python爬取剑桥词典 可查询单词
爬取剑桥词典并具有查询功能
- 使用beasoup模块爬取字母a~z的链接
- 循环遍历,爬取首字母的每个单词的链接,并保存到text文件
- 窗口可视化GUI设计
1 爬取链接
import requests
from bs4 import BeautifulSoup
guidURL = 'https://dictionary.cambridge.org/browse/english-chinese-traditional/'
guideURLs = []
extendURLs = []
def start(url, flag):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0' }
source_code = requests.get(url , headers=headers).text
soup = BeautifulSoup(source_code, 'html.parser')
# print(soup)
#guide url
if flag == 1 :
for each_text in soup.findAll('ul', {'class':'unstyled a--b a--rev'}):
for href in each_text.findAll('a'):
# print(href)
guideURLs.append(href.get('href'))
else: #extend url
for each_text in soup.findAll('div', {'class': 'scroller scroller--style2 scroller--blur scroller--ind-r grad-trans3-pseudo js-scroller'}):
for li in each_text.findAll('ul', {'class': 'unstyled a--b a--rev'}):
for href in li.findAll('a'):
extendURLs.append(href.get('href'))
# print(guideURLs)
if __name__ == '__main__':
# guide url
start(guidURL+'a',1)
# for i in 'abcdefghijklmnopqrstuvwxyz':
# start(guidURL+i,1)
# # extend url
for g in guideURLs:
start(g, 2)
# 文件操作部分
fd = open('guideURLs.txt', 'w') # 该文件保存26个首字母的url
print(guideURLs, file=fd)
fd.close()
fd = open('extendURLs.txt', 'w')# 该文件保存所有单词的url
print(extendURLs, file=fd)
fd.close()
2 获取翻译内容并窗口显示
import requests
from bs4 import BeautifulSoup
import pymysql
from tkinter import messagebox
from tkinter import *
import tkinter as tk
from tkinter import filedialog
# 函数功能:得到翻译内容;将翻译结果保存到text文件和数据库中
def Get_translation(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0', } #请求头
html = requests.get(url=url, headers=headers).content
soup = BeautifulSoup(html, 'html.parser')
try:
word = soup.find('span', attrs={'class': 'headword'}).getText()
except:
word = soup.find('h2', attrs={'class': 'headword'}).getText()
print(word)
translation_all = soup.find_all('div', attrs={'class': 'def-block pad-indent'})
detail_list = list()
for translation in translation_all:
detail = translation.find('b', attrs={'class': 'def'}).getText()
detail_list.append(detail)
detail_list_to_str = ';'.join(detail_list)
# print(detail_list)
# 向数据库中插入数据语句
query = """insert into words_demo(word, detail) values (%s,%s)"""
values = (word, detail_list_to_str)
print('value 值为:', values)
cursor.execute(query, values)
word_dic[word] = detail_list
# print(word_dic)
# 写文件
with open('tranlation.txt', 'a', encoding='utf-8') as f:
f.write(str(word_dic))
f.close()
return word_dic
# ***************************窗口可视化部分**********************************#
window = tk.Tk()
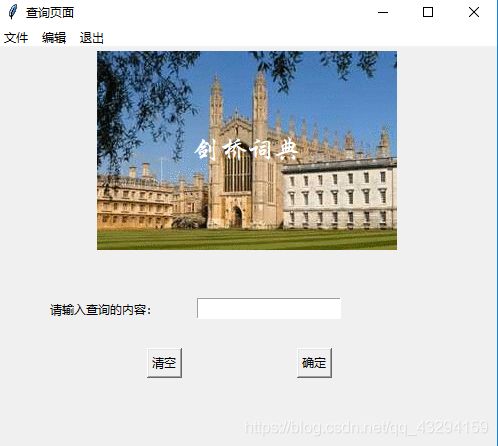
window.title("查询页面")
window.geometry("500x400")
