基于webMagic实现爬虫开发
最近由于毕设一定的数据源,故需要进行爬虫方面的开发,网上的爬虫框架很多,包括scrapy(基于python),PySpider(基于python),webMagic(基于Java)等等。在网上查找了一番资料后选定webMagic,一方面它可以基于Java进行爬虫的开发,更重要的还是它的学习成本很低,官方文档简单易懂(国人开发,中文文档)。作者提供了一组高效而简洁的api,使得我们能用少量的代码就能实现爬虫的开发。
什么是webMagic?

webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
作者的说法:
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
特性:
- 简单的API,可快速上手
- 模块化的结构,可轻松扩展
- 提供多线程和分布式支持
webMagic组件结构
主要有四个组件:Downloader,PageProcessor,Pipeline,Scheduler。通过Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
附官方提供的webMagic结构图:

1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
基于webMagic进行爬虫开发
本次实践案例是爬取马蜂窝的热门旅游城市及对应城市下的所有旅游景点信息
不得不说马蜂窝旅游网的UI设计还是蛮赞的,相对于其他旅游网站很清新简洁,首页的大轮播图还提供了一种强烈的视觉冲击,给人很舒服的观感。
1.爬虫开发的步骤:
- 数据爬取:实现PageProcessor(PageProcessor的定制)
- 爬虫的配置
- 页面元素的抽取
- 链接的发现
- 数据持久化:使用Pipeline保存结果(定制Pipeline)
- 保存结果到文件、数据库等一系列功能
- 数据整理(利用SQL脚本将数据进行规范整理)
2. 爬取目标信息
1. 链接发现
爬取马蜂窝旅游网热门旅游城市及该城市的介绍信息(暂定国内);
爬取该城市下的所有旅游景点详细信息;

2. 在页面打开链接:https://www.mafengwo.cn/mdd/,按f12,可以看到,每个城市对应的详情链接大致一样"/travel-scenic-spot/mafengwo/10065.html",只有在.html前面的数字串不一样,这应该是马蜂窝网内部定义的城市编号信息,用于作为不同城市的标识。
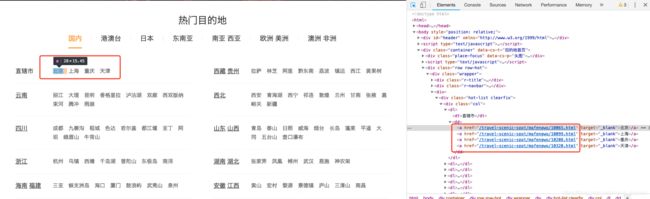
3. 点开一个北京链接的页面,可以发现本页并没有关于北京市的详细介绍,其实具体介绍在深入另一个页面,即下图 "景点",是一个新的链接“/jd/10065/gonglve.html”,同样带了一个标识城市的数字串,与上面的是一致的10065。点击进去。

4. 是的,我们要的信息找到了,城市名,城市介绍,图片等信息(该城市下的图片在本页有,不做过多截图)

5. 在上面当前页面上,会有该城市下的所有旅游景点信息,这就是我们第二部分要爬取的内容,页面链接组成是“/poi/3474.html”,跟上面同样的套路,用数字串作为该景点的标识。点击进去。
6. 看了下,大致排版相对固定,景点名,一大图两小图,景点详细介绍,这大概就是我们要爬取的数据。
7. 大概数据查找过程如上,接下来的工作便是编写爬虫逻辑。
b.编写爬虫逻辑 pageProcessor
1. 建立Java工程,由于本次开发是在毕设springboot工程的基础上进行的,故使用了一些spring相关的注解来配合其他功能的实现,但这完全不影响爬虫模块的编写,跟普通的Java工程实现是一致的。
注意引入webMagic相关包,本次以maven形式引入,版本0.7.3
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
实现方式:
- 实现pageProcessor接口
- 设置爬取站点信息
- 实现process方法(爬取热门城市页,热门城市链接,该城市下所有景点信息)
核心process逻辑大致如下:
- 匹配城市列表页(即a-1步骤那个图),则执行doCityListProcess(Page page)方法
- 匹配城市页(即a-4步骤那个图),则执行doCityProcess(Page page)方法
- 匹配景点页(即a-5步骤那个图),则执行doScenicProcess(Page page)方法
/**
* 爬取数据PageProcessor (城市列表,各城市下的所有景点)
*
* @author [email protected]
* 2019-02-19 15:05
* @version 1.0.0
*/
@Component
@Slf4j
public class PenguinPageProcessor implements PageProcessor {
private Site site = Site
.me()
.setDomain(SpiderConstant.DOMAIN)
.setSleepTime(SpiderConstant.SPIDER_SLEEP_TIME)
.setUserAgent(SpiderConstant.BROWSER_USER_AGENT);
@Override
public void process(Page page) {
try {
if (page.getUrl().regex(SpiderConstant.URL_CITY_LIST).match()) {
this.doCityListProcess(page);
}
if (page.getUrl().regex(SpiderConstant.URL_CITY).match()) {
this.doCityProcess(page);
}
if (page.getUrl().regex(SpiderConstant.URL_SCENIC).match()) {
this.doScenicProcess(page);
}
} catch (Exception e) {
log.info("【爬虫爬取数据异常】");
e.printStackTrace();
}
}
@Override
public Site getSite() {
return site;
}
2.爬取当前所有城市名(图a-1)
借用xpath解析器和强大的正则匹配,对页面需要抽取的信息进行提取,并在新发现链接后通过page.addTargetRequests(List list);将新链接加入到待爬取的目标链接中去(存储所有爬取链接的是List结构,FIFO)
private void doCityListProcess(Page page) throws Exception{
Thread.sleep(SpiderConstant.SPIDER_SLEEP_TIME);
List cityListPageRequest = page.getHtml()
.xpath("div[@class=\"hot-list clearfix\"]")
.links().regex("\\d+").all();
List citysPageRequest = cityListPageRequest.stream()
.map(url -> "/jd/" + url + "/gonglve.html")
.distinct()
.collect(Collectors.toList());
page.addTargetRequests(citysPageRequest);
log.info("【爬取城市列表链接信息】: {}", citysPageRequest);
} 3.爬取当前城市的详情信息(图a-4)
这里的逻辑相对上面多一点,主要是除了爬取当前城市信息外,还要爬取当前城市下的所有景点链接
private void doCityProcess(Page page) throws Exception{
Thread.sleep(SpiderConstant.SPIDER_SLEEP_TIME);
page.putField("pageType", SpiderEnum.CITY_PAGE.getCode());
page.putField("cityName", page.getHtml()
.xpath("//div[@class='crumb']//div[@class='drop']//span[@class='hd']//a//text()")
.all()
.get(SpiderConstant.CITY_INDEX));
page.putField("introduce", page.getHtml()
.xpath("//div[@class='wrapper']//span[@id='mdd_poi_desc']//text()"));
if (page.getResultItems().get("introduce") == null) {
page.setSkip(true);
}
page.putField("cityPic", page.getHtml()
.xpath("//div[@class='large']//img/@src")
.all());
page.putField("headRate", page.getHtml()
.xpath("//span[@class='rev-total']//em/text()")
.all());
List scenicListUrls = page.getHtml()
.xpath("//div[@class='wrapper']")
.links()
.regex("/poi/\\d+\\.html").all();
page.addTargetRequests(scenicListUrls
.stream()
.distinct()
.collect(Collectors.toList()));
log.info("【爬取城市详情信息】: {}", page.getResultItems());
} 4.爬取景点的详细信息(图a-6)
private void doScenicProcess(Page page) throws Exception{
Thread.sleep(SpiderConstant.SPIDER_SLEEP_TIME);
page.putField("pageType", SpiderEnum.SCENIC_PAGE.getCode());
page.putField("cityName", page.getHtml()
.xpath("//div[@class='crumb']//div[@class='drop']//span[@class='hd']//a//text()")
.all()
.get(SpiderConstant.SCENIC_CITY_INDEX));
page.putField("scenicName", page.getHtml()
.xpath("//div[@class='title']//h1/text()"));
page.putField("scenicPic", page.getHtml()
.xpath("//div[@class='bd']//img/@src")
.all());
page.putField("introduce", page.getHtml()
.xpath("//div[@class='summary']/text()"));
page.putField("headRate", page.getHtml()
.xpath("//li[@data-scroll='commentlist']//span/text()")
.regex("\\d+"));
log.info("【爬取景点详情信息】: {}", page.getResultItems());
}5.注意点
可能你也注意到了,在每个爬取方法开始前都会执行 Thread.sleep(SpiderConstant.SPIDER_SLEEP_TIME); 这是统一设置的爬取时间间隔,非常必要(有钱租代理IP池的请忽略),要是对爬取速度不加以限制,对方的反爬机制就会认定你是爬虫而不是人(没有一个人(IP)能够在一个或几个页面一秒内点好几百次以上吧。。。),对方的反爬机制会将你当前的ip拉黑导致你无法访问和爬取数据。
c. 数据持久化 Pipeline
1. 在爬取完数据后,要对数据进行持久化操作,存储到本地数据库中(不然你爬它干嘛==)
- 实现Pipeline接口
- 实现process方法获取结果集resultItems
- 调用服务进行持久化(可以是原生实现也可以结合框架实现)
看下来其实跟pageProcessor的步骤差不多。
这里通过一个pageType标识来区分不同信息(城市信息,景点信息)的保存
/**
* 爬虫数据持久化服务Pipeline
*
* @author [email protected]
* 2019-02-19 15:07
* @version 1.0.0
*/
@Component
@Slf4j
public class PenguinPipeline implements Pipeline {
private PipelineService pipelineService = (PipelineService) SpringUtil.getBean(PipelineService.class);
@Override
public void process(ResultItems resultItems, Task task) {
Map mapResults = resultItems.getAll();
Iterator> iter = mapResults.entrySet().iterator();
Map.Entry entry;
System.out.println("======================PenguinPipeline started!======================");
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
if (mapResults != null && mapResults.size() != SpiderConstant.ZERO) {
if (mapResults.get("pageType").equals(SpiderEnum.CITY_PAGE.getCode())) {
this.doCityPipeline(mapResults);
}
if (mapResults.get("pageType").equals(SpiderEnum.SCENIC_PAGE.getCode())) {
this.doScenicPipeline(mapResults);
}
}
System.out.println("======================PenguinPipeline ended!======================");
} 2.城市信息持久化 doCityPipeline
这里涉及了城市热度(欢迎程度,假定以城市所有景点的评论总量)的计算(业务逻辑需要,可忽略~)。
private void doCityPipeline(Map mapResults) {
City city = new City();
String headRatesStr = Arrays.asList(mapResults.get("headRate")).get(SpiderConstant.ZERO).toString();
city.builder()
.cityName(Optional.ofNullable(mapResults.get("cityName")).orElse("").toString())
.introduce(Optional.ofNullable(mapResults.get("introduce")).orElse("").toString())
.cityPic(Optional.ofNullable(mapResults.get("cityPic")).orElse("").toString())
.headRate((int)Arrays.stream(headRatesStr.substring(1, headRatesStr.length() - 1)
.split(","))
.mapToDouble(eachHeadRate -> Double.parseDouble(eachHeadRate))
.sum())
.status(SpiderEnum.NORMAL_STATUS.getCode())
.build();
if (city != null) {
if (city.getIntroduce() != null) {
city.setCityPic(Optional.ofNullable(city.getCityPic()).orElse(SpiderConstant.NULL_PIC)
.substring(1, city.getCityPic().length() - 1));
pipelineService.insertIntoCity(city);
log.info("【城市信息持久化】: {}",city);
}
}
} 3.景点信息持久化
private void doScenicPipeline(Map mapResults) {
Scenic scenic = new Scenic();
scenic.setCityId(
pipelineService.selectCityIdByCityName(
Optional.ofNullable(mapResults.get("cityName"))
.orElse(SpiderConstant.NO_BELONG_CITY)
.toString()));
String scenicPicStr = Optional.ofNullable(mapResults.get("scenicPic")).orElse(SpiderConstant.NULL_PIC).toString();
scenic.builder()
.scenicName(Optional.ofNullable(mapResults.get("scenicName")).orElse("").toString())
.scenicPic(scenicPicStr.substring(1, scenicPicStr.length() - 1))
.introduce(Optional.ofNullable(mapResults.get("introduce")).orElse("").toString())
.headRate(Integer.parseInt(
Optional.ofNullable(mapResults.get("headRate"))
.orElse(SpiderConstant.ZERO)
.toString()))
.status(new Byte(SpiderConstant.ZERO.toString()))
.build();
pipelineService.insertIntoScenic(scenic);
log.info("【景点信息持久化】: {}",scenic);
} d. 爬虫启动
1.本次开发是在毕设springboot工程的基础上,故还是采用了springMVC的方式来进行爬虫的启动。在项目启动后通过postman发起请求进行触发。数据持久化服务这里通过spring bean的方式提供,若采用普通Java类进行爬虫的启动,会导致服务无法初始化,调用抛出空指针异常,故需要通过springUtils辅助我们进行服务的初始化(这方面资料网上很多,当然这是题外话了~)
/**
* 爬虫启动
*
* @author [email protected]
* 2019-02-20 15:16
* @version 1.0.0
*/
@RestController
@RequestMapping("/spider")
public class SpiderController {
private static final String SPIDER_URL = "https://www.mafengwo.cn/mdd/";
@RequestMapping("/start")
public void spiderStart() {
Spider.create(new PenguinPageProcessor())
.addUrl(SPIDER_URL)
.addPipeline(new PenguinPipeline())
.run();
}
}2. 爬虫的启动很简单,通过Spider提供的静态方法create(),指定PenguinPageProcessor和PenguinPipeline即可,这里也可以采用多线程启动加快爬取速度(当然这里担心IP被拉黑并没有这么做)
e. 爬取结果
本次共爬取了5000+条数据

f. 数据清洗
在我们对爬虫数据进行数据库存储后,可能有些信息并不合我们所预想的,这时就需要通过SQL脚本来对数据进行一定的整理。
本次数据遇到的问题有:
1.城市id与我数据库字典表中定义的不一致(这是肯定的,不同人有不同自定义的值,当然也有几个大致的版本,网上省市区县mysql数据源)
2.城市所在省份信息没有填充到城市表
update city set province=#{province} where city_id=#{cityId}
update city set city_id=#{cityId} where id=#{id}
具体情况要靠业务结合去编写,此处不过多赘述。
/**
* 数据信息修复服务
*
* @author [email protected]
* 2019-02-21 14:56
* @version 1.0.0
*/
@Service
public class DataServiceImpl implements DataService {
@Autowired
private DictionaryMapper dictionaryMapper;
@Autowired
private CityMapper cityMapper;
@Override
public void updateProvinceByCityName() {
List cities = cityMapper.selectAll();
cities.stream().forEach(city -> {
cityMapper.updateProvinceByCityId(city.getCityId(),
dictionaryMapper.selectProvinceBycityName(city.getCityName()));
});
System.out.println("======Run finished=====");
}
@Override
public void updateCityIdByCityName() {
List cities = cityMapper.selectAll();
cities.stream().forEach(city -> {
cityMapper.updateCityIdById(city.getId(),
dictionaryMapper.selectCityIdByCityName(city.getCityName()));
});
}
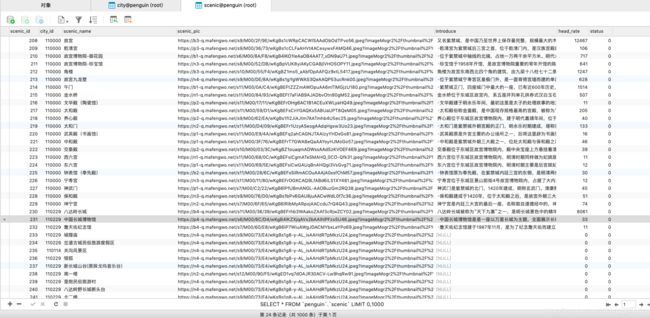
} g. 结果集
1.城市表:

2.景点表:
h. 附webMagic官方文档:
http://webmagic.io/
官方教程,还是很有必要看一下的~