一、数据库连接
连接数据库前,请先确认以下事项:
1.已经创建了数据库 TESTDB;
2.在TESTDB数据库中已经创建了表 EMPLOYEE;
3.EMPLOYEE表字段为 FIRST_NAME, LAST_NAME, AGE, SEX 和 INCOME;
4.连接数据库TESTDB使用的用户名为 "testuser" ,密码为 "123456",可以自己设定或者直接使用root用户名及其密码,Mysql数据库用户授权请使用Grant命令;
5.在电脑上已经安装了 Python MySQLdb 模块;
实例代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 使用execute方法执行SQL语句
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取一条数据
data = cursor.fetchone()
print "Database version : %s " % data
# 关闭数据库连接
db.close()
二、创建数据库表
如果数据库连接存在我们可以使用execute()方法来为数据库创建表,如下所示创建表EMPLOYEE:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "123456", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 如果数据表已经存在使用 execute() 方法删除表。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# 创建数据表SQL语句
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
# 关闭数据库连接
db.close()
三、数据库插入操作
以下实例使用执行 SQL INSERT 语句向表 EMPLOYEE 插入记录:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "123456", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# 关闭数据库连接
db.close()
四、数据库查询操作
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据:
1.fetchone(): 该方法获取下一个查询结果集。结果集是一个对象;
2.fetchall():接收全部的返回结果行;
3.rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数;
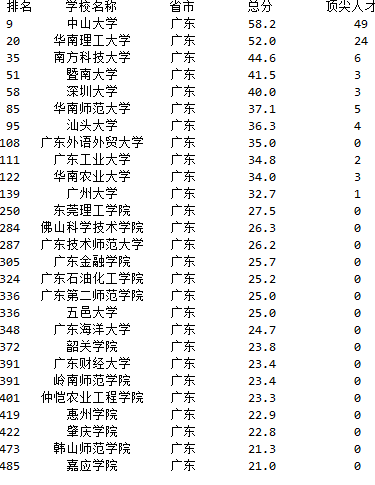
六、学校顶尖人才爬虫
实例代码:
import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东技术师范大学"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","顶尖人才"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[10]))
def main(num):
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
printUnivList(num)
main(500)
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东技术师范大学"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","顶尖人才"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[10]))
def main(num):
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
printUnivList(num)
main(500)
结果显示:
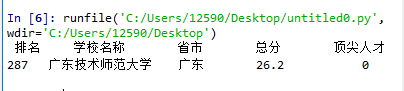
若想寻找广东的大学的信息,只要将上述代码中的“广东技术师范大学”改成“广东”,结果显示: