简单的网络爬虫-喜马拉雅音频爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(来自百度百科)
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
下面我们的实例是根据聚焦网络爬虫技术:
前段时间,有人给我推荐一本书有关时间管理的,听的时候,我也顺手把他爬下来。
1、使用的python编程语言:python3.6
所使用的库:requests,json,os
其中requests为第三方库,需要下载安装(安装步骤略)pip install requests
2、确定搜索的网址和内容
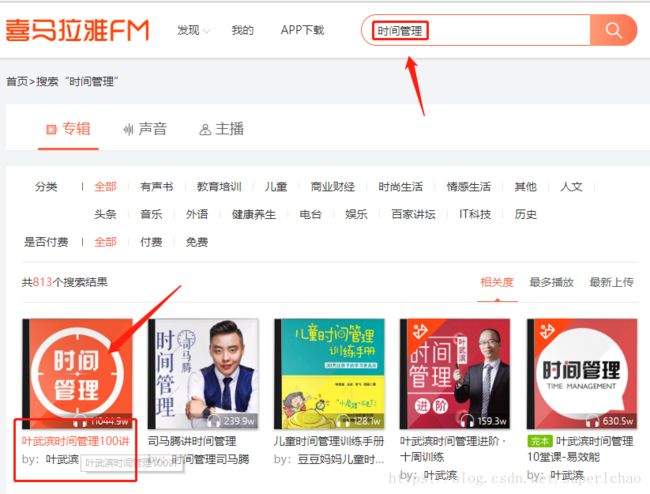
2.1 打开浏览器,在喜马拉雅音频官网找到时间管理100讲
2.2 打开开发者工具或按F12,打开network查看请求信息
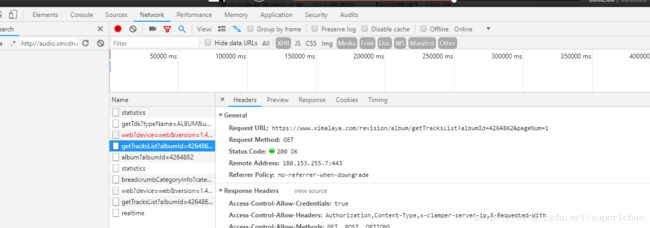
2.3 然后点击【播放全部】会出现新的请求

2.3 分析数据

User-Agent:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36
Request URL1:
https://www.ximalaya.com/revision/play/album?albumId=4264862&pageNum=1&sort=-1&pageSize=30
我们可以发现这里是请求的获取音频的列表,打开Respose栏可以看到:一个json样式的返回结果
{"ret":200,"msg":"声音播放数据","data"....
下面的wKgJJVe7B6fBZr00ABqiOS5YkyA154是获取音频:
Request URL2:
http://audio.xmcdn.com/group18/M06/AE/D7/wKgJJVe7B6fBZr00ABqiOS5YkyA154.m4a
2.4 下面我们就从Request URL1中的response中获取类似Request URL2的url和对应的名称
在Preview中点开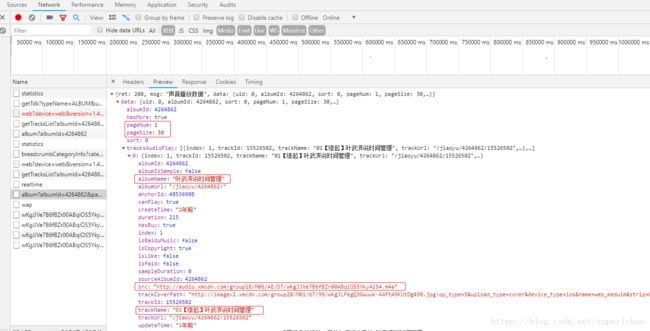
albumId:4264862 --书的id
albumName:"叶武滨说时间管理" -- 书名
src:"http://audio.xmcdn.com/group18/M06/AE/D7/wKgJJVe7B6fBZr00ABqiOS5YkyA154.m4a" --音频url
trackName:"01【缘起】叶武滨说时间管理" --音频的名称
3.代码实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
import os
class ShiJianGuanLi(object):
def __init__(self, book_name="", book_id=None):
if book_id is None:
print("book_id不能为空")
return
#模拟浏览器 浏览器的登陆模式
self.headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36",
}
self.bookid = book_id
self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=%s&pageNum={}&sort=-1&pageSize=30" % self.bookid
self.book_name = book_name
self.book_url = []
#获取页数 页面有8页 其实100讲 每页30 获取四页就足够了
for i in range(8):
url = self.start_url.format(i+1)
self.book_url.append(url)
def get_book_msg(self):
"""获取书的音频和名称"""
#存放所有书名和地址
all_list = []
# 打印请求的地址页数
print(self.book_url)
#获取相应的页面数据
for url in self.book_url:
r = requests.get(url, headers = self.headers)
py_dict = json.loads(r.content.decode())
# print(py_dict)
#获取首页的数据信息
book_list = py_dict['data']['tracksAudioPlay']
# 打印字典的key values 值
# self.printDict(book_list)
for book in book_list:
#获取每段音频的名称和地址
list ={}
list['name'] = book['trackName']
list['bookname'] = book['albumName']
list['src'] = book['src']
#打印list
# print(list)
all_list.append(list)
# 打印list
# print(all_list)
return all_list
def save(self, all_list):
"""保存音频"""
for i in all_list:#i实际就是每个音频的名字和url
#喜马拉雅/{}.m4a 通过format() 把() 里的数据替换{} 中
#print(i)
#书名自定义
if not self.book_name:
self.book_name = i['bookname']
dir = "喜马拉雅/{}/".format(self.book_name)
#检查是否有相应的文件夹并创建目录
if not os.path.exists(dir):
print("创建书名目录:.%s"%dir)
os.makedirs(dir)
#os中“?”会报错将其换为""
i['name'] = i['name'].replace("?","").replace('"',"")
#在目录下创建一个喜马拉雅的文件夹
with open(r'{}/{}.m4a'.format(dir, i['name']),'ab')as f:
r = requests.get(i['src'], headers = self.headers)
print("正在下载:{}...".format(i['name']),end="")
f.write(r.content)
print("\t下载完成!")
def run(self):
#获取所有的音频名称和地址
all_list = self.get_book_msg()
self.save(all_list)
def printDict(self,dict):
#辅助工具,用于打印节点模块
if type(dict) is dict:
# 打印字典的key values 值
for key, value in dict.items():
print(key, ":", value)
elif type(dict) is list:
for d in dict:
for key, value in d.items():
print(key, ":", value)
if __name__=='__main__':
sjgl = ShiJianGuanLi("时间管理","4264862")
sjgl.run()4、运行后需要等待一段时间。可以查看运行目录进行查看下载进度。