python 网络爬虫实例:爬取大学排名信息
目录
主要程序及框架
优化
format方法的相关约定
中文对齐问题
主要程序及框架

程序中封装成三个模块:(三个主要函数)

import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag): #过滤不是tr标签的
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
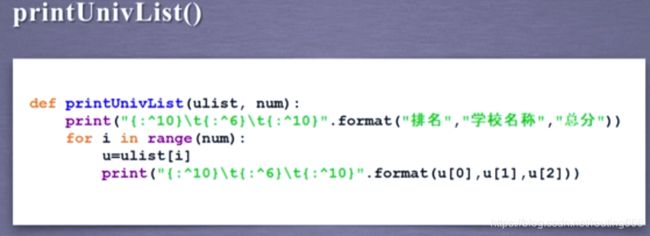
def printUnivList(ulist, num):
#使用可视化输出
print("{:^10}\t{:^10}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^10}\t{:^10}".format(u[0],u[1],u[2]))
def main():
unifo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(unifo,html)
printUnivList(unifo,20)
#打印20所大学的信息
main()

优化:
format方法的相关约定:
 中文对齐问题
中文对齐问题

更改函数:
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
