NVIDIA Jetson TX2学习教程网址
1.官网
https://www.nvidia.com/zh-cn/autonomous-machines/embedded-systems-dev-kits-modules/
https://developer.nvidia.com/embedded/learn
深度学习和NVIDIA :
开发AI应用程序首先要培训具有大型数据集的深度神经网络。 GPU加速的深度学习框架提供了设计和训练定制深度神经网络的灵活性,并为常用的编程语言(如Python和C / C ++)提供接口。 每个主要的深度学习框架,如TensorFlow,PyTorch等都已经加速了GPU,因此数据科学家和研究人员可以在几分钟内获得高效率,而无需任何GPU编程。
对于将深度神经网络集成到基于云或嵌入式应用程序的应用程序开发人员,Deep Learning SDK提供了高性能库,可实现构建块API,以便直接在其应用程序中实施培训和推理。 通过针对所有GPU平台的单一编程模型 - 从桌面到数据中心再到嵌入式设备,开发人员可以在他们的桌面上开始开发,在云中扩展并部署到他们的边缘设备 - 只需要很少甚至没有代码更改。
https://blog.csdn.net/q_quanting/article/details/81034258
https://developer.nvidia.com/tensorrt TensorRT翻译
TensorRT可以引入在任何模型上训练后的模型You can import trained models from every deep learning framework into TensorRT,提高吞吐量,减少延迟
https://devblogs.nvidia.com/speed-up-inference-tensorrt/ How to Speed Up Deep Learning Inference Using TensorRT
TensorRT supports both C++ and Python and developers using either will find this workflow discussion useful. If you prefer to use Python, refer to the API here in the TensorRT documentation.
例子程序需要一个安装啦cuda的Linux主机或者有gpu的云,例子程序的步骤

2.买板子的群主的网站
https://mp.weixin.qq.com/mp/homepage?__biz=MjM5NTE3Nzk4MQ==&hid=2&sn=7990e1f10a39134cab818617c0beeb51
https://mp.weixin.qq.com/s?__biz=MjM5NTE3Nzk4MQ==&mid=2651233373&idx=2&sn=595ef70e79f5ff2998b0858e919bc349&scene=19#wechat_redirect

https://github.com/dusty-nv/jetson-inference/blob/master/README.md#table-of-contents
1.DIGITS是一个工具,利用该工具,可以在云主机或者PC主机上训练模型,在Jsetson跑来看模型的效果
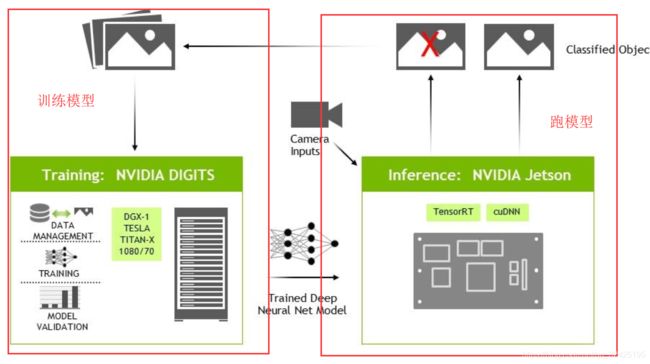
PC主机还负责对jetson刷机,将JetPack刷进jetson TX2中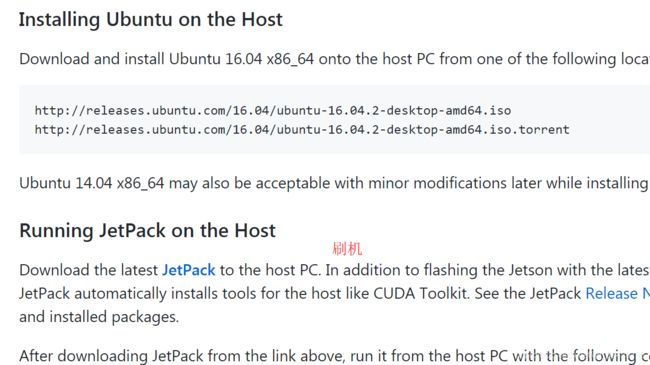
Natively setting up DIGITS on the Host 在本地主机安装设置DIGITS
主机需要安装NVIDIA驱动 cudnn加速器 NVcaffe DIGITS

PC主机启动DIGITS Server
TX2编译程序:代码包括imageNet和tensorNet,使用c/c++编写的
代码编译完成后,则在tx2板子上训练代码
主机上的DIGITs与TX2上的模型的交互:
tx2安装中文输入法:
https://www.cnblogs.com/zhangfengfly/p/6867844.html
https://jkjung-avt.github.io/tensorrt-cats-dogs/:介绍TensorRT
TensorRT是高性能的深度学习的接口库,比caffe+cudnn速度更快。
也是运行上一个的示例程序
$ mkdir -p ~/project
$ cd ~/project
$ git clone https://github.com/dusty-nv/jetson-inference.git
$ cd jetson-inference
$ mkdir build
$ cd build
$ cmake ..
$ make -j4
$ cd aarch64/bin
$ ./imagenet-camera googlenet