Python——爬取小说网站的整本小说
编译环境:pycharm
需要的库:requests,lxml,bs4,BeautifulSoup,os
思路如下:
-
首先可以先建立一个文件,使用os库中的os.makedirs("文件名;
if not os.path.exists("福妻高照"):
os.makedirs("福妻高照")找到你想要下载的那篇小说,在这里我是在百度上搜索小说网站后,随便选择了一个小说网站:起点女生网,找了一篇小说(本周强推《福妻高照》),复制得到小说链接,随后对该网站进行解析,常用步骤如下:
url="https://book.qidian.com/info/1016755751#Catalog"
req=requests.get(url=url)
req.encoding="utf-8"
print("响应码",req.status_code)
html=req.text
bf=BeautifulSoup(html,"lxml")随后是如何找到自己想要的东西,步骤如下(可能存在差异,网站不同,标签的使用可能不同):
-
点击一本小说,找到目录部分:点击鼠标右键,点击审查元素,在Elements中可以获得网站的h5源码,

-
点击左上角的这个(上图箭头所指部分),点中之后可以看到它变成蓝色了啦,然后在这个小箭头变成蓝色后,随便找到一个目录,点击一下,在源码中就会直接选中该部分在源码中的位置,然后在这个基础上,去找它上一级的块,(最好找到的是有class的块,如果上一级没有class,可以再往上找)

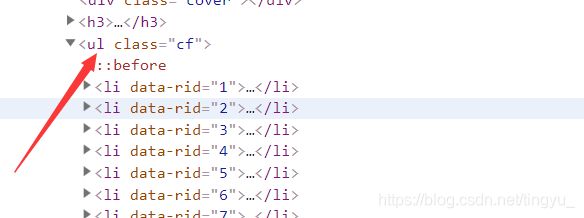
-
找到ul 中的内容后,再对这一块进行解析,不过需要注意的是,find_all获取的内容是存放在列表中的,需要获取这个列表的内容,将其强制转换成字符串类型后才能对其进行解析,
-
在这一步的解析中,打开一个li标签,会看到每一章小说的链接是存放在a标签下的href中的,可以解析获取所有章节目录ul 块下li 的a标签,将其存放在一个列表中,这样就得到了一个章节名和章节链接的列表,对这个列表进行遍历,一章一章的对具体章节的小说内容进行获取,
-
对于具体章节的小说内容进行获取的时候,在for循环中,获取每一项的章节名称和章节链接,将名字和链接传入下载单章小说的函数中。传入名字是为了定义每一章小说下载后存放文件,传入练级诶是为了下载;
-
一般情况下,这个链接是不完整的,需要进行一定的拼接(观察打印出的链接少哪一部分,然后使用字符串拼接的方式拼接一下即可)。(以防在向函数传数据的时候传不进去,可以先打印一下,检查是否获取了正确的名字和链接)。
-
获取了章节小说的链接之后,对其进行解析,获得小说内容所在的块,提取出文本即可,这一部分详看博客Python——爬取单章小说内容
具体代码如下:
import requests
# import lxml
from bs4 import BeautifulSoup
import os
if not os.path.exists("福妻高照"):
os.makedirs("福妻高照")
url="https://book.qidian.com/info/1016755751#Catalog"
req=requests.get(url=url)
req.encoding="utf-8"
print("响应码",req.status_code)
html=req.text
bf=BeautifulSoup(html,"lxml")
# print(bf)
ul=bf.find_all("ul",class_="cf")
# print(ul)
bf1=BeautifulSoup(str(ul[0]),"lxml")
# print(bf1)
a_list=bf1.find_all("a")
# print(a_list)
def getDanzData(name,url):
name=name+".txt"
url="https:"+url
req=requests.get(url=url)
req.encoding="utf-8"
html=req.text
bf=BeautifulSoup(html,"lxml")
# print(bf)
div = bf.find_all("div", class_="read-content j_readContent")
# print(div)
txt=div[0].text
with open("福妻高照/%s"%name,"w",encoding="utf-8")as file:
file.write(txt)
file.close()
print("%s下载成功"%name)
for item in a_list:
name=item.string
url=item.get("href")
getDanzData(name,url)