
注意点:
- 关闭listen后的套接字意味着被动套接字关闭了,会导致新的客户端不能够链接服务器,但是之前已经链接成功的客户端正常通信
- 当客户端的套接字调用close后,服务器端会recv解堵塞,并且返回的长度为0,因此服务器可以通过返回数据的长度来区别客户端是否已经下线
3.3 下载程序案例
客户端参考代码
from socket import *
def main():
# 创建socket
tcp_client_socket = socket(AF_INET, SOCK_STREAM)
# 目的信息
server_ip = input("请输入服务器ip:")
server_port = int(input("请输入服务器port:"))
# 链接服务器
tcp_client_socket.connect((server_ip, server_port))
# 输入需要下载的文件名
file_name = input("请输入要下载的文件名:")
# 发送文件下载请求
tcp_client_socket.send(file_name.encode("utf-8"))
# 接收对方发送过来的数据,最大接收1024个字节(1K)
recv_data = tcp_client_socket.recv(1024)
# print('接收到的数据为:', recv_data.decode('utf-8'))
# 如果接收到数据再创建文件,否则不创建
if recv_data:
with open("[接收]"+file_name, "wb") as f:
f.write(recv_data)
# 关闭套接字
tcp_client_socket.close()
if __name__ == "__main__":
main()
服务器端参考代码
from socket import *
import sys
def get_file_content(file_name):
"""获取文件的内容"""
try:
with open(file_name, "rb") as f:
content = f.read()
return content
except:
print("没有下载的文件:%s" % file_name)
def main():
if len(sys.argv) != 2:
print("请按照如下方式运行:python3 xxx.py 7890")
return
else:
# 运行方式为python3 xxx.py 7890
port = int(sys.argv[1])
# 创建socket
tcp_server_socket = socket(AF_INET, SOCK_STREAM)
# 本地信息
address = ('', port)
# 绑定本地信息
tcp_server_socket.bind(address)
# 将主动套接字变为被动套接字
tcp_server_socket.listen(128)
while True:
# 等待客户端的链接,即为这个客户端发送文件
client_socket, clientAddr = tcp_server_socket.accept()
# 接收对方发送过来的数据
recv_data = client_socket.recv(1024) # 接收1024个字节
file_name = recv_data.decode("utf-8")
print("对方请求下载的文件名为:%s" % file_name)
file_content = get_file_content(file_name)
# 发送文件的数据给客户端
# 因为获取打开文件时是以rb方式打开,所以file_content中的数据已经是二进制的格式,因此不需要encode编码
if file_content:
client_socket.send(file_content)
# 关闭这个套接字
client_socket.close()
# 关闭监听套接字
tcp_server_socket.close()
if __name__ == "__main__":
main()
由于历史原因,QQ最早是使用UDP,现在是UDP+TCP
4. 线程
- 并发:指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
- 并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
python的thread模块可以创建线程,但是threading模块封装了thread模块,提供了对线程更加方便的使用:
4.1 使用threading.Thread创建线程
import threading
def printA(times):
for i in range(times):
print("A")
def printB(times):
for i in range(times):
print("B")
def main():
t1 = threading.Thread(target= printA, kwargs={"times":20})
t2 = threading.Thread(target= printB, args= (20, ))
# t3 = threading.Thread(target= printB, args= (20, ), daemon=True) 设置后台线程
t1.start()
t2.start()
if __name__ == '__main__':
main()
# 结果
A
A
A
A
BA
B
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
AB
B
B
B
注意
1.主线程运行完代码后,会等所有创建的子线程结束,才会结束
2. 如果主线程不等待别的线程结束,主线程一结束,程序就结束了
4.2 通过继承threading.Thread创建线程
继承自threading.Thread,然后重写run方法,最后使用start方法开始线程。
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i) #name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()
- 每个线程默认有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
- 当线程的run()方法结束时该线程完成。
- 无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
4.3 查看有几个线程
import threading
len(threading.enumerate()) # 返回当前环境thread的个数,包括主线程
判断子线程全部结束
if len(threading.enumerate()) <= 1:
pass
注意
- 如果只是调用了start,但是线程还没真正开始执行,此时查看的话,只能看到MainThread
- 只创建了线程没有用,只有当调用了
start并且线程内容开始执行,线程才真正创建了 - 线程的代码结束后,该线程死亡
import threading
def printA():
print("A")
t = threading.Thread(target= printA)
t.start()
print(len(threading.enumerate())
