Python数据科学:技术详解与商业实战(第三章至第五章学习笔记)
文章目录
- 第二章 Python 的基本运算
- 2.1 算术运算
- 2.2 比较运算
- 2.3 逻辑运算
- 第3章 数据科学的Python编程基础
- 序列
- 序列相关操作
- 3.1 Python 的基本数据类型
- 3.1.1 字符串(str)
- 3.1.2 布尔值(Bool: True/False)
- 3.1.3 浮点型
- 3.1.4 复数型
- 3.1.5 特殊的数据类型
- 3.2 Python 的基本数据结构
- 3.2.1 列表(list)
- 列表方法
- 列表解析
- 3.2.2 元组(tuple)
- 创建元组
- 元素不可修改性
- 元组的加法运算
- 访问元素
- 3.2.3 集合(set)
- 创建集合
- 集合运算
- 3.2.4 字典(dict)
- 3.2.4.1 创建字典
- 3.2.4.2 基础操作
- 3.2.4.3 注意事项
- 3.3 Python 的程序控制
- 3.3.4 循环结构
- 3.3.4.1 for 循环
- 3.3.4.2 while 循环
- 循环中的break、continue语句
- 3.3.4.3 表达式
- 3.3.5 选择结构
- if 语句
- else 语句
- elif 语句
- 条件嵌套
- 3.4 Python 的函数与模块
- 3.4.1 Python 的函数
- 1. 自定义函数
- 自定义函数的调用
- 2. lambda 函数
- 3.4.2 Python 的模块
- 3.4.3 Python 的包
- 3.5 Pandas 读取结构化数据
- 3.5.1 读取数据
- 第四章 描述性统计分析与绘图
- 4.1 描述性统计进行数据探索
- 4.1.3 连续变量的分布与集中
- 4.1.4 连续变量的离散程度
- 4.1.5 数据分布的对称与高矮
- 4.2 制作报表与统计制图
- 第五章 数据整合和数据清洗
- 5.1 数据整合
- 5.1.1 行列操作
- 5.1.2 条件查询
- 5.1.3 横向连接
- 5.1.4 纵向合并
- 5.1.5 排序
- 5.1.6 分组汇总
- 5.1.7 拆分、堆叠列
- 5.18 赋值与条件复制
- 5.2 数据清洗
- 5.2.1 重复值处理
- 5.2.2 缺失值处理
- 5.2.3 噪声值处理
- 5.3 RFM方法在客户行为分析上的运用
- 5.3.1 行为特征提取的RFM方法论
- 5.3.2 使用RFM方法计算变量
- 5.3.3 数据整理与汇报
- 参考资料
第二章 Python 的基本运算
2.1 算术运算
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| ** | 乘方 | 正负号 | +、- |
| 乘除 | *、/ | 整除 | / |
| 取余 | % | 加减 | +、- |
2.2 比较运算
-
数值型:按照值进行比较
-
字符型:按照 ASCII 码进行比较
比较运算符说明表 符号 含义 符号 含义 <、> 小于、大于 <=、>= 小于等于、大于等于 == 比较等于或者逻辑等于 != 不等于

#数值型
3 < 4 < 7
4 > 1 == 1
4 != 3
8 > 10
2 <= 5
输出结果
True
True
True
False
True
#字符型
'A' < 'a'
'ab' > 'cd'
'abc' == 'abc'
输出结果
True
False
True
2.3 逻辑运算
逻辑运算符优先级:not(取反)、and(并且)、or(或者)
x,y = 2,8
x < 6
Out[184]: True
#not
not(x < 6)
Out[185]: False
x is y
Out[186]: False
not(x is y)
Out[187]: True
#and
(x < 6) and (y > 10)
Out[189]: False
#or
(x < 6) or (y > 10)
Out[188]: True
比较运算和逻辑运算的结果都是布尔型的值。
四则运算小练习
从键盘输入两个整数,求这个两个整数的和、差、积、商(尝试用一般除法和整除两种方式)并输出。
提示:注意input()函数的返回类型。
#参考答案
x = int(input("input x : "))
y = int(input("input y : "))
print("x+y=",x + y)#加法运算
print("x-y=",x - y)#减法运算
print("x*y=",x * y)#乘法运算
print("x/y=",x / y)#除法运算
print("x//y=",x // y)#整除运算
运算结果
input x : 9
input y : 2
x+y= 11
x-y= 7
x*y= 18
x/y= 4.5
x//y= 4
第3章 数据科学的Python编程基础
序列
Python 中有6种序列,其中字符串、元组和列表是最常用的形式,序列中每个元素都有一个跟位置相关的序号,也称为索引,对一个有 N 个元素的序列来说,第一个元素的索引从 0 开始,最后一个元素的索引就是 N-1 ,也可以从最后一个元素开始计数,最后一个元素的索引就是 -1 ,第一个元素的索引就是 -N。
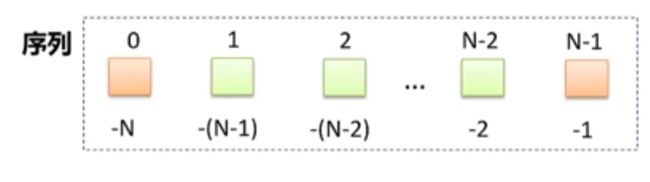
序列相关操作
-
标准类型运算符
- 值比较
- 对象身份比较
- 布尔运算(逻辑运算)
-
