Python有道翻译2.1版本爬虫实现
web端的有道翻译前几个月就已经有人破解了,链接:http://blog.csdn.net/nunchakushuang/article/details/75294947。
不过本人使的时候却只返回错误代码errorcode:50了,之后有人说把Request URL中的translate_o的_o去掉就可以返回翻译结果,在去掉之后的确能返回翻译结果,不过翻译的水平相比web端降低了很多。很可能去掉_o后使用的是一个很旧的版本接口。于是有了以下的尝试,以下是翻译请求报文
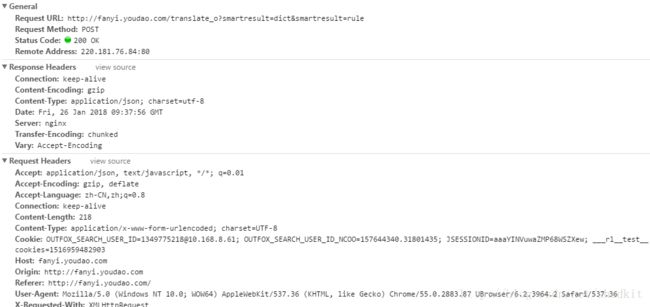

Form Data的数据和以前的版本没有什么区别,和以前一样
salt:加密用到的盐。sign:签名字符串。i:需要进行翻译的字符串- 其他的数据类型都是固定写法
返回错误码的原因很有可能是salt和sign的构成变了,这是有道web端网页源码的底端

有两个js脚本,通过
站长工具:http://tool.chinaz.com/tools/jsformat.aspx把里面的js代码格式化。
在fanyi.min.js的代码中有我们需要的salt和sign两个参数的构造过程
t.translate = function(e, t) {
T = u("#language").val();
var n = b.val(),
r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10)),
o = u.md5(E + n + r + O),
a = n.length;
if (D(), x.text(a), a > 5e3) {
var l = n;
n = l.substr(0, 5e3),
o = u.md5(E + n + r + O);
var c = l.substr(5e3);
c = (c = c.trim()).substr(0, 3),
u("#inputTargetError").text("有é“翻译å—æ•°é™åˆ¶ä¸º5000å—,“" + c + "â€åŠå…¶åŽé¢æ²¡æœ‰è¢«ç¿»è¯‘!").show(),
x.addClass("fonts__overed")
} else x.removeClass("fonts__overed"),
u("#inputTargetError").hide();
f.isWeb(n) ? i() : s({
i: n,
from: _,
to: C,
smartresult: "dict",
client: E,
salt: r,
sign: o,
doctype: "json",
version: "2.1",
keyfrom: "fanyi.web",
action: e || "FY_BY_DEFAULT",
typoResult: !1
},
t)
},
t.showResult = a
}),
salt的值是r,sign的值是o,r的值和以前一样是当前时间加一个随机数,可能变化的就是sign值了,o的值等于E+n+r+O,r的值已经确定,E等于client的值,在请求报文中查看是一个常量“
fanyideskweb”,n等于i的值,在请求报文中查看是请求翻译的字符串,变动的是O的值,O的值也在
fanyi.min.js的代码中,而且是一个常量O = "aNPG!!u6sesA>hBAW1@(-",O的值有有别于以前的版本,sign值的变动也是因为这个原因导致,从目前来看出现错误码的原因很有可能是sign值的变动所导致,
于是本人调整了以前版本的常量字符串进行调试,不过依然得不到翻译结果,很明显这只是其中的一个变动而已。
从目前来看Form Data中的数据已经没有什么问题了,出现错误的其他原因可能是在Headers中了,
服务器可能会检查头部的某些地方,除了 Content-Length和Cookie以外其他都是常量,照搬就是了,把Headers的常量添加到代码中再调试还是出错,还有可能出现问题的就是Conten-Length和Cookie了,不出所料问题就是在Cookie的某些地方。
在进行多次请求后可以发现Cookie前面并没有改变,可见前面的字符串可以照搬,变动的只有最后的数字,而且最后的数字似乎和salt的值差不多,但随机减去了一些值![]()
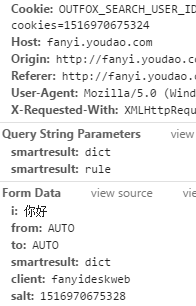 ,cookie最后的数字生成是由
,cookie最后的数字生成是由
,cookie最后的数字生成是由

这个函数的_rl.src中的js脚本生成的,在脚本中我们可以找到
function t() {
var a = (new Date).getTime();
return b.cookie = "___rl__test__cookies=" + a,
F = r("OUTFOX_SEARCH_USER_ID_NCOO"),
-1 == F && r("___rl__test__cookies") == a && (F = 2147483647 * Math.random(), q("OUTFOX_SEARCH_USER_ID_NCOO", F)),
E = r("P_INFO"),
E = -1 == E ? "NULL": E.substr(0, E.indexOf("|")),
["_ncoo=" + F, "_nssn=" + E, "_nver=" + y, "_ntms=" + a].join("&")
}
以下是具体实现代码
import urllib.request
import gzip
import urllib.parse
import json
import time
import random
import hashlib
def translate(content):
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
#定义变量
client = 'fanyideskweb'
ctime = int(time.time() * 1000)
salt = str(ctime + random.randint(1, 10))
# key = 'rY0D^0\'nM0}g5Mm1z%1G4' 以前版本的秘钥
key = 'aNPG!!u6sesA>hBAW1@(-'
sign = hashlib.md5((client + content + salt + key).encode('utf-8')).hexdigest()
#表单数据
data = {}
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = salt
data['sign'] = sign
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CL1CKBUTTON'
data['typoResult'] = 'false'
data = urllib.parse.urlencode(data).encode('utf-8')
#请求头
head = {}
head['Accept'] = 'application/json, text/javascript, */*; q=0.01'
head['Accept-Encoding'] = 'gzip, deflate'
head['Accept-Language'] = 'zh-CN,zh;q=0.9'
head['Connection'] = 'keep-alive'
head['Content-Type'] = 'application/x-www-form-urlencoded; charset=UTF-8'
head['Cookie'] = '[email protected]; JSESSIONID=aaa9_E-sQ3CQWaPTofjew; OUTFOX_SEARCH_USER_ID_NCOO=2007801178.0378454; fanyi-ad-id=39535; fanyi-ad-closed=1; ___rl__test__cookies=' + str(ctime)
head['Host'] = 'fanyi.youdao.com'
head['Origin'] = 'http://fanyi.youdao.com'
head['Referer'] = 'http://fanyi.youdao.com/'
head[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
head['X-Requested-With'] = 'XMLHttpRequest'
request = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(request)
with gzip.open(response, 'rb') as f:
response = f.read()
# response=response.read().decode('utf-8')
target = json.loads(response)
result = target['translateResult'][0][0]['tgt']
return result
content = input('请输入需要翻译的内容:')
print(translate(content))最后看了一下js代码,有道目前在web端提供的免费翻译Version当前还是2.1,但是在fanyi.min.js代码中可以找到 Version3.0的表单数据,具体有什么区别现在还不得而知。