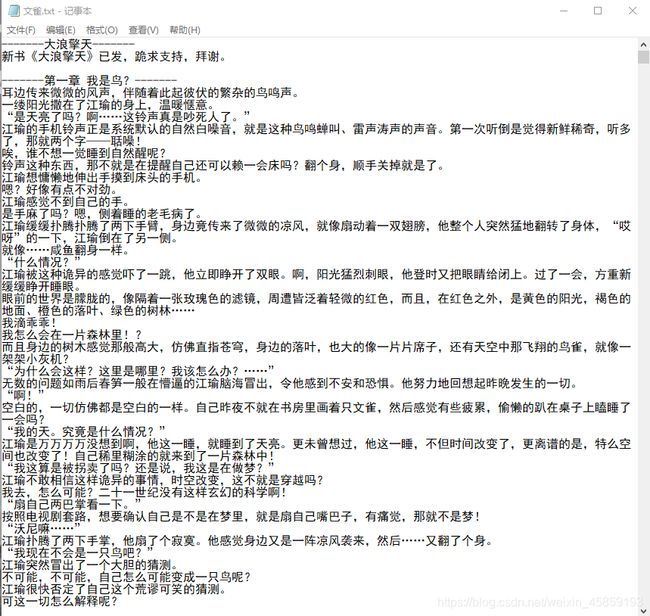
python爬取全部起点小说
目录
- 爬虫是什么?
- 离不开的四大步骤
- xpath和requests常用语法
- xpath下载
- 代码块
- 效果
爬虫是什么?
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
好了,既然已经了解了爬虫那么我们就分析一下爬虫需要的步骤吧!
离不开的四大步骤
1.目标url 网站
2.发送请求
3.解析数据
4.保存数据
所以我们在抓取小说的时候是不是要依次访问每一层的网址…(以文雀为例)
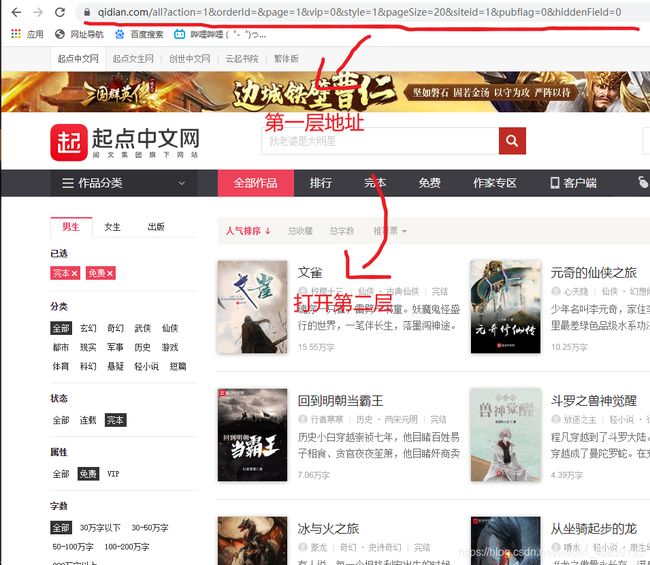
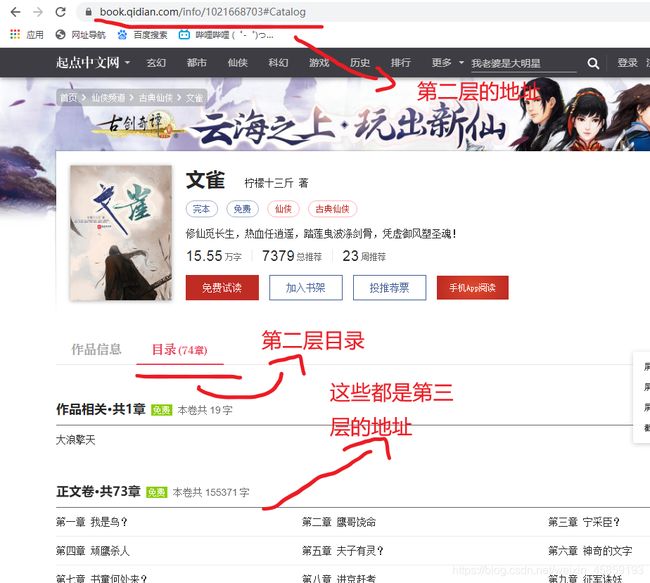
好了这是爬小说的几个步骤,明白之后就可以来写代码啦!
xpath和requests常用语法
(这次代码需要xpath和requests)
想看的直接点此链接:https://blog.csdn.net/weixin_45859193/article/details/107064009
xpath下载
xpath工具下载链接https://pan.baidu.com/s/1GXPm1kMENXhOkefKcEQnlA
提取码:8wwv
代码块
建议:如果没看懂代码的可以看看四大步骤,代码每一块也有注释
import requests
from lxml import etree
#发送请求
#第一层url地址
url='https://www.qidian.com/all?action=1&orderId=&page=1&vip=0&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0'
#模拟浏览器
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
#解析数据
data=requests.get(url,headers=headers).content.decode()
#转换数据
html=etree.HTML(data)
#第二层url地址
novel_url_list=html.xpath('//div[@class="book-img-box"]/a/@href')
for novel_url in novel_url_list:
#第二层url地址的目录
novel_url='https:'+novel_url+'#Catalog'
#解析第二层的数据
data=requests.get(novel_url,headers=headers).content.decode()
#转换第二层的数据
html = etree.HTML(data)
#小说目录
name=html.xpath('/html/body/div/div[6]/div[1]/div[2]/h1/em/text()')
#获取第三层url的地址
catalog_url_list=html.xpath('//ul[@class="cf"]/li/a/@href')
#这里来个迭代,因为你要第三层的全部文本内容
for catalog_url in catalog_url_list:
#到了第三层的地址了
catalog_url='https:'+catalog_url
#解析第三层的数据
data=requests.get(catalog_url,headers=headers).content.decode()
#转换第三层数据
html=etree.HTML(data)
#小说名
name_url=html.xpath('//h3[@class="j_chapterName"]/span[@class="content-wrap"]/text()')
#正文,join是删掉我不要的数据\u3000还有空格
text='\n'.join(html.xpath('//div[@class="read-content j_readContent"]//p//text()')).strip().replace('\u3000','')
#定义文件名
file_name =''.join(name)+'.txt'
#a+ 追加,因为不仅要写入标题,还有正文,encoding是编码
with open(file_name,'a+',encoding='utf-8')as f:
#标题写入
f.write('-------'+''.join(name_url[-1])+'-------'+'\n')
#正文写入
f.write(text+'\n\n')#换行
#打印保存是否成功
print(''.join(name_url[-1])+'---提取成功')
#提示第一本抓我了
print('抓取完成')
效果