Keras搭建yolo4目标检测平台
=参考链接https://blog.csdn.net/weixin_44791964/article/details/106014717
学习yolo4之前强烈建议大家先学学yolo,把几个大概的模块熟悉一下。
yolo4对比yolo3最大的不同,在于一个是网络主体有改进,一个是loss函数有变化,其他的解码模块还是一样的。
网络部分:


左边的是yolo3的网络部分, 右边是yolo4的网络部分,yolo4对比yolo3网络部分,
一个是激活函数用了Mish激活,
将DarknetConv2D的激活函数由LeakyReLU修改成了Mish,卷积块由DarknetConv2D_BN_Leaky变成了DarknetConv2D_BN_Mish
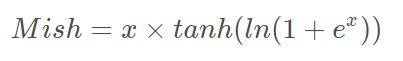
class Mish(Layer):
'''
Mish Activation Function.
.. math::
mish(x) = x * tanh(softplus(x)) = x * tanh(ln(1 + e^{x}))
Shape:
- Input: Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
- Output: Same shape as the input.
Examples:
>>> X_input = Input(input_shape)
>>> X = Mish()(X_input)
'''
def __init__(self, **kwargs):
super(Mish, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.tanh(K.softplus(inputs))
def get_config(self):
config = super(Mish, self).get_config()
return config
def compute_output_shape(self, input_shape):
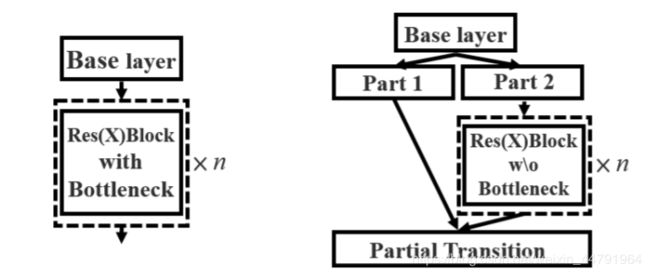
return input_shape一个是每个resblock_body块里面加入了CSP结构,
def resblock_body(x, num_filters, num_blocks, all_narrow=True):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
preconv1 = ZeroPadding2D(((1,0),(1,0)))(x)
preconv1 = DarknetConv2D_BN_Mish(num_filters, (3,3), strides=(2,2))(preconv1)
#左边的路
shortconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
#右边的路:残差结构
mainconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Mish(num_filters//2, (1,1)),
DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (3,3)))(mainconv)
mainconv = Add()([mainconv,y])
postconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(mainconv)
#合在一起
route = Concatenate()([postconv, shortconv])
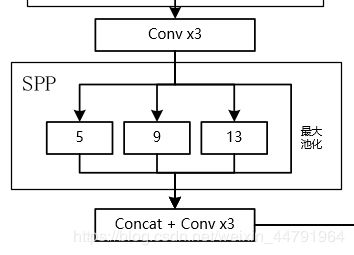
return DarknetConv2D_BN_Mish(num_filters, (1,1))(route)一个是SPP池化结构
其可以它能够极大地增加感受野,分离出最显著的上下文特征。
#-------------------------------------Conv3 +SPP结构-------------------------------------------
#19x19 head
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(darknet.output)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
maxpool1 = MaxPooling2D(pool_size=(13,13), strides=(1,1), padding='same')(y19)
maxpool2 = MaxPooling2D(pool_size=(9,9), strides=(1,1), padding='same')(y19)
maxpool3 = MaxPooling2D(pool_size=(5,5), strides=(1,1), padding='same')(y19)
y19 = Concatenate()([maxpool1, maxpool2, maxpool3, y19])
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)一是PANet结构
PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取。在完成特征金字塔从下到上的特征提取后,还需要实现从上到下的特征提取。

#--------------------------------------PANet结构----------------------------------------------
#分岔,一个是直接输出,一个是卷积上采样
y19_upsample = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(y19)
#38x38 head
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(darknet.layers[204].output)
#合并 Concat + Conv *5
y38 = Concatenate()([y38, y19_upsample])
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
#分岔, 一个是直接输出,一个是卷积上采样
y38_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(y38)
#76x76 head
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(darknet.layers[131].output)
#Concat + Conv *5
y76 = Concatenate()([y76, y38_upsample])
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
#76x76 output
y76_output = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y76_output)
#38x38 output
y76_downsample = ZeroPadding2D(((1,0),(1,0)))(y76)
y76_downsample = DarknetConv2D_BN_Leaky(256, (3,3), strides=(2,2))(y76_downsample)
