谷歌翻译-爬虫-JS解密
测试了下,并没有完全跟网页中一致,只是有输入单词的翻译,没有联想、词性等
嗯,等以后看看再优化吧!
现在就直接看代码吧。
目标地址(谷歌翻译国内)
# google_fy.py
from urllib import parse
import requests
import execjs
def get_tk(q: str):
with open('google_fy.js', 'r', encoding='utf-8') as f:
JS = f.read()
j = execjs.compile(JS)
return j.call('zo', q).replace('&tk=', '')
class Translate(object):
def __init__(self):
self.headers = {
'referer': 'https://translate.google.cn/',
# 'sec-fetch-mode': 'cors',
# 'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
# 'x-client-data': 'CIe2yQEIpLbJAQjBtskBCKmdygEI4qjKAQjKr8oBCJywygEIzrDKARj1sMoB'
}
# self.session = requests.session()
class GoogleTranslate(Translate):
def __init__(self, q: str):
super().__init__()
url = 'https://translate.google.cn/translate_a/single'
data = {'client': "webapp", 'sl': 'auto', 'tl': 'zh-CN', 'hl': 'zh-CN', 'dt': 'at', 'otf': '2', 'ssel': '3',
'tsel': '0', 'kc': '1', 'tk': get_tk(q), 'q': q}
url = url + '?' + parse.urlencode(data)
print(url)
response = requests.get(url, headers=self.headers)
print(response.text)
GoogleTranslate('Agent')
JS 代码
<!-- google_fy.js -->
var vo = function (a, b) {
try {
return JSON.parse(a)
} catch (d) {
var c = Im.M();
b.js = a;
b.error = d.message;
c.log("jsonParseErr", b);
throw d;
}
};
var wo = function (a) {
return function () {
return a
}
},
xo = function (a, b) {
for (var c = 0; c < b.length - 2; c += 3) {
var d = b.charAt(c + 2);
d = "a" <= d ? d.charCodeAt(0) - 87 : Number(d);
d = "+" === b.charAt(c + 1) ? a >>> d : a << d;
a = "+" === b.charAt(c) ? a + d & 4294967295 : a ^ d
}
return a
},
yo = '436280.2672482813',
zo = function (a) {
var b = yo;
var d = wo(String.fromCharCode(116));
c = wo(String.fromCharCode(107));
d = [d(), d()];
d[1] = c();
c = "&" + d.join("") + "=";
d = b.split(".");
b = Number(d[0]) || 0;
for (var e = [], f = 0, g = 0; g < a.length; g++) {
var k = a.charCodeAt(g);
128 > k ? e[f++] = k : (2048 > k ? e[f++] = k >> 6 | 192 : (55296 === (k & 64512) && g + 1 < a.length && 56320 === (a.charCodeAt(g + 1) & 64512) ? (k = 65536 + ((k & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = k >> 18 | 240, e[f++] = k >> 12 & 63 | 128) : e[f++] = k >> 12 | 224, e[f++] = k >> 6 & 63 | 128), e[f++] = k & 63 | 128)
}
a = b;
for (f = 0; f < e.length; f++) {
a += e[f];
a = xo(a, "+-a^+6");
}
a = xo(a, "+-3^+b+-f");
a ^= Number(d[1]) || 0;
0 > a && (a = (a & 2147483647) + 2147483648);
a %= 1E6;
return c + (a.toString() + "." + (a ^ b))
};
分析过程:按F12 -> network -> 输入待翻译内容,应该直接就能看到响应。
![]()
下面是具体参数,我是在键入不同词翻译 对比参数发现,大部分参数都是固定的。主要就是【tk】这个参数。没换一个词 tk 就会有变化。
那么接下来的工作主要就是找到 tk 赋值或则加密的地方了。
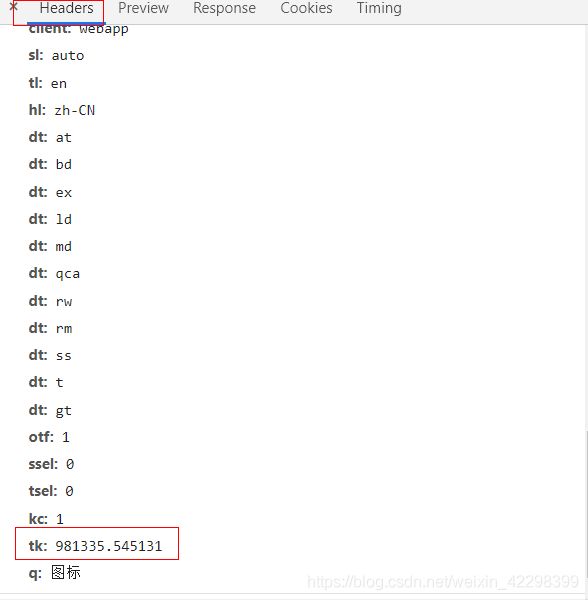
复制响应URL(不带参数的)
进入Sources界面 按照下图操作,将上一步URL 添加到断点。这里是设置浏览器在请求该网址之前暂停,进入调试状态。
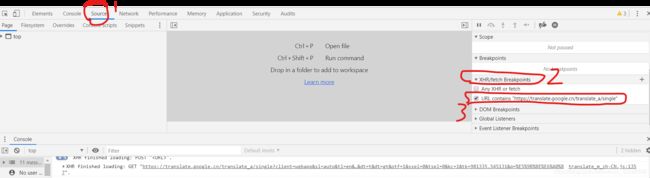
然后就回到翻译输入框中键入想翻译的内容。
可以看到下图中间就是js代码了。不过代码全都集中在一起(我这里是点击了格式化代码按钮 【一对大括号】在截图左下角 line处)。
这里简单说明下吧,暂停处就是即将发送请求的地方(看到send应该就懂了),
图右边函数调用栈就是在运行到暂停处之前调用的函数。
函数调用栈框里,函数调用过程是下面的调用上面的,依此类推。
既然这样就可以看看整个调用栈中 具体在哪一步对参数进行加密了。
从上开始往下看吧,点击调用栈处下一个函数。

经过观察后,我发现在Sj 函数即将return的时候。是可以看到 k.send(a, c ,d ,e) 中的 a 就是URL中的参数。并且 a 中就有 tk 。
a = "/translate_a/single?client=webapp&sl=auto&tl=zh-CN&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&clearbtn=1&otf=1&ssel=0&tsel=3&kc=2&tk=687182.840818&q=open"
非常棒,已经找到入口了。
接下来 再往下看 。直到在函数中的参数没有发现 tk 为止。因为只有上一个函数没有 tk 但是后面一个函数中又出现了 tk ,这才能确定 tk 是在哪个函数中添加到URL参数中的。
经过一些排查后确定 wp函数并没有 出现 tk ,而 tp 中则有 tk。
下图最下方调用 tp 函数传递的 r 就是URL,但这个并没有包含任何参数。
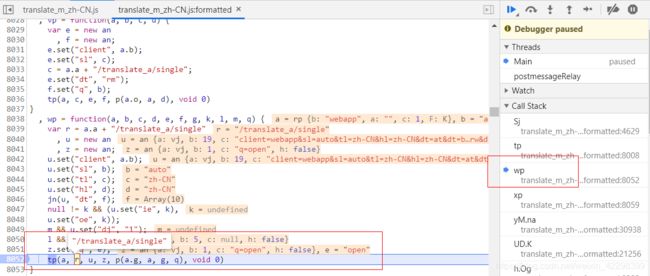
上图 于 下图对比 发现 tp 接收的第二个参数 本来是没有带参数的,而到了 tp 运行完后要调用 Sj 的时候 tp 第二个参数 多了很多内容。

在 tp 进入后第一行、最后一行 添加断点, 将其他断点移除。从新调试,当停在tp函数内后,就要小心点了最好用步进,避免错过了。
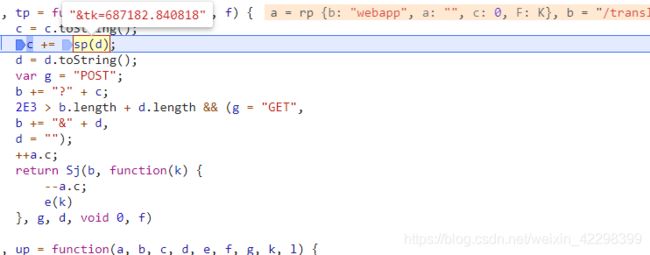
可以看到上图中就已经有 tk 的值了,是 sp(d)获取的。
一直深入下去就找到 tk 以及其他参数的根源在哪了。
tk 加密的则是在 sp(d)函数中调用的 zo(q)函数中。
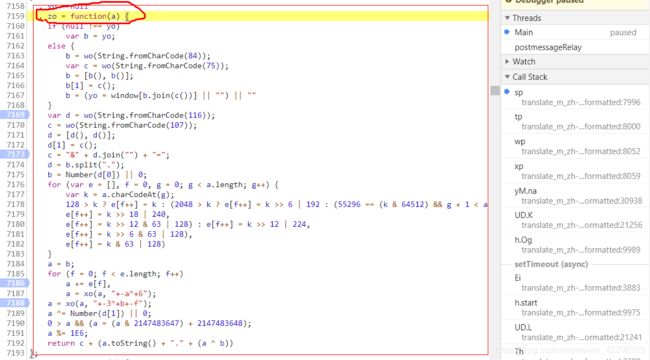
经过调试上面 zo 函数,并定义一些固定值 就形成了文章开头部分的JS代码。
完!!!
第一次写博客,排版随意弄的,请见谅!!!