爬虫实战之爬取中国天气网
打开中国天气网:http://www.weather.com.cn/textFC/db.shtml对网页源代码做一个简单分析:
import requests
from bs4 import BeautifulSoup
#网页的解析函数
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.content.decode('utf-8')
soup = BeautifulSoup(text,'lxml')
conMidtab = soup.find('div',class_ = 'conMidtab')
print(conMidtab)#打印输出看输出是否符合条件
def main():
url = 'http://www.weather.com.cn/textFC/db.shtml'
parse_page(url)
if __name__ == '__main__':
main()然后获取每个城市的天气信息:
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.content.decode('utf-8')
soup = BeautifulSoup(text,'lxml')
conMidtab = soup.find('div',class_ = 'conMidtab')
tables = conMidtab.find_all('table')
#查看是否拿到了每个城市的天气
for table in tables:
print(table)
print('=' * 30)然后我们查看到所有天气信息都在yr标签里面:

因此我们需要取拿到所有的tr标签,但发现从第三个tr标签开始的信息才是我们需要的,因此不要前两个:
#查看是否拿到了每个城市的天气
for table in tables:
trs = table.find_all('tr')[2:]
for tr in trs:
print(tr)
print('='*30)先来看看一个城市中的所有区域的天气,如果没有问题,那么其它城市也没有问题:
for table in tables:
trs = table.find_all('tr')[2:]
for tr in trs:
print(tr)
print('='*30)
break然后就可以提取出其中的信息,比如城市名和最低气温等:

我们发现这些信息存在td标签里面,因此要拿到td标签里面的数据,因此获取整个华北地区所有城市的最低气温的代码:
for table in tables:
trs = table.find_all('tr')[2:]
for tr in trs:
tds = tr.find_all('td')
city_td = tds[0]
city = list(city_td.stripped_strings)[0]#获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
print({'城市':city,'最低气温':min_temp})
break{'城市': '北京', '最低气温': '-7'}
{'城市': '天津', '最低气温': '-5'}
{'城市': '河北', '最低气温': '-4'}
{'城市': '山西', '最低气温': '-16'}
{'城市': '内蒙古', '最低气温': '-16'}但现在的代码有问题,因为返回的不是城市而是省份,因此改为:
for tr in trs:
tds = tr.find_all('td')
city_td = tds[1]
city = list(city_td.stripped_strings)[0]#获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
print({'城市':city,'最低气温':min_temp})输出结果:
{'城市': '北京', '最低气温': '-7'}
{'城市': '晴', '最低气温': '-7'}
{'城市': '晴', '最低气温': '-6'}
{'城市': '晴', '最低气温': '-4'}
{'城市': '晴', '最低气温': '-9'}
{'城市': '晴', '最低气温': '-8'}这样也不对,因为当从一个省开始的时候城市的确放在1,但是从城市开始的时候就变成天气了,因此采用enumerate()方法来解决这个问题,它会去遍历生成器然后返回两个值,索引和值,因此获取全国各地所有城市最低气温的程序如下:
import requests
from bs4 import BeautifulSoup
#网页的解析函数
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.content.decode('utf-8')
soup = BeautifulSoup(text,'html5lib')#由于html5lib容错性较好因此用它不用lxml
conMidtab = soup.find('div',class_ = 'conMidtab')
tables = conMidtab.find_all('table')
#查看是否拿到了每个城市的天气
for table in tables:
trs = table.find_all('tr')[2:]
for index,tr in enumerate(trs):
tds = tr.find_all('td')
city_td = tds[0]
if index == 0:
city_td = tds[1]
city = list(city_td.stripped_strings)[0]#获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
print({'城市':city,'最低气温':min_temp})
def main():
urls = [
'http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml',
'http://www.weather.com.cn/textFC/gat.shtml'
]
for url in urls:
parse_page(url)
if __name__ == '__main__':
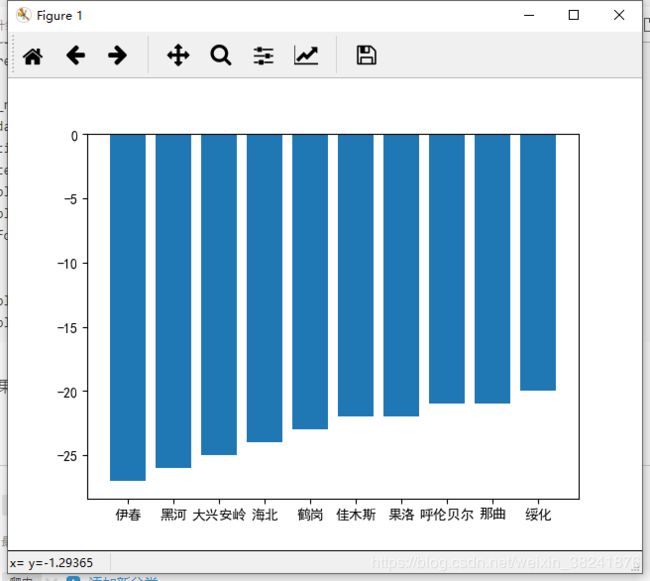
main()然后再将前十的城市做一个数据可视化:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
ALL_DATA = []
#网页的解析函数
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.content.decode('utf-8')
soup = BeautifulSoup(text,'html5lib')#由于html5lib容错性较好因此用它不用lxml
conMidtab = soup.find('div',class_ = 'conMidtab')
tables = conMidtab.find_all('table')
#查看是否拿到了每个城市的天气
for table in tables:
trs = table.find_all('tr')[2:]
for index,tr in enumerate(trs):
tds = tr.find_all('td')
city_td = tds[0]
if index == 0:
city_td = tds[1]
city = list(city_td.stripped_strings)[0]#获取标签里面的字符串属性返回一个生成器,因此要转化为一个列表
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
ALL_DATA.append({'城市':city,'最低气温':int(min_temp)})#将数据添加到列表当作
def main():
urls = [
'http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml',
'http://www.weather.com.cn/textFC/gat.shtml'
]
for url in urls:
parse_page(url)
# 分析数据,根据最低气温进行排序
ALL_DATA.sort(key=lambda data:data['最低气温'])
data = ALL_DATA[0:10]#取出前10的最低气温及其城市
return data
if __name__ == '__main__':
datas = main()
city = []
temp = []
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
for data in datas:
city.append(data['城市'])
temp.append(data['最低气温'])
plt.bar(range(len(city)),temp,tick_label=city)
plt.show()运行效果如下: