机器学习-笔试知识点总结
1. 偏差与方差:
偏差: 度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差: 同样大小训练集的变动,导致学习性能的变化,即刻画了数据扰动对模型造成的影响
2 线性模型:
线性回归模型: lasso 和ridge 分别是l1 范数和l2范数惩罚项
线性分类模型 logistics
线性判别分析 LDA : 目的,将训练样本投影到一条直线上,使相同样本的距离尽可能的近,不同样本的距离尽可能的远。
即,优化:
3 决策树模型
决策树模型是表示基于特征对实例的划分的树形结构。可以转化为if-then的集合
算法包含三部分:特征选择、树的形成和树的剪枝
典型的算法是: ID3 利用信息熵 c4.5 信息增益比 CART 采用基尼指数
4 集成学习
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的.
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化.而权值是根据上一轮的分类结果进行调整.
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大.
3)预测函数:
Bagging:所有预测函数的权重相等.
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重.
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
boosting 模型,典型的有adaboost,采用加法模型;提升树是通过拟合残差来提高性能,主要是降低偏差
bagging 模型,典型的有RF,主要用来降低方差,及数据扰动带来的影响。
集成方法的结合策略
1. 平均法
2.投票法
3.学习法
GBDT 与XGBOOST 和LightGB 异同:
相比于GBDT,xgb的提高有一下几个方面:
1. 显示的把树模型复杂度作为正则项加到优化目标中。
2. 公式推导中用到了二阶导数,用了二阶泰勒展开。(GBDT用牛顿法貌似也是二阶信息)
3. 实现了分裂点寻找近似算法。
4. 利用了特征的稀疏性。
5. 数据事先排序并且以block形式存储,有利于并行计算。
6. 基于分布式通信框架rabit,可以运行在MPI和yarn上。(最新已经不基于rabit了)
7. 实现做了面向体系结构的优化,针对cache和内存做了性能优化。
在项目实测中使用发现,Xgboost的训练速度要远远快于传统的GBDT实现,10倍量级。
lightgbm 优化:
直方图优化,
- 在训练决策树计算切分点的增益时,预排序需要对每个样本的切分位置计算,所以时间复杂度是O(#data)而LightGBM则是计算将样本离散化为直方图后的直方图切割位置的增益即可,时间复杂度为O(#bins),时间效率上大大提高了(初始构造直方图是需要一次O(#data)的时间复杂度,不过这里只涉及到加和操作)
- LightGBM可以直接用类别特征进行训练,不必预先进行独热编码,速度会提升不少,参数设置
categorical_feature来指定数据中的类别特征列 - 并行优化
5 KNN模型
距离度量: 欧式距离 二阶lp 曼哈顿距离 一阶lp 余弦距离 等
构造 kd tree
6 .典型的聚类模型
1. kmeans 高斯聚类
2. 密度聚类
3. 层次聚类
7. 数据降维算法
1. 线性算法pca,投影到的空间方差大
2. 非线性降维,采用核技巧,kpca
3. 度量学习,学一个可以改变距离的度量矩阵
LDA 典型的监督性降维
8. 特征选择与稀疏学习
l1 和 l2 都有利于减少过拟合,但是l1更加容易获得稀疏解
既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。
字典学习、压缩感知
9. 支持向量机
函数间隔与几何间隔
拉格朗日对偶法
kkt条件
手动推倒支持向量算法
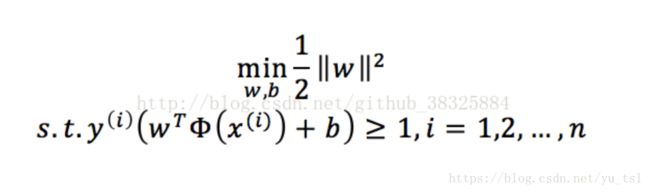
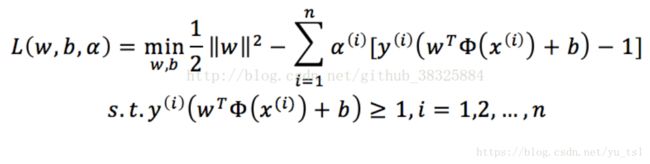

10. 概率图模型
生成模型: 隐马尔科夫模型 HMM、 马尔科夫随机场MCF
判别模型: 条件随机场CRF