# 只打印出了一个 MainThread
# [<_MainThread(MainThread, started 139875311..]
使用 time.sleep() 先等到 子线程运行,再查看就可以了:
#coding=utf-8
import threading
from time import sleep,ctime
def sing():
for i in range(3):
print("正在唱歌...%d"%i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d"%i)
sleep(1)
if __name__ == '__main__':
print('---开始---:%s'%ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
print('当前运行的线程数为:%d'%length)
if length<=1:
break
sleep(0.5)
4.4 线程共享全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据。共享变量时出现问题:
import threading
import time
g_num = 0
def work1(num):
global g_num
for i in range(num):
g_num += 1
print("----in work1, g_num is %d---"%g_num)
def work2(num):
global g_num
for i in range(num):
g_num += 1
print("----in work2, g_num is %d---"%g_num)
print("---线程创建之前g_num is %d---"%g_num)
t1 = threading.Thread(target=work1, args=(1000000,))
t1.start()
t2 = threading.Thread(target=work2, args=(1000000,))
t2.start()
# 下面这个写法不错,可以学习学习!
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)
a. 互斥锁同步
同步就是协同步调,按预定的先后次序进行运行。如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire()
# 释放
mutex.release()
加上锁的共享变量加法:
import threading
import time
g_num = 0
def test1(num):
global g_num
for i in range(num):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 解锁
print("---test1---g_num=%d"%g_num)
def test2(num):
global g_num
for i in range(num):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 解锁
print("---test2---g_num=%d"%g_num)
# 创建一个互斥锁
# 默认是未上锁的状态
mutex = threading.Lock()
# 创建2个线程,让他们各自对g_num加1000000次
p1 = threading.Thread(target=test1, args=(1000000,))
p1.start()
p2 = threading.Thread(target=test2, args=(1000000,))
p2.start()
# 等待计算完成
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)
锁的缺点:
- 可能造成死锁
- 加锁势必影响性能
b. 死锁问题
#coding=utf-8
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA上锁
mutexA.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程 把mutexB上锁
print(self.name+'----do1---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexB.acquire()
print(self.name+'----do1---down----')
mutexB.release()
# 对mutexA解锁
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexB上锁
mutexB.acquire()
# mutexB上锁后,延时1秒,等待另外那个线程 把mutexA上锁
print(self.name+'----do2---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexA已经被另外的线程抢先上锁了
mutexA.acquire()
print(self.name+'----do2---down----')
mutexA.release()
# 对mutexB解锁
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
- 程序设计时要尽量避免(银行家算法)
- 添加超时时间等
4.5 多线程版的udp聊天室
import socket
import threading
def send_msg(udp_socket):
"""获取键盘数据,并将其发送给对方"""
while True:
# 1. 从键盘输入数据
msg = input("\n请输入要发送的数据:")
# 2. 输入对方的ip地址
dest_ip = input("\n请输入对方的ip地址:")
# 3. 输入对方的port
dest_port = int(input("\n请输入对方的port:"))
# 4. 发送数据
udp_socket.sendto(msg.encode("utf-8"), (dest_ip, dest_port))
def recv_msg(udp_socket):
"""接收数据并显示"""
while True:
# 1. 接收数据
recv_msg = udp_socket.recvfrom(1024)
# 2. 解码
recv_ip = recv_msg[1]
recv_msg = recv_msg[0].decode("utf-8")
# 3. 显示接收到的数据
print(">>>%s:%s" % (str(recv_ip), recv_msg))
def main():
# 1. 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2. 绑定本地信息
udp_socket.bind(("", 7890))
# 3. 创建一个子线程用来接收数据
t = threading.Thread(target=recv_msg, args=(udp_socket,))
t.start()
# 4. 让主线程用来检测键盘数据并且发送
send_msg(udp_socket)
if __name__ == "__main__":
main()
不用管控制台中,由于新接收到的消息,使得提示的文字不整齐——等有了窗口之后,这个就能解决了。
5. 进程
multiprocessing.Processmultiprocessing.Queuemultiprocessing.Poolmultiprocessing.Manager().Queue
5.0 进程和线程的对比
-
程序:例如xxx.py这是程序,是一个静态的——二进制文件
-
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。运行的代码+资源
-
进程是系统进行资源分配和调度的一个独立单位.