序列类型运算符
- 获取
- 重复
- 连接
- 判断
-
内建函数
- 序列类型转换内建函数
- 序列类型可用内建函数
标准类型运算符

序列类型运算符

week = ['Monday','Tuesday','Wednesday','Thursday','Friday']
#列表逆序:week[::-1]
print(week[0],week[-5],'\n',week[4],week[-1],'\n',week[0:4],week[:4],'\n', week[::-1])
'ba'*3 #内容重复
'Hello' + ' Python' #连接
'BA' in ('BAT') #判断
输出结果
Monday Monday
Friday Friday
['Monday', 'Tuesday', 'Wednesday', 'Thursday'] ['Monday', 'Tuesday', 'Wednesday', 'Thursday']
['Friday', 'Thursday', 'Wednesday', 'Tuesday', 'Monday']
Out[568]: 'bababa'
Out[569]: 'Hello Python'
Out[570]: True
序列类型转换内建函数
| list() |
|---|
| str() |
| tuple() |
tuple('apple')
list('apple')
序列类型其他常用内建函数
| 函数 | 含义 | 函数 | 含义 |
|---|---|---|---|
| len() | 长度 | sorted() | 排序 |
| max() | 最大值 | min() | 最小值 |
| sum() | 求和 | reversed() | 逆序 |
| enumerate() | zip() |
enumerate() 函数,返回的是一个 enumerate 对象,它的元素是由元素的索引和值构成的一个一个的元组,在又要遍历索引又要遍历元素的时候使用非常方便,zip() 函数由一系列可迭代的对象作为参数,返回一个 zip 对象,它把对象对应的元素打包成一个一个的元组。
还有另一个常用的序列 range() 对象。
range函数
rang()函数可以产生一组有规律的数据,
语法规则
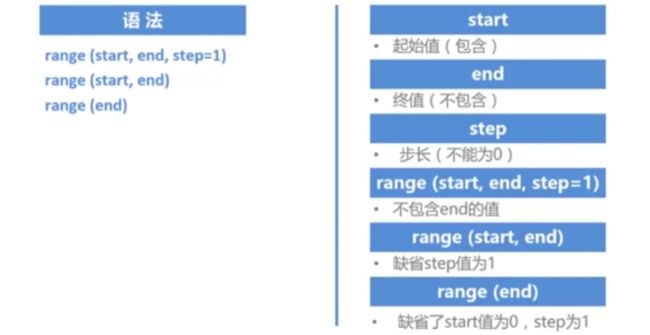
- range(start,end,step=1) 三个参数:第一个参数表示起始值,默认值是0,第二个参数代表终止值,这个值是不包含在内的,第三个参数是步长,默认值是1。
- range(start,end) 两个参数:默认步长为1,只设置起始值和终止值。
- range(end) 一个参数:默认起始值为0,步长为1,只设置终止值
产生一系列整数,返回值是一个range对象,也是Python中的一种内建序列,range对象是可迭代的。
#range()函数
list(range(5,26,5))#三个参数
list(range(5,10))#两个参数
list(range(5))#一个参数
输出结果
Out[240]: [5, 10, 15, 20, 25]
Out[241]: [5, 6, 7, 8, 9]
Out[242]: [0, 1, 2, 3, 4]
规律:假设步长为1的情况,产生值的个数等于参数值的差。比如上面的例子中range(5,10),步长为1,最终可以产生10-5=5个值。
Python 3中的range()函数跟Python 2当中的xrange()函数比较类似,函数返回结果是一个range对象,类似一个生成器generator,生成器利用惰性计算的机制,也就是说它不会一次性的产生所有的数,而是每计算出一个条目以后,把这个条目产生出来,也就是用多少生成多少,类似一个lazy list。range()函数在循环中使用非常多,特别适合和for语句联用。

Python 的基本数据类型包括几种,如下所示

3.1 Python 的基本数据类型
3.1.1 字符串(str)
单引号、双引号、三引号包围的都是字符串
'apple'
"example"
'''instance'''
换行符
print('The first row \nThe second row')
输出结果
The first row
The second row
制表符
#制表符
print('123\t456')
原始字符串操作符(r/R): 用于一些不希望转义字符起作用的地方
#加r原始输出
print(r'You can choose a/b/c')
print(r'C:\Some\name')
输出结果
You can choose a/b/c
C:\Some\name
转义字符
如果我们不使用原始字符串操作符,我们可以使用转义字符使得路径中的反斜杠原始输出。也就是在字符串里面,如果你想要表示一个反斜杠的话,你需要两个反斜杠表示。
py = open('G:\Pythoncode\test.py','w') #出现错误
Traceback (most recent call last):
File "" , line 1, in <module>
py = open('G:\Pythoncode\test.py','w')
OSError: [Errno 22] Invalid argument: 'G:\\Pythoncode\test.py'
py = open('G:\\Pythoncode\\test.py','w')#转移字符“\”
#或者
py = open(R'G:\Pythoncode\test.py','w')#加上原始字符串操作符r或者R
这里简单说一下:open()用来打开一个文件,文件的路径就是它的第一个参数,而 w 就是写文件。上面的语句的功能就是在G盘的Pythoncode目录下新建一个text.py文件。
字符串的加法
'I love '+'Python'
使用索引访问元素
introduce = "Please speak English"
introduce[0:6]
introduce[-1]
输出结果
'Please'
'h'
注意:字符串是不可变类型
introduce[0] = 'PP'
TypeError: 'str' object does not support item assignment
3.1.2 布尔值(Bool: True/False)
Python布尔值一般通过逻辑判断产生,只有两个可能结果,True或者False
'a' is 'A'
Out[18]: False
'a' is 'a'
Out[19]: True
1==1
Out[20]: True
True and False
Out[21]: False
True or False
Out[22]: True
not False
Out[23]: True
布尔值转换可以使用内置函数bool,除数字0外,其他类型用bool转换结果都为True
bool(1)
Out[24]: True
bool(0)
Out[25]: False
bool(10000)
Out[26]: True
bool('a')
Out[27]: True
布尔型变量本质上是用整型的1、0分布存储的。
x = True
y = False
int(x)
Out[143]: 1
int(y)
Out[144]: 0
3.1.3 浮点型
即数学中的实数,可以类似科学计数法表示,如下面例子中 e3 代表的是 10 的 3 次方。
9.8e3
Out[145]: 9800.0
floatdata = -4.78e-2
type(floatdata)
Out[146]: float
3.1.4 复数型
-
实数+虚数 就是复数,当然复数也可以没有实部,例如 3j;虚部也可以为0,例如 6+0j。
-
虚数部分用标记符 j 表示
-
复数型就是 complex
#复数型
5.3+4.6j#实数+虚数
3j#没有实部
type(3j)#类型为complex
Out[150]: complex
9+0j#虚部为0
type(9+0j)
Out[151]: complex
复数还可以对它的实数部分和虚数部分进行分离。
-
实部:复数.real
-
虚部:复数.imag
-
共轭复数:复数.conjugate()
#分离实部和虚部 a = 5.2+6.3j a.real#实部 Out[153]: 5.2 a.imag#虚部 Out[154]: 6.3 a.conjugate()#共轭复数 Out[155]: (5.2-6.3j)
3.1.5 特殊的数据类型
Python中,还有一些特殊的数据类型,例如无穷值、nan(非数值)、None等。
注意,正负无穷相加返回nan(not a number),表示非数值。
#创建负无穷
float('-inf')
#创建正无穷
float('+inf')
float('-inf')+1000000
float('-inf')+float('+inf')
3.2 Python 的基本数据结构
3.2.1 列表(list)
- 创建列表
列表 list 是 Python 内置的一种数据类型,是一种有序的集合,用来存储一连串元素的容器,列表用 [ ] 来表示,其中元素的数据类型可不相同。除了使用 [ ] ,还可以使用list()函数。
list_1 = [1,2,'a',True,3.2]
list_1
list('abcde')
list([1,2,'a','b'])
#包含多个元组的列表
Plist = [('axp','American','80.6'),
('BA','The company','89.1'),
('cat','System','33.7')]
Plist
输出结果
[1, 2, 'a', True, 3.2]
['a', 'b', 'c', 'd', 'e']
[1, 2, 'a', 'b']
[('axp', 'American', '80.6'),
('BA', 'The company', '89.1'),
('cat', 'System', '33.7')]
- 通过索引对访问或修改列表的元素
使用索引时,通过 [ ] 来指定位置。在Python中,索引的起始点位置为0。
list_1 = [1,2,'a',True,3.2]
list_1[0]
输出结果
Out[40]: 1
可以通过 :符号选取指定序列位置的元素,例如选取第1个到第4个位置的元素,注意这种索引取数是前包后不包(包括0位置,但不包括4位置,即取0,1,2,3位置的元素)
list_1[0:4]#取0,1,2,3位置的元素
Python中的负索引表示倒序位置,例如-1表示列表最后一个位置的元素
list_1[-1]#访问最后一个位置的元素
列表支持加法运算,表示两个或多个列表合并为一个列表
list('abc')+list('de')
Python中,列表对象内置了一些方法,append方法表示在现有列表中添加一个元素。
mylist = ['a','b','c']
mylist.append('d')
mylist
输出结果
['a', 'b', 'c', 'd']
extend方法类似列表加法运算,表示将两个列表合并为一个列表。
mylist.extend(list('ABCD'))
mylist
输出结果
['a', 'b', 'c', 'd', 'A', 'B', 'C', 'D']
某学校组织一场校园歌手比赛,每个歌手的得分由10名评委和观众决定,最终得分的规则是去掉10名评委所打分数的一个最高分和一个最低分,再加上所有观众评委分数后的平均值。
评委打出的10个分数为:9、9、8.5、10、7、8、8、9、8和10,观众评委打出的综合评分为9,请计算该歌手的最终得分。
jScores = [9,9,8.5,10,7,8,8,9,8,10]#10名评委的打分
aScore = 9 #观众打分
#对评委的十个分数进行排序
#列表的sort()方法
jScores.sort()#若使用sorted(jScores),则需要赋值新的变量
# x = sorted(jScores)
jScores.pop()#去掉一个最高分:10
jScores.pop(0)#去掉一个最低分:7
jScores.append(aScore)#加上观众得分:9
jScores
aveScore = sum(jScores)/len(jScores)#最终得分
print(aveScore)
对评委的十个分数进行排序,使用列表的 sort() 方法。如果用sorted()函数这样的写法,其实 jScores 里面的内容并不会改变,除非我们把他们的结果赋给另外一个变量才可以;现在要去掉一个最高分和最低分,在列表当中,我们可以通过列表的 pop() 方法弹出最后一个值,或者加上参数,就是它的索引,弹出最低的值;再通过append() 把aScore 这个分数加到原始的 jScore 这个列表当中,最后通过 sum() 函数和 len() 计算它们的平均值,这就是最终的得分。
输出结果
#排序后
Out[517]: [7, 8, 8, 8, 8.5, 9, 9, 9, 10, 10]
#去掉一个最高分
Out[519]: [7, 8, 8, 8, 8.5, 9, 9, 9, 10]
#去掉一个最低分
Out[521]: [8, 8, 8, 8.5, 9, 9, 9, 10]
#加上观众得分
Out[523]: [8, 8, 8, 8.5, 9, 9, 9, 10, 9]
#最终得分
8.722222222222221
将工作日([‘Monday’,‘Tuesday’,‘Wednesday’,‘Thursday’,‘Friday’])和周末([‘Saturday’,‘Sunday’])的表示形式合并,并将它们用序号标出并分行显示。
对于一个机要遍历索引,又要遍历元素本身的一个功能,我们可以用 enumerate() 这样的一个函数,因为最后要输出序号1到7,默认是0到6,因此我们把 i 增加 1。
week = ['Monday','Tuesday','Wednesday','Thursday','Friday']
weekend = ['Saturday','Sunday']
#合并两个部分内容的列表合并
week.extend(weekend)
week
#append()
#week.append(weekend)
#week
for i,j in enumerate(week):
print(i+1,j)
输出结果
Out[535]: ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
1 Monday
2 Tuesday
3 Wednesday
4 Thursday
5 Friday
6 Saturday
7 Sunday
注意:week 列表和 weekend 列表的合并,这边不要使用 append(),否则它的合并结果为:
Out[530]:
[‘Monday’,
‘Tuesday’,
‘Wednesday’,
‘Thursday’,
‘Friday’,
‘Saturday’,
‘Sunday’,
[‘Saturday’, ‘Sunday’]]
前面是week列表的元素,后面是一个列表,里面是’Saturday’和 ‘Sunday’。
列表方法
| append() | copy() | count() | extend() | insert() |
|---|---|---|---|---|
| pop() | remove() | reverse() | index() | sort() |
使用列表函数的方法可以非常高效地解决一些问题,当然在用的时候要注意它们之间的区别,比如 sort() 和sorted() 、reverse() 和 reversed() 。我们在使用的时候,还要注意方法或者函数的参数,有时候参数的使用,也可以让问题解决变得更加高效。
参数的作用
list.sort(key=None,reverse=False)
比如我们要逆序去排一个列表,这个时候就需要使用 reverse() 这样的一个参数,把它置为 True 即可。又比如我们要按照长度对列表中的元素进行排序,我们就把 key 设为 len,这样的一个函数名即可。
numlist = [3,11,5,8,16]
fruitlist = ['apple','banana','pear','lemon','avocado']
#逆序
numlist.sort(reverse=True)
numlist
#key参数为len
fruitlist.sort(key=len)
fruitlist
输出结果
Out[539]: [16, 11, 8, 5, 3]
Out[540]: ['pear', 'apple', 'lemon', 'banana', 'avocado']
列表解析
一般什么时候用到列表解析呢?一般在需要改变列表,而不是需要新建某个列表的时候可以使用它。
列表解析的基本语法规则是由多个 for 循环以及可迭代的序列构成,另外也可以加条件,其中条件是可选的。它主要有两种语法:

- 第一种是不带 if 条件,首先迭代 sequence 里面的所有的内容,每一次迭代都把 sequence 里面的内容放到前面的对象里面去,然后再在表达式里面应用这样的一个对象,形成一个列表;
- 第二种语法是加入判断语句,只有满足条件的内容,才把 sequence 里面的相应内容放到 expression 这个对象里面去,再在表达式里面应用这样的一个对象,形成一个列表。
[x for x in range(10)]#可迭代的range(10)
[x**2 for x in range(10)]
[x**2 for x in range(10) if x**2<50]
[(x+1,y+1) for x in range(2) for y in range(2)]
输出结果
Out[541]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Out[542]: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Out[543]: [0, 1, 4, 9, 16, 25, 36, 49]
Out[544]: [(1, 1), (1, 2), (2, 1), (2, 2)]
我们也可以通过圆括号来创建生成器表达式,注意:生成器表达式并不是创建一个列表,而是返回一个生成器,这个生成器在每次计算出一个条目以后,才把这个条目产生出来,所以在大数据量处理的时候有优势
>>> sum(x for x in range(10))
45
3.2.2 元组(tuple)
创建元组
通过()创建元组
tuple_0 = (1,2,3)
tuple_0
输出结果
(1, 2, 3)
创建只有一个元素的元组,可以在元素后面加上一个逗号
2014,
Out[547]: (2014,)
计算元组的长度
bTuple = (['Monday',1],2,6,['Sunday',6])
len(bTuple)
输出结果为4。
元素不可修改性
元组与列表类似,区别在于列表中,任意元素可以通过索引进行修改。而元组中,元素不可更改,只能读取。
列表可以进行复制,而同样的操作应用于元组则报错。
#列表元素可以改变
list_0 = [1,2,3]
list_0[0] = 'a'
list_0[0]
输出结果
'a'
#元组元素不可以改变
tuple_0 = (1,2,3)
tuple_0[0] = 'a'
输出结果
TypeError: 'tuple' object does not support item assignment
会产生异常,异常的原因显示元组对象不支持元素赋值,这就说明了列表可变,而元组不可变。
在Python中,元组类对象一旦定义,就不能修改。
元组的加法运算
元组中支持加法运算,即合并元组。
(2,3,4)+(5,6,7)
输出结果
(2, 3, 4, 5, 6, 7)
访问元素
元组也可以像列表一样通过索引访问元素
tuple_3[0]
tuple_3[0:4]
输出结果
2
(2, 3, 4, 5)
获取二级元素的值
bTuple = (['Monday',1],2,6,['Sunday',6])
bTuple[0][0]
bTuple[1:]
输出结果
Out[549]: 'Monday'
Out[550]: (2, 6, ['Sunday', 6])
函数的适用类型
我们可以利用 sorted() 函数对列表进行排序(这个方法只是新生成一个列表的副本,原始的列表内容没有改变),我们也可以通过列表的 sort() 方法对列表进行排序,这个排序就是对原始列表的真正的排序,列表内容会改变。
在元组中,sorted() 函数可以使用,因为元组也是一种序列,而 sort() 方法因为要对对象进行修改,因为原创元组并不能使用 sort() 方法。
#列表
alist = [5,4,8,7,2]
sorted(alist)
alist
alist.sort()
alist
输出结果
Out[554]: [2, 4, 5, 7, 8]
Out[555]: [5, 4, 8, 7, 2]
Out[556]: [2, 4, 5, 7, 8]
#元组
aTuple = (5,4,8,7,2)
sorted(aTuple)
aTuple
aTuple.sort()
输出结果
Out[558]: [2, 4, 5, 7, 8]
Out[559]: (5, 4, 8, 7, 2)
Traceback (most recent call last):
File "" , line 1, in <module>
aTuple.sort()
AttributeError: 'tuple' object has no attribute 'sort'
aTuple.sort() 会产生异常,异常的原因是元组对象并没有 sort() 方法,它的原因就是因为它不可变
元组的作用

可变长的函数参数
def foo(args1,*args2):
print(args1)
print(args2)
#调用foo函数
foo('Hello','G','U','E','T')
这里的实参是五个字符串,第一个字符串"hello"是一个位置参数,传给 args1 ,后面的四个字符串就传给了 args2,可以发现这里的 * 有收集参数的作用。
输出结果
Hello
('G', 'U', 'E', 'T')
从输出结果我们可以看到,Python 中多个元素可以构成一个元素作为函数的参数,而元组的个数是不定长的,所以这就是可变长的函数参数。
元组作为函数特殊返回类型
def fun1():
return 1,2,3
fun1()
输出结果
Out[566]: (1, 2, 3)
调用之后,可以发现返回值有3个值时程序以一个元组的结果来呈现,Python 这样的做法让主调函数和被调函数之间数据的交互功能变得更加强大、灵活和方便,但是又跟原来的程序设计语言返回对象只有一个或者是0个这样的一种传统的方法保持一致。
| 返回对象的个数 | 返回类型 |
|---|---|
| 0 | None |
| 1 | object |
| >1 | tuple |
3.2.3 集合(set)
创建集合
Python中,集合是一组key的集合,其中key是不能重复。可以通过列表、字典或字符串等创建集合,或者通过{}符号进行创建。集合主要有两个功能,一个功能是进行集合操作,另一个功能是消除重复元素。
basket = {'apple', 'orange', 'pear'}
basket
输出结果
{'apple', 'orange', 'pear'}
集合运算
Python支持数学意义上的集合运算。
A = {1,2,3}
B = {3,4,5}
#A、B的差集,即集合A的元素去除AB共有的元素
A-B
#A、B的交集,即集合A与集合B的全部唯一元素
A|B
#A、B的交集,即集合A和集合B的共同元素
A&B
#A、B的对称差,即集合A与集合B的全部唯一值
A^B
输出结果
Out[69]: {1, 2}
Out[70]: {1, 2, 3, 4, 5}
Out[71]: {3}
Out[72]: {1, 2, 4, 5}
注意:集合不支持通过索引访问指定元素
3.2.4 字典(dict)
Python内置字典,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度,其格式是用大括号{}括起来key和value用冒号:进行对应。
3.2.4.1 创建字典
dict_1 = {'a':100,'b':99,'c':98}
dict_1
字典本身是无序的,可以通过方法keys和values取字典键值对应中的键和值。items可以把字典中每对键和值组成一个元组,然后把他们放到一个列表当中返回。
dict_1.keys()#所有的键
dict_1.values()#所有的值
dict_1.items()#字典的所有的键的值
#遍历字典的所有的键的值
for k,v in dict_1.items():
print(k,v)
输出结果
Out[75]: dict_keys(['a', 'b', 'c'])
Out[76]: dict_values([100, 99, 98])
Out[77]: dict_items([('a', 100), ('b', 99), ('c', 98)])
Out[78]:
a 100
b 99
c 98
3.2.4.2 基础操作
#键值查找
dict_1['a']
#更新
dict_1['a'] = 99.5
#添加
dict_1['d'] = 97
#成员判断
'd' in dict_1
#删除字典成员
del dict_1['d']
字典的内建函数
#dict()
names = ['aa','bb','cc','dd']
salaries = [5000,5001,5002,5003]
alnfo = dict(zip(names,salaries))#创建字典
alnfo
#len()
len(alnfo)#计算字典元素的个数
字典方法
人事部门有两份人员和工资信息表,第一份是原有信息,第二份是公司中有工资更改人员和新进人员的信息,获得完整的信息表。
alnfo = {'W':3000,'N':2000,'L':4500}
blnfo = {'W':4000,'N':9999,'K':6000}
alnfo.update(blnfo)
alnfo
输出结果
Out[497]: {'K': 6000, 'L': 4500, 'N': 9999, 'W': 4000}
我们可以看到,W员工的工资更改为4000,N员工的工资也更改为9999,同时K是新进来的员工。
键查找值
#键值查找的基本操作
stock = {'AXP':75.1,'AT':89}
stock['AAA']
输出结果
Traceback (most recent call last):
File "" , line 1, in <module>
stock['AAA']
KeyError: 'AAA'
键’AAA’不在字典 stock 里面,所以会产生异常
#字典的get()方法
print(stock.get('AAA'))
get()方法可以返回指定键的值,如果值不存在,它会返回默认值
输出结果
None
我们可以发现通过键查找值,第一种方法在键不存在的时候,就会发生异常,而第二种就不会,发生异常的时候我们知道程序会中止,所以在使用的时候我们推荐用第二种get()方法。
删除字典
有一个字典astock,通过赋值给bstock,接着清空astock的内容,但是我们可以看到bstock里面的内容还是原来的值,这是因为astock和bstock原来都指向这个对象{‘AXP’:78.5,‘AT’:85},而astock = {}这条语句导致astock指向了另外的一个对象,所以astock和bstock之间就没有什么联系,因此bstock还是原来的值。
astock = {'AXP':78.5,'AT':85}
bstock = astock
astock = {}
bstock
输出结果
Out[504]: {'AT': 85, 'AXP': 78.5}
clear()方法
清空原始对象,且对它复制引用的对象也会被清空
astock = {'AXP':78.5,'AT':85}
bstock = astock
astock.clear()
bstock
输出结果
Out[508]: {}
字典常用的方法
| clear() | copy() | fromkeys() | get() | items() |
|---|---|---|---|---|
| keys() | pop() | setdefault() | update() | values() |
3.2.4.3 注意事项
定义字典时,键不能重复,否则重复的键值会替代原先的键值。
dict_2 = {'a':10,'b':11,'c':12,'a':14}
dict_2
Out[79]: {'a': 14, 'b': 11, 'c': 12}
在使用的时候注意,字典不像序列那样,通过索引确定对象,而是通过键确定对象。
astock = {'AXP':78.5,'AT':85}
比如我们要弹出astock它的第一个成员
- ×:astock.pop(0)
- √:astock.pop(‘AXP’)
3.3 Python 的程序控制
3.3.4 循环结构
循环语句可用于遍历枚举一个可迭代对象的所有取值或其元素,每一个被遍历到的取值或元素执行指定的程序并输出。这里可迭代对象指可以被遍历的对象,比如列表、元组和字典等。
循环通常用来解决复杂问题的必备结构,在Python中,有for循环和while循环这两种结构。
3.3.4.1 for 循环

for 循环比较适合循环次数确定的情况。
语法:for 加上一个变量 in 可迭代的对象里面,可迭代就是说它的值是可以遍历的,在 Python中可迭代对象主要有:字符串、列表、元组、字典和文件。for 循环常常用来遍历一个数据集内的成员,另外它在列表解析和生成器表达式当中也使用。
下面是一个 for 循环的例子,i 用于指代一个可迭代对象a的一个元素,for 循环写好条件后以冒号结束,并换行缩进 ,第二行是针对每次循环执行的语句,这里是打印列表 a 中的每一个元素。
a = [2,3,4,5,6]
for i in a:
print(i)
输出结果
2
3
4
5
6
上述操作也可以通过遍历一个可迭代对象的索引来完成,b 列表一共 5 个元素,range(len(b)) 表示生成 a 的索引序列,这里打印索引并打印 b 向量索引下的取值。
b = ['h','e','l','l','o']
for i in range(len(b)):
print(i,b[i])
输出结果
0 h
1 e
2 l
3 l
4 o
range()函数的返回值是一个range对象,也是一个可迭代的对象
for i in range(3,11,2):
print(i,end=' ')
3 5 7 9
列表解析的语法
假设我们要生成一个0到9的整数序列,首先有一对中括号,在中括号里面有一个表达式,例如 i for 一个可迭代的变量i in 一个可迭代的对象里面
[i for i in range(5)]#整数序列
Out[252]: [0, 1, 2, 3, 4]
列表解析后面还可以加一个条件,例如要生成一个1-10之间的奇数序列
[i+1 for i in range(10) if i % 2 ==0]
Out[253]: [1, 3, 5, 7, 9]
生成器表达式的语法
语法与列表解析类似,只不过它用的是圆括号
(i for i in range(5))
Out[254]: <generator object <genexpr> at 0x0000028F5BADA2B0>
返回的是一个生成器,而不是创建一个列表,一般在数据量比较大的时候,我们就用生成器表达式;数据量不大的时候,我们就考虑用列表解析。
猜游戏(允许猜五次)
程序随机产生一个0~300间的整数,玩家竞猜,允许猜多次,系统给出“猜中”、“太大了”或“太小了”的提示。
#猜游戏(多次)
from random import randint
x = randint(0,300)
for count in range(0,5):
print('Please input a number between 0~300:')
digit = int(input())
if digit == x:
print('Bingo')
elif digit > x:
print('Too large,please try again')
else:
print('Too small,Please try again')
测试结果
Please input a number between 0~300:
50
Too small,Please try again
Please input a number between 0~300:
199
Too large,please try again
Please input a number between 0~300:
87
Too small,Please try again
Please input a number between 0~300:
100
Too small,Please try again
Please input a number between 0~300:
150
Too small,Please try again
3.3.4.2 while 循环

下面的例子中,条件表达式 j<10后面加上一个冒号,当条件表达式为真的时候,反复执行下面的两条语句,注意代码块需要缩进,跳出循环即不满足条件的时候,j=10时。
#while
#赋初值
sumA = 0
j = 1
while j <10:
sumA +=j
j+=1
最终sumA的值为45(0到9的和),j的值为10。
while 循环一般会设定一个终止条件,条件会随着循环的运行而发生变化,while 是在条件不成立的时候停止,因此 while 的作用概括一句话就是:只要…条件成立,就一直做…。
计数器 count 每循环一次自增 1 ,但 count 为 5 时,while 条件为假,终止循环。
count = 1
while count <5:
count +=1
print(count)
输出结果
2
3
4
5
循环中的break、continue语句
当条件满足的时候,跳过continue之后的语句。
所以continue的功能就是停止当前循环重新进入循环,和break不一样,break是终止整个循环,而continue只是停止当前的一轮循环。
猜数字游戏(想停就停,非固定次数)
程序随机产生一个0~300间的整数,玩家竞猜,允许玩家自己控制游戏次数,如果猜中系统给出提示并退出程序。如果猜错给出“太大了”或“太小了”的提示,如果不想继续玩可以退出。
from random import randint
x = randint(0,300)
go = 'y'
while(go == 'y'):
digit = int(input('Please input a number between 0~300:'))
if digit == 'x':
print('Bingo!')
break
elif digit > x:
print('Too large,please try again')
else:
print('Too small,please try again')
print('Input y if you want to continue.')
go = input()
print(go)
else:
print('Goodbye!')
注意一下:在Python中,else是可以与while进行搭配,循环中else语句,如果循环代码从break处终止,那么就跳出循环,不执行后面else语句中的代码,如果正常结束循环,则会执行else中的代码
测试结果
Please input a number between 0~300:50
Too small,please try again
Input y if you want to continue.
y
y
Please input a number between 0~300:200
Too large,please try again
Input y if you want to continue.
n
n
Goodbye!
判断一个数是否为素数。
from math import sqrt
num = int(input('Please enter a number:'))
j = 2
while j <= int(sqrt(num)):
if num % j == 0:
print('{:d} is not a prime.'.format(num))
break
j += 1
else:
print('{:d} is a prime.'.format(num))
测试结果
Please enter a number:7
7 is a prime.
- continue 控制循环
continue 满足条件则继续进行循环,如下代码是打印 10 以内能够被 3 整除的整数
count = 0
while count <10:
count +=1
if count % 3 == 0:
print(count)
continue
输出结果
3
6
9
- break 控制循环
break 表示一旦满足条件则终止循环。
count = 1
while count < 10:
count += 1
if count % 3 == 0:
print(count)
break
输出结果
3
累加的例子
如果累加的和大于10,我们就break
sum10 = 0
i = 1
while True:
sum10 += i
i += 1
if sum10 > 10:
break
print('i={},sum={}'.format(i,sum10))
输出结果
i=6,sum=15
当满足break的条件的时候,跳出当前它所在的一个循环结构。
#输出2-100之间的素数
from math import sqrt
j=2
while j <= 100:
i = 2
k = sqrt(j)
while i <= k:
if j%i==0:break
i = i + 1
if i > k:
