Python Scrapy 爬取 前程无忧招聘网
Python 爬虫目录
1、Python3 爬取前程无忧招聘网 lxml+xpath
2、Python3 Mysql保存爬取的数据 正则
3、Python3 用requests 库 和 bs4 库 最新爬豆瓣电影Top250
4、Python Scrapy 爬取 前程无忧招聘网
5、持续更新…
关于Scrapy 首先先要了解点基础
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 网络抓取 所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
-
对spider来说,爬取的循环类似下文:
以初始的URL初始化Request,并设置回调函数。
当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取
start_urls 中的URL, 并以 parse 为回调函数生成 Request 。 -
在回调函数内分析返回的(网页)内容,返回 Item 对象、dict、Request 或者一个包括三者的可迭代容器。
返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。 -
在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
-
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports
存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。 之后将讨论这些spider。
现在切入正题
首先先得安装scrapy,具体安装网上有教程
接着在终端创建项目(看清楚目录再输入命令)
scrapy startproject qcwy_job(qcwy_job是项目名称)
创建完项目后
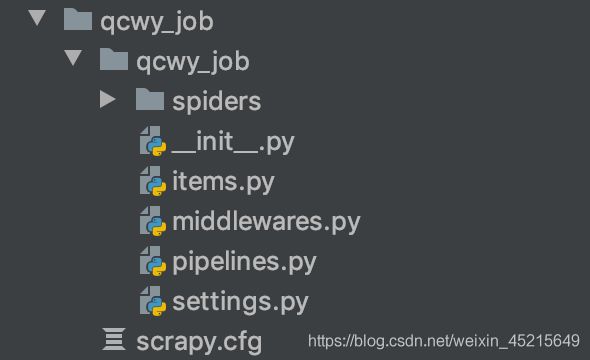
- spiders 存放爬虫的文件
- items.py 定义数据类型
- middleware.py 存放中间件
- piplines.py 存放数据的有关操作
- settings.py 配置文件
- scrapy.cfg 总的控制文件
创建完项目后,应该会有几个提示 ,你可以cd 到spider文件下
创建爬虫文件 qcwy_spider 以及域名为search.51job.com。
scrapy genspider qcwy_spider "search.51job.com"
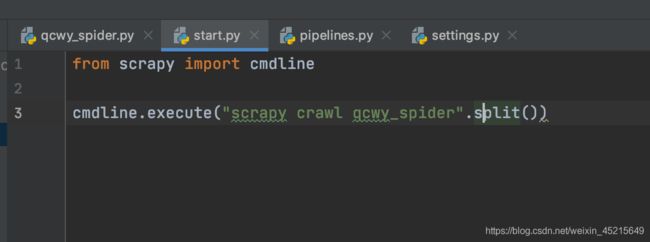
在总的控制文件scrapy.cfg 同级目录创建start.py文件
在配置文件settings.py 修改一些属性
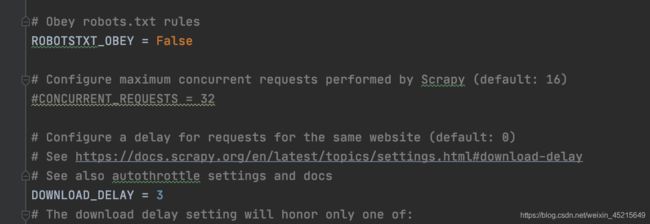
把机器人协议改成False
DOWNLOAD_DELAY = 3 取消注释
随后在请求头中加入伪装头

最后把 ITEM_PIPELINES 取消注释 后续会用到

代码展示
qcwy_spider.py 代码展示
import scrapy
from qcwy_job.items import QcwyJobItem
class QcwySpiderSpider(scrapy.Spider):
name = 'qcwy_spider'
allowed_domains = ['search.51job.com'] #域名
start_urls = []
# 生成大量url
for i in range(1, 3):
url_pre = 'https://search.51job.com/list/000000,000000,0000,00,9,99,' \
'%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,'
url_end = '.html?'
url = url_pre + str(i) + url_end # URL拼接
start_urls.append(url) # 将url添加至start_urls
def parse(self, response):
dom_list = response.xpath('//div[@class="dw_table"]/div[@class="el"]')
for t in dom_list:
item = QcwyJobItem()
# 1、岗位名称
item['job_name'] = t.xpath('.//p/span/a[@target="_blank"]/@title').get()
# 2、公司名称
item['company_name'] = t.xpath('.//span[@class="t2"]//@title').get()
# 3、工作地点
item['address'] = t.xpath('.//span[@class="t3"]/text()').get()
# 4、薪资
item['salary'] = t.xpath('.//span[@class="t4"]/text()').get()
yield item
items.py 代码展示
import scrapy
class QcwyJobItem(scrapy.Item):
job_name = scrapy.Field()
company_name = scrapy.Field()
address = scrapy.Field()
salary = scrapy.Field()
pipelines.py 代码展示
from itemadapter import ItemAdapter
import pymysql
from twisted.enterprise import adbapi
import copy
class QcwyJobPipeline:
def __init__(self):
dbparams = {
'host': 'localhost', # mysql服务器地址
'port': 3306, # mysql服务器端口号
'user': 'root', # 用户名
'passwd': '123123', # 密码
'db': 'save_data', # 数据库名
'charset': 'utf8' # 连接编码
}
self.post = adbapi.ConnectionPool('pymysql', **dbparams)
def process_item(self, item, spider):
# 深拷贝
cityItem = copy.deepcopy(item)
# 保存数据
query = self.post.runInteraction(self._conditional_insert, cityItem)
return item
def _conditional_insert(self, tb, item):
# 数据持久化
sql = "INSERT INTO scrapy_job_info(job_name,company_name,address,salary)values(%s,%s,%s,%s)"
params = (item['job_name'], item['company_name'], item['address'], item['salary'])
tb.execute(sql, params)
然后在start.py 右键运行即可
调式代码可以去了解下scrapy shell + 网址 (其他参数)
终端也可以运行代码
有什么问题,欢迎提问