# 设置背景
photo = tk.PhotoImage(file='image.gif')
theLabel = tk.Label(window, text="剑桥词典", justify=tk.LEFT, image=photo, compound=tk.CENTER,font=("华文行楷", 20), fg="white") # CENTER 为关键字,设为为背景,fg为颜色
theLabel.pack()
# 构建文本框
tk.Label(window, text='请输入查询的内容:').place(x=50, y=250)
# tk.Label(window, text='查询结果为:').place(x=70, y=150)
# Entry输入文本字符串
varWord = tk.StringVar(window, value='')
get_text = tk.Entry(window, textvariable=varWord)
get_text.place(x=200, y=250)
# 创建菜单
def Open_file():
filedialog.askopenfilename(title='打开text文件', filetypes=[('TXT', '*.txt')])
def cut(event=None):
get_text.event_generate("<>")
def copy(event=None):
get_text.event_generate("<>")
def paste(event=None):
get_text.event_generate('<>')
file_menu = Menu(window, tearoff=0)
file_menu.add_command(label='单词url文本',)
file_menu.add_command(label='首字母url文本',)
# 创建编辑菜单
editmenu = Menu(window, tearoff=False)
# 创建编辑下拉内容
editmenu.add("command", label="剪切", command=cut)
editmenu.add_command(label="复制", command=copy)
editmenu.add_command(label="粘贴", command=paste)
mebubar = Menu(window)
mebubar.add_command(label="文件", command=Open_file)
mebubar.add_cascade(label="编辑", menu=editmenu)
mebubar.add_command(label="退出", command=window.quit)
# 跟窗口显示菜单栏
window.config(menu=mebubar)
# 确认键函数说明
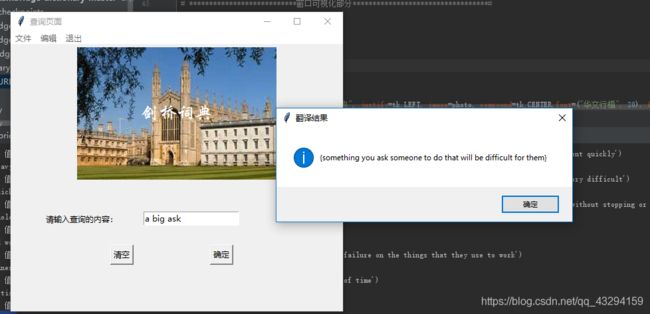
def confirm():
Word = varWord.get()
if Word in word_dic:
for k, v in word_dic.items():
if Word == k:
Word_translation = v
# print(Word, '翻译成功')
break
else:
Word_translation = '未找到单词'
# try:
# with open('usrs_info.pickle', 'rb') as usr_file:
Word_translation_window = messagebox.showinfo(title='翻译结果', message=Word_translation) # 弹窗 return True/False
print(Word_translation_window)
# 清空键函数说明
def clear():
varWord.set('')
print('取消')
# 创建两个按键
button_ok = tk.Button(window, text='确定', command=confirm).place(x=300, y=300)
button_clear = tk.Button(window, text='清空', command=clear).place(x=150, y=300)
# ********************************************结束***************************************
# 将字符串转化为列表
urls = eval(open('extendURLs.txt').read())
# ***************************尝试创建并连接数据库*******************************************
conn = pymysql.connect(host="localhost", user='root', password='123456', database='dictionary', charset='utf8')
cursor = conn.cursor()
try:
cursor.execute('create table words_demo(word CHAR(100),detail CHAR(200))')
print('数据库创建成功!')
except:
print('数据库已存在!')
# ********************************************结束***************************************
if __name__ == '__main__':
word_dic = {}
for i in urls[1:10]: #从中抽取十个进行测试
# print(i)
Get_translation(i)
print(word_dic)
cursor.close()
conn.commit()
conn.close()
window.mainloop()
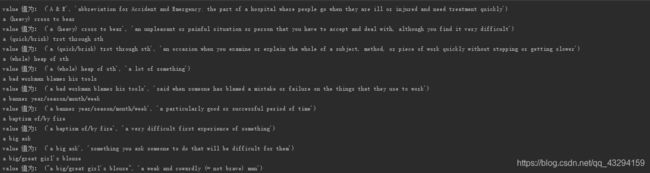
执行结果如下: