pyhon3爬虫爬取飞卢小说网小说
想看小说,不想看花里胡哨的网页,想着爬下来存个txt,顺便练习一下爬虫。
随便先找了个看起来格式比较好的小说网站《飞卢小说网》做练习样本,顺便记录一下练习成果。
ps:未登录,不能爬取VIP章节部分
目录
使用工具
网页结构分析
爬虫实现
结果展示
使用工具
python3 ,beaufulsoup库,request库
网页结构分析
随便在网站找了个小说,分析网页结构:
https://b.faloo.com/f/479986.html 以此页为例,可以发现,目录页全部整齐的在后面加上了章数https://b.faloo.com/p/479986/4.html
这里不用更换网址的方法,选用 找到存放目录的a标签,逐一获取链接的方式 练习。
首先,分析目录页结构,对元素右键进行检查

可以发现,目录链接全部存放在table里,很整齐的在类名为td_0的td中;
接着分析每节内容,发现小说内容全部储存在 id=content 的div中:

爬虫实现
首先需要获取这本小说所有的章节链接,从网页结构可以发现,链接全部存储再table的td中。
用get_download_url方法循环获取table中tr的内容,再使用BeautifulSoup的find方法挨个提取td中的a标签链接,存储到urls中方便后续使用
def get_download_url(self):
req = requests.get(url=self.target)
html = req.text
tr_bf = BeautifulSoup(html,'lxml')
trs = tr_bf.find('div',class_='ni_list').find_all('tr')
for tr in trs:
for td in tr.find_all('td'):
td_bf = BeautifulSoup(str(td))
td = td_bf.find_all('td')
for each in td :
#print(each.string)
a = each.find('a')
if a != None :
#print(a.get('href'))
self.names.append(each.string)
self.urls.append(a.get('href'))
self.nums += 1
print('共有%f章需要下载'%(int(self.nums)))然后,写提取每章内容的方法get_contents,用requests类爬取到内容,用find_all方法
这里发现爬取到的小说没有换行,用replace方法将两个空格替换成换行,debug发现空格编码为\u3000;
爬取到的内容每章后面有230字符的广告,也剔除掉。
def get_contents(self,target):
target = 'http:'+target
req = requests.get(url=target)
html = req.text
bf=BeautifulSoup(html,'lxml')
texts = bf.find_all('div',id='content')
if len(texts)>0:
texts = texts[0].text.replace('\u3000\u3000','\r\n')
return texts[:-230]
else:
return None接着将内容写入文件中:
def writer(self,name,path,text):
#writer_flag = True
with open(path,'a',encoding='utf-8')as f:
f.write(name +'\n')
f.writelines(text)
f.write('\n\n')最后,整理一下:
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
print('已获取下载链接')
print('开始下载')
i=3
print(len(dl.names))
for i in range(len(dl.urls)):
content =dl.get_contents(dl.urls[i])
if content != None:
dl.writer(dl.names[i],'大唐发明家.txt',content)
sys.stdout.write("已下载:%.1f%%" % float((i/dl.nums)*100) + '\r')
sys.stdout.flush()
print('下载完成')
结果展示
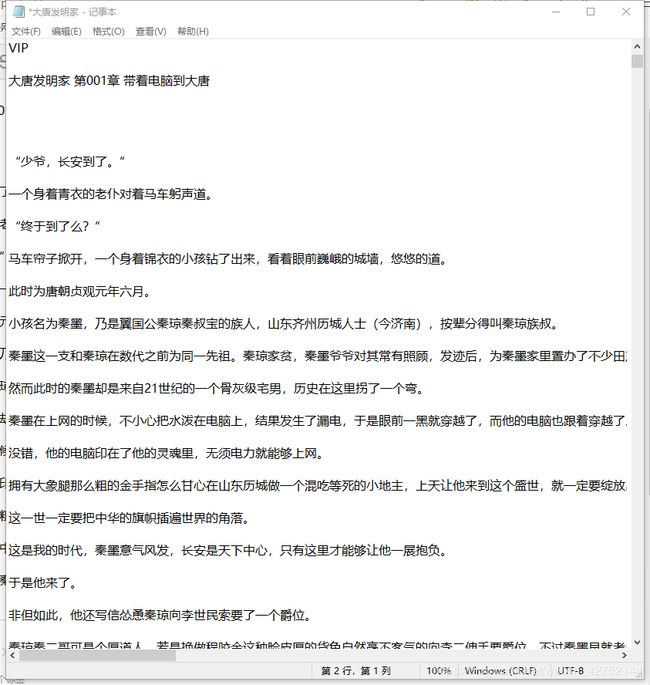
很简单的一个demo,还要需要完善的地方。
源码在有需要再附上,欢迎交流。