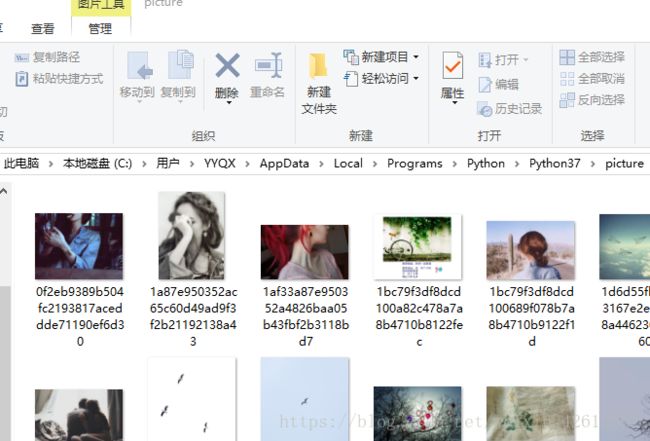
Python网络爬虫实例2:用Python访问百度贴吧保存图片
1.进入一个百度贴吧,并打开一个帖子,复制该网址
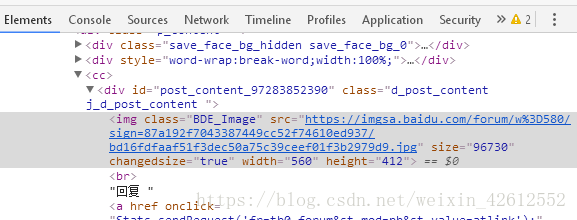
2.找到图片,单击右键选择审查元素,复制图片网址前的字符串
img class="BDE_Image" src=
3.编写脚本文件
将网址复制放入 download函数中的url中
url = 'https://tieba.baidu.com/p/4765578807'将复制的字符串放入find_img函数中赋值给a的语句:
a = html.find('img class="BDE_Image" src=') 更改要保存的页数
def download(folder = 'picture',pages = 3): 整体代码如下:
import urllib.request
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.90 Safari/537.36 2345Explorer/9.3.2.17331 ')
response = urllib.request.urlopen(req)
html = response.read()
return html
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img class="BDE_Image" src=')
while a != -1:
b = html.find('.jpg',a,a+255)
img_addrs.append(html[a+27:b+4]) ##img class="BDE_Image" src= 共26个字符,因此img_addrs应从第27个字符开始,.jpg共4个字符
a = html.find('img class="BDE_Image" src=',b)
return img_addrs
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)
def download(folder = 'picture',pages = 3):
os.mkdir(folder)
os.chdir(folder)
url = 'https://tieba.baidu.com/p/4765578807'
page_num = 0
for i in range(pages):
page_num += 1
##page_url = url + str(page_num)
page_url = url + '?pn=' + str(page_num)
img_addrs = find_imgs(page_url)
save_imgs(folder,img_addrs)
if __name__ == '__main__':
download()4.编译运行
运行结果如下,图片被保存入指定文件夹