#Concat + Conv *5
y38 = Concatenate()([y76_downsample, y38])
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38_output = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y38_output)
#19x19 output
y38_downsample = ZeroPadding2D(((1,0),(1,0)))(y38)
y38_downsample = DarknetConv2D_BN_Leaky(512, (3,3), strides=(2,2))(y38_downsample)
#Concat + Conv *5
y19 = Concatenate()([y38_downsample, y19])
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19_output = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y19_output)整个网络结构的变化就是这样了,
第二个大变化就是loss函数,包含三个部分
- 实际存在的框,CIOU LOSS。
- 实际存在的框,预测结果中置信度的值与1对比;实际不存在的框,预测结果中置信度的值与0对比,该部分要去除被忽略的不包含目标的框。
- 实际存在的框,种类预测结果与实际结果的对比。
"""YOLO_v4 Model Defined in Keras."""
from functools import wraps
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.engine.base_layer import Layer
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from utils4.utils4 import compose
from nets.yolo4 import yolo_head
def softmax_focal_loss(y_true, y_pred, gamma=2.0, alpha=0.25):
"""
Compute softmax focal loss.
Reference Paper:
"Focal Loss for Dense Object Detection"
https://arxiv.org/abs/1708.02002
# Arguments
y_true: Ground truth targets,
tensor of shape (?, num_boxes, num_classes).
y_pred: Predicted logits,
tensor of shape (?, num_boxes, num_classes).
gamma: exponent of the modulating factor (1 - p_t) ^ gamma.
alpha: optional alpha weighting factor to balance positives vs negatives.
# Returns
softmax_focal_loss: Softmax focal loss, tensor of shape (?, num_boxes).
"""
# Scale predictions so that the class probas of each sample sum to 1
#y_pred /= K.sum(y_pred, axis=-1, keepdims=True)
# Clip the prediction value to prevent NaN's and Inf's
#epsilon = K.epsilon()
#y_pred = K.clip(y_pred, epsilon, 1. - epsilon)
y_pred = tf.nn.softmax(y_pred)
y_pred = tf.maximum(tf.minimum(y_pred, 1 - 1e-15), 1e-15)
# Calculate Cross Entropy
cross_entropy = -y_true * tf.math.log(y_pred)
# Calculate Focal Loss
softmax_focal_loss = alpha * tf.pow(1 - y_pred, gamma) * cross_entropy
return softmax_focal_loss
def sigmoid_focal_loss(y_true, y_pred, gamma=2.0, alpha=0.25):
"""
Compute sigmoid focal loss.
Reference Paper:
"Focal Loss for Dense Object Detection"
https://arxiv.org/abs/1708.02002
# Arguments
y_true: Ground truth targets,
tensor of shape (?, num_boxes, num_classes).
y_pred: Predicted logits,
tensor of shape (?, num_boxes, num_classes).
gamma: exponent of the modulating factor (1 - p_t) ^ gamma.
alpha: optional alpha weighting factor to balance positives vs negatives.
# Returns
sigmoid_focal_loss: Sigmoid focal loss, tensor of shape (?, num_boxes).
"""
sigmoid_loss = K.binary_crossentropy(y_true, y_pred, from_logits=True)
pred_prob = tf.sigmoid(y_pred)
p_t = ((y_true * pred_prob) + ((1 - y_true) * (1 - pred_prob)))
modulating_factor = tf.pow(1.0 - p_t, gamma)
alpha_weight_factor = (y_true * alpha + (1 - y_true) * (1 - alpha))
sigmoid_focal_loss = modulating_factor * alpha_weight_factor * sigmoid_loss
#sigmoid_focal_loss = tf.reduce_sum(sigmoid_focal_loss, axis=-1)
return sigmoid_focal_loss
def box_iou(b1, b2):
"""
Return iou tensor
Parameters
----------
b1: tensor, shape=(i1,...,iN, 4), xywh
b2: tensor, shape=(j, 4), xywh
Returns
-------
iou: tensor, shape=(i1,...,iN, j)
"""
# Expand dim to apply broadcasting.
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# Expand dim to apply broadcasting.