-
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
5.1 创建使用进程
和使用线程很像,换个模块换个类。multiprocessing是跨平台版本的多进程模块。
创建了2个进程之后,就一共有了3个进程,可以使用 kill来关闭。
进程之间不共享变量,每个进程都有自己的一份拷贝
import multiprocessing
import time
def worker1():
while True:
print("A")
time.sleep(1)
def worker2():
while True:
print("B")
time.sleep(1)
if __name__=='__main__':
p1 = multiprocessing.Process(target=worker1)
p2 = multiprocessing.Process(target=worker2)
p1.start()
p2.start()
创建进程的时候,会将程序和资源复制一份,但是因为经常有数据没有变化的情况,所以为了提升性能,使用的是 写时拷贝
a. Process使用
创建对象的参数
Process([group [, target [, name [, args [, kwargs]]]]])
| 参数 | 说明 |
|---|---|
| target | 如果传递了函数的引用,可以任务这个子进程就执行这里的代码 |
| args | 给target指定的函数传递的参数,以元组的方式传递 |
| kwargs | 给target指定的函数传递命名参数 |
| name | 给进程设定一个名字,可以不设定 |
| group | 指定进程组,大多数情况下用不到 |
实例方法/属性
Process创建的实例对象的常用方法:
| 方法/属性 | 说明 |
|---|---|
start() |
启动子进程实例(创建子进程) |
is_alive() |
判断进程子进程是否还在活着 |
join([timeout]) |
是否等待子进程执行结束,或等待多少秒 |
terminate() |
不管任务是否完成,立即终止子进程 |
name |
当前进程的别名,默认为Process-N,N为从1开始递增的整数 |
pid |
当前进程的pid(进程号) |
b. 获取当前线程的pid
使用os.getpid():
from multiprocessing import Process
import os
import time
def run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号
print('子进程将要结束...')
if __name__ == '__main__':
print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号
p = Process(target=run_proc)
p.start()
5.2 进程间的通信
- 使用文件写入读出(性能低)
- 使用socket
- 使用队列(只有当进程是同一个代码中创建的时候)
- 使用redis
使用Queue
multiprocessing.Queue对象的方法:
| 方法 | 作用 |
|---|---|
| Queue(队伍大小) | 创建一个队列,如果队伍大小没有传,或者是负值,则代表队伍无穷大 |
| qsize() | 返回此时队伍内的消息数量 |
get() |
从队列获取内容,如果暂时没有内容,会阻塞 |
| get([block, [timeout]] | block为布尔,代表是否阻塞,默认为True;timeout为等待时间,如果时间到了还没有数据,就会抛出异常 |
| get_nowait() | 从队列获取内容,如果暂时没有内容,会报错,相当于 get(False) |
put(内容) |
放入内容,如果队列满了,会阻塞 |
| put( 内容 [block, [timeout] ] ) | |
| put_nowait(内容) | 往队列中放置内容,如果满了,会报错 |
| empty() | 判断是否队列为空 |
| full() | 判断队列是否已满 |
from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) #False
q.put("消息3")
print(q.full()) #True
#因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常
try:
q.put("消息4",True,2)
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
#推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4")
#读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
import multiprocessing
import time
import os
def put_item(q):
print("当前是子线程,pid是:%s"%os.getpid())
for i in range(10):
q.put(i)
print("放入了第%d个消息\n"%i, end='')
def get_item(q):
while True:
msg = q.get()
print("获得了%s\n"%msg, end='')
if q.empty():
break
def main():
msg_queue = multiprocessing.Queue(10)
p1 = multiprocessing.Process(target= put_item, args= (msg_queue,) )
p1.start()
print("当前线程的pid是:%s"%os.getpid())
# time.sleep(1)
get_item(msg_queue)
if __name__ == '__main__':
main()
5.3进程池
multiprocessing.Pool
| 常用函数 | 说明 |
|---|---|
apply_async(func[, args[, kwds]]) |
使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表; |
close() |
关闭Pool,使其不再接受新的任务; |
| terminate() | 不管任务是否完成,立即终止; |
join() |
主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用; |
进程池中的进程间通信,使用multiprocessing.Manager().Queue()
到底使用几个进程的性能最好,和机器的效能有关。
如果不让线程池join,主线程不会等待线程池内任务执行完就会直接退出程序
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
if __nane__="__main__":
