pandas读取,写入txt文件,统计某列元素的重复次数
1.用pandas读取txt数据文件,每行数据之间是用空格分开的。
原数据如下:

代码如下:
from pandas import DataFrame
import pandas as pd
da = pd.read_table('a.txt',header = None,delim_whitespace=True)
print(da)
结果如下:
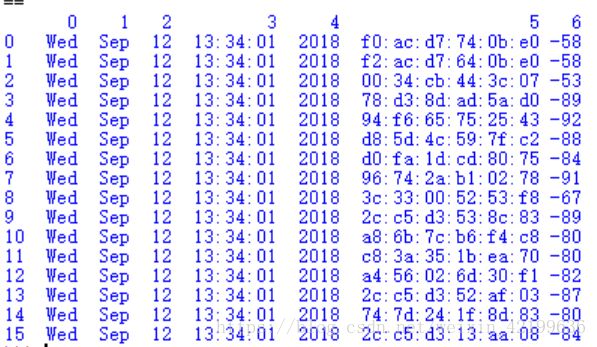
注意: 如果原始数据每行的元素使用逗号(,)分割的话,在读取时,应使用:
pd. read_csv() 函数。
2.现在将数据的列命名为A,B,C,D,E,F,G
代码如下:
from pandas import DataFrame
import pandas as pd
import numpy as np
da = pd.read_table('a.txt',names=['A','B','C','D','E','F','G'],header = None,delim_whitespace=True)
print(da)
其中,增加了names函数。
结果如下:

3.提取指定列的数据
例如,提取上面F列的数据。
代码如下:
from pandas import DataFrame
import pandas as pd
import numpy as np
da = pd.read_table('a.txt',names=['A','B','C','D','E','F','G'],header = None,delim_whitespace=True)
print(da['F']) #方式一
Q = da.F.values #方式二
print(Q) 这里有两种方式
结果分别如下:

4.统计某一列的每个元素各自出现的次数
例如,统计F列的元素各自出现的次数
代码:
from pandas import DataFrame
import pandas as pd
import numpy as np
da = pd.read_table('a.txt',names=['A','B','C','D','E','F','G'],header = None,delim_whitespace=True)
M = da['F'].value_counts()
print(M)结果如下:

5.筛选出重复次数为1的值
代码如下:
from pandas import DataFrame
import pandas as pd
import numpy as np
da = pd.read_table('CS.txt',names=['A','B'],header = None,delim_whitespace=True)
ta = da[da.B==1]
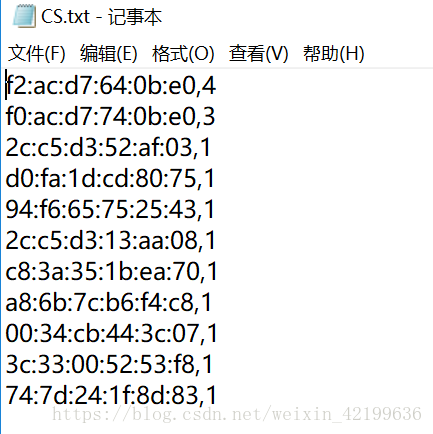
print(ta.A.values)其中cs.txt文件如下:

结果如下:

6.向 txt文件中写入数据
代码如下:
from pandas import DataFrame
import pandas as pd
import numpy as np
da = pd.read_table('a.txt',names=['A','B','C','D','E','F','G'],header = None,delim_whitespace=True)
M = da['F'].value_counts()
M.to_csv('CS.txt')这里使用 to_csv() 函数。pandas读写csv和txt两种文件的用法一样。
结果如下:
参考:https://blog.csdn.net/shener_m/article/details/81047669
参考1:http://www.360doc.com/content/18/0612/11/277688_761682676.shtml
参考2:https://blog.csdn.net/Vinsuan1993/article/details/79972319