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou
def box_giou(b1, b2):
"""
Calculate GIoU loss on anchor boxes
Reference Paper:
"Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression"
https://arxiv.org/abs/1902.09630
Parameters
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
Returns
-------
giou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
# calculate IoU, add epsilon in denominator to avoid dividing by 0
iou = intersect_area / (union_area + K.epsilon())
# get enclosed area
enclose_mins = K.minimum(b1_mins, b2_mins)
enclose_maxes = K.maximum(b1_maxes, b2_maxes)
enclose_wh = K.maximum(enclose_maxes - enclose_mins, 0.0)
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
# calculate GIoU, add epsilon in denominator to avoid dividing by 0
giou = iou - 1.0 * (enclose_area - union_area) / (enclose_area + K.epsilon())
giou = K.expand_dims(giou, -1)
return giou
def box_diou(b1, b2):
"""
Calculate DIoU loss on anchor boxes
Reference Paper:
"Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression"
https://arxiv.org/abs/1911.08287
Parameters
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
Returns
-------
diou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
# calculate IoU, add epsilon in denominator to avoid dividing by 0
iou = intersect_area / (union_area + K.epsilon())
# box center distance
center_distance = K.sum(K.square(b1_xy - b2_xy), axis=-1)
# get enclosed area
enclose_mins = K.minimum(b1_mins, b2_mins)
enclose_maxes = K.maximum(b1_maxes, b2_maxes)
enclose_wh = K.maximum(enclose_maxes - enclose_mins, 0.0)
# get enclosed diagonal distance
enclose_diagonal = K.sum(K.square(enclose_wh), axis=-1)
# calculate DIoU, add epsilon in denominator to avoid dividing by 0
diou = iou - 1.0 * (center_distance) / (enclose_diagonal + K.epsilon())
# calculate param v and alpha to extend to CIoU
#v = 4*K.square(tf.math.atan2(b1_wh[..., 0], b1_wh[..., 1]) - tf.math.atan2(b2_wh[..., 0], b2_wh[..., 1])) / (math.pi * math.pi)
#alpha = v / (1.0 - iou + v)
#diou = diou - alpha*v
diou = K.expand_dims(diou, -1)
return diou
def _smooth_labels(y_true, label_smoothing):
label_smoothing = K.constant(label_smoothing, dtype=K.floatx())
return y_true * (1.0 - label_smoothing) + 0.5 * label_smoothing
def yolo4_loss(args, anchors, num_classes, ignore_thresh=.5, label_smoothing=0, use_focal_loss=False, use_focal_obj_loss=False, use_softmax_loss=False, use_giou_loss=False, use_diou_loss=False):
'''Return yolo4_loss tensor
Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss
Returns
-------
loss: tensor, shape=(1,)
'''
num_layers = len(anchors)//3 # default setting
yolo_outputs = args[:num_layers]
y_true = args[num_layers:]
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [0,1,2]]
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0]))
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]
loss = 0
total_location_loss = 0
total_confidence_loss = 0
total_class_loss = 0
m = K.shape(yolo_outputs[0])[0] # batch size, tensor
mf = K.cast(m, K.dtype(yolo_outputs[0]))
for l in range(num_layers):
object_mask = y_true[l][..., 4:5]
true_class_probs = y_true[l][..., 5:]
if label_smoothing:
true_class_probs = _smooth_labels(true_class_probs, label_smoothing)
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True)
pred_box = K.concatenate([pred_xy, pred_wh])
# Darknet raw box to calculate loss.
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]
# Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)
object_mask_bool = K.cast(object_mask, 'bool')
def loop_body(b, ignore_mask):
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0])
iou = box_iou(pred_box[b], true_box)
best_iou = K.max(iou, axis=-1)
ignore_mask = ignore_mask.write(b, K.cast(best_iou其他部分都是一样的
结果:
下载全部的代码在下载里面找