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("----start----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
注意:
- 进程池的进程如果产生了异常,是不会打印在控制台的
- 在windows中,必须加上
if __name__ == "__main__":
5.4 多进程拷贝文件夹内的文件+显示进度
import multiprocessing
import os
import time
import random
def copy_file(queue, file_name,source_folder_name, dest_folder_name):
"""copy文件到指定的路径"""
f_read = open(source_folder_name + "/" + file_name, "rb")
f_write = open(dest_folder_name + "/" + file_name, "wb")
while True:
time.sleep(random.random())
content = f_read.read(1024)
if content:
f_write.write(content)
else:
break
f_read.close()
f_write.close()
# 发送已经拷贝完毕的文件名字
queue.put(file_name)
def main():
# 获取要复制的文件夹
source_folder_name = input("请输入要复制文件夹名字:")
# 整理目标文件夹
dest_folder_name = source_folder_name + "[副本]"
# 创建目标文件夹
try:
os.mkdir(dest_folder_name)
except:
pass # 如果文件夹已经存在,那么创建会失败
# 获取这个文件夹中所有的普通文件名
file_names = os.listdir(source_folder_name)
# 创建Queue
queue = multiprocessing.Manager().Queue()
# 创建进程池
pool = multiprocessing.Pool(3)
for file_name in file_names:
# 向进程池中添加任务
pool.apply_async(copy_file, args=(queue, file_name, source_folder_name, dest_folder_name))
# 主进程显示进度
pool.close()
all_file_num = len(file_names)
while True:
file_name = queue.get()
if file_name in file_names:
file_names.remove(file_name)
copy_rate = (all_file_num-len(file_names))*100/all_file_num
print("\r%.2f...(%s)" % (copy_rate, file_name) + " "*50, end="")
if copy_rate >= 100:
break
print()
if __name__ == "__main__":
main()
6. 协程(Python特有)
迭代器、生成器、装饰器——Python的三大器
- 使用协程很简单,用
gevent就可以 - 但是要明白
gevent,要先明白greenlet - 要明白
greenlet,要先明白yield - 要明白
yield,要先明白生成器 - 要明白
生成器,要先明白迭代器
6.1 可迭代对象
from collections import Iterable
isinstance(对象, Iterable)
可迭代对象就是能被for循环调用的东西,自己创建的可迭代对象,需要在内部实现__iter__,返回一个迭代器
class Person(object):
def __init__(self):
self.names = []
def __iter__(self):
"""只要有这个方法,就是可迭代对象,并且能被for调用"""
pass
6.2 迭代器
迭代器保存的是生成数据的方法,而不是保存的数据本身。。
from colletions import Iterator
isinstance(对象, Iterator)
迭代器本身是一个可迭代对象,自己定义的迭代器需要实现__iter__和__next__方法:
class Person(object):
"""这是可迭代对象"""
def __init__(self):
self.names = []
def add(self,item):
self.names.append(item)
def __iter__(self):
"""只要有这个方法,就是可迭代对象,并且能被for调用
此方法应该返回一个迭代器
"""
return PersonIterator(self) # 将自身传入,才能使迭代器获取自己的names列表
class PersonIterator(object):
"""这是一个迭代器,next方法返回内容"""
def __init__(self, person):
self.person = person
self.iterindex = 0
def __iter__(self):
pass
def __next__(self):
if self.iterindex < len(self.person.names):
item = person.names[self.iteridex]
self.iterindex += 1
return item
else:
# 此异常标识 已经取完了
raise StopIteration
p = Person()
p.add("A")
p.add("B")
p.add("C")
isinstance(p, Iterable) # True
piterator = iter(p) # 通过 iter方法能调用 __iter__,接收到返回的迭代器
isinstance(piterator, Iterator) # True
next(piterator) # 通过next方法能调用迭代器的 __next__,接收到返回数据
next(piterator)
next(piterator)
next(piterator) # 异常StopIteration
a. for循环调用过程
- 查看被for循环调用的是否是可迭代对象(是否有
__iter__) - 如果是,则对其调用
iter方法,得到迭代器 - 对该迭代器,重复调用
next方法,从迭代器获取内容 - 如果
next方法抛出异常StopIteration,则会停止迭代
b. 只用一个类
类本身当作调用自身的迭代器
def __init__(self):
self.names = []
self.iterindex = 0
def add(self,item):
self.names.append(item)
def __iter__(self):
"""只要有这个方法,就是可迭代对象,并且能被for调用
此方法应该返回一个迭代器
"""
return self
def __next__(self):
if self.iterindex < len(self.names):
item = self.names[self.iterindex]
self.iterindex += 1
return item
else:
raise StopIteration
c. 迭代器的应用——斐波拉契
class FibbIterator(object):
def __init__(self, max_index):
self.count = 0
self.max_index = max_index
self.a = 0
self.b = 1
def __iter__(self):
return self
def __next__(self):
if self.count < self.max_index:
self.a, self.b = self.b, self.a + self.b
self.count+= 1
return self.a
else:
raise StopIteration()
fib = FibbIterator(10)
for i in fib:
print(i)
d. 使用可迭代对象生成list/tuple的原理
使用如下代码:
l = list(FibbIterator(10))
t = tuple(FibbIterator(10))
生成代码,实际上是产生了一个新的list:
- 创建空list
- 对可迭代对象调用
iter获取迭代器 - 重复调用
next方法获取数据,直到抛出异常 - 将这些获取的数据加入这个新列表中
6.3 ★生成器
生成器是一种特殊的迭代器
a. 生成器表达式
gen = ( a for a in range(10))
b. 生成器函数
def create_num(all_num):
a, b = 0,1
current_num = 0
while current_num < all_num:
# 函数内部有yield,这个就是创建生成器
yield a
a, b = b, a+b
current_num += 1
return "ok"
# 调用得到的是一个生成器
obj = create_num(50)
while True:
try:
# 对生成器使用 next来获取值
ret = next(obj)
print(ret)
#没有值就会抛出异常
except Exception as ret:
# 生成器函数如果有返回值,就会在这里获取
print(ret.value)
break
obj2= create_num(20)
for i in obj2:
print(i)
生成器函数的几个特点:
- 函数内部有
yield之后,这就是个生成器 - 生成器是特殊的迭代器,因为它内部没用
__iter__或者_next__ - 调用生成器函数得到的是一个生成器,而不是返回值
- 通过对生成器调用
next方法来依次获取值,获取的是yield之后的值 - 每次调用,就会从上一次yield结束的位置开始继续运行
- 没有值就会抛出
StopIteration异常没有值就会抛出StopIteration异常 - 生成器函数的返回值,就会在异常对象的
value属性中
使用send来启动生成器
使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
使用send函数的意思是这样的:
- 上次生成器代码停留在
yield 值的位置 - 这次传入 .send(参数), 这个参数将作为
yield 值的结果返回给=左边的值 - 注意第一次如果生成器没有停留在
yield位置,直接使用send(值)会报错,除非是send(None)
def create_num(all_num):
a, b = 0,1
current_num = 0
while current_num < all_num:
# 函数内部有yield,这个就是创建生成器
res = yield a
print(res)
a, b = b, a+b
current_num += 1
return "ok"
generator = create_num(10)
next(generator) # 得到0
value = generator.send("哈哈") # 打印哈哈, value得到 1
value = generator.send("呵呵") # 打印呵呵, value得到 2
6.5 使用yield实现多任务
import time
def task_1():
while True:
print("A")
time.sleep(0.1)
yield
def task_2():
while True:
print("B")
time.sleep(0.1)
yield
def main():
t1 = task_1() # 创建生成器1
t2 = task_2() # 创建生成器2
while True:
next(t1)
next(t2) # 使用next,让函数执行一部分,然后交出控制权
if __name__ == "__main__":
main()
这就是一个协程,函数切换,资源调用最少,性能最好。线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住
6.6 使用 greenlet完成协程
python中的greenlet模块是对 yield进行了简单封装,能够让用户在定义任务的时候不需要自己写yield:
sudo pip3 install greenlet
使用方法:
- 自己定义任务函数,并且将任务函数传递给
greenlet.greenlet - 在任务函数中使用 greenlet对象手动切换控制权
- 使用其中一个对象的
switch方法开始调用
from greenlet import greenlet
import time
def test1():
while True:
print "---A--"
gr2.switch()
time.sleep(0.5)
def test2():
while True:
print "---B--"
gr1.switch()
time.sleep(0.5)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
#切换到gr1中运行
gr1.switch()
6.7 使用gevent协程
gevent是一个网络并发库,内部是使用了协程,它进一步的封装了greenlet
pip3 install gevent
a. 简单使用
import gevent
def f(n):
for i in range(n):
# 可以获取当前gevent
print(gevent.getcurrent(), i)
g1 = gevent.spawn(f, 5) # 使用spawn传入函数和参数,产生greenlet对象来使用
g2 = gevent.spawn(f, 5)
g3 = gevent.spawn(f, 5)
g1.join() # 使用 这个对象.join方法,能够开始调用,先去等待g1执行完
g2.join()
g3.join()
运行结果:
0
1
2
3
4
0
1
2
3
4
0
1
2
3
4
上面可以看出,这个代码是先去执行完g1,再切换g2,再执行g3.
