中国大学排名定向爬取实例
一、功能描述
功能:中国大学排名定向排名爬取。
展示:以简单表格的形式输出大学排名结果,包括排名、大学名称、地点、总得分。
定向URL:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html。
二、源代码
#coding=utf-8
'''
Created on 2017年10月25日
@author: zxt
'''
import requests
from bs4 import BeautifulSoup
import bs4;
# 从网络上获取大学排名网页内容
def getHtmlText(url):
try:
r = requests.get(url, timeout = 30);
r.raise_for_status();
r.encoding = r.apparent_encoding;
return r.text;
except:
return "";
# 提取网页内容中信息到合适的数据结构
def fillUniversityList(ulist, html):
soup = BeautifulSoup(html, "html.parser");
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td');
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string]);
# 利用数据结构展示并输出结果
def printUniversityList(ulist, num):
# {}:表示用第几项填充
tplt = "{0:<5}\t{1:{4}^10}\t{2:{4}^10}\t{3:^5}";
print(tplt.format("排名", "学校名称", "地址", "总分", chr(12288)));
for i in range(num):
list = ulist[i];
print(tplt.format(list[0], list[1], list[2], list[3], chr(12288)));
def main():
# 获取网页源代码信息
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html";
html = getHtmlText(url);
# 通过查看网页源代码,发现大学的排名在一个table表格里面,每一个大学为一行tr
ulist = [];
fillUniversityList(ulist, html);
# 格式化输出大学排名
printUniversityList(ulist, 20);
if __name__ == "__main__":
main();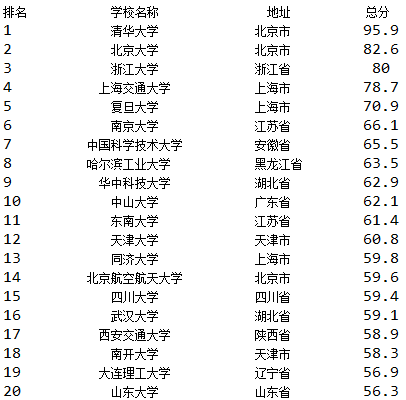
三、中文对齐


当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同,所以当输出时即有中文字符又有英文时,会出现对不齐的问题。所以当中文字符宽度不够时,采用中文字符的空格填充 chr(12288)。
四、基于bs4库的Html内容查找方法
find_all函数
<>.find_all(name, attrs,recursive, string, **kwargs)
∙ name : 对标签名称的检索字符串
∙ attrs: 对标签属性值的检索字符串,可标注属性检索
∙ recursive: 是否对子孙全部检索,默认True
∙ string: <>…中字符串区域的检索字符串
返回一个列表类型,存储查找的结果







由于find_all方法很常用所以有以下的简写方式:
soup(..) 等价于soup.find_all(..)
其他扩展方法
| 方法 |
说明 |
| <>.find() |
搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() |
在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() |
在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() |
在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() |
在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() |
在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() |
在前序平行节点中返回一个结果,同.find()参数 |