gevent的特点
- 当调用
join方法的时候,才会去开始执行这个代码 - 使用
greenlet或者yield中,如果有 延时/阻塞操作,那整个程序会等待,而gevent遇到延时就会自动切换到别的协程中去执行
b. 延时自动切换
延时和阻塞都需要使用 gevent库的内容,比如 gevent.socket, gevent.sleep,而普通的time.sleep, socket.socket则无法完成自动切换
import gevent
def f(n):
for i in range(n):
print(gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(f, 5)
g2 = gevent.spawn(f, 5)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
运行结果:
<Greenlet at 0x7fa70ffa1c30: f(5)> 0
<Greenlet at 0x7fa70ffa1870: f(5)> 0
<Greenlet at 0x7fa70ffa1eb0: f(5)> 0
<Greenlet at 0x7fa70ffa1c30: f(5)> 1
<Greenlet at 0x7fa70ffa1870: f(5)> 1
<Greenlet at 0x7fa70ffa1eb0: f(5)> 1
<Greenlet at 0x7fa70ffa1c30: f(5)> 2
<Greenlet at 0x7fa70ffa1870: f(5)> 2
<Greenlet at 0x7fa70ffa1eb0: f(5)> 2
<Greenlet at 0x7fa70ffa1c30: f(5)> 3
<Greenlet at 0x7fa70ffa1870: f(5)> 3
<Greenlet at 0x7fa70ffa1eb0: f(5)> 3
<Greenlet at 0x7fa70ffa1c30: f(5)> 4
<Greenlet at 0x7fa70ffa1870: f(5)> 4
<Greenlet at 0x7fa70ffa1eb0: f(5)> 4
c. ★打补丁自动包装gevent+ joinall
- 可以使用
gevent.monkey.patch_all()自动转换所有普通的代码,变成gevent能够自动切换的代码 - 使用
gevent.joinall创建多个对象,而不是每个对象调用join
from gevent import monkey
import gevent
import random
import time
# 对整个代码打包,将普通代码换成gevent代码
# 这样遇到 阻塞/延时 就会自动切换协程
monkey.patch_all() # 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
# 协程直接写在这个里面,这样就不用手动依次调用join了
gevent.joinall([
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
运行结果:
work1 0
work2 0
work1 1
work1 2
work1 3
work2 1
work1 4
work2 2
work1 5
work2 3
work1 6
work1 7
work1 8
work2 4
work2 5
work1 9
work2 6
work2 7
work2 8
work2 9
6.8 gevent协程下载案例
from gevent import monkey
import gevent
import urllib.request
# 有耗时操作时需要
monkey.patch_all()
def my_downLoad(url):
print('GET: %s' % url)
resp = urllib.request.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, 'http://www.baidu.com/'),
gevent.spawn(my_downLoad, 'http://www.itcast.cn/'),
gevent.spawn(my_downLoad, 'http://www.itheima.com/'),
])
6.9 进程、线程、协程简单总结
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
协程 --> 线程(不考虑GIL情况下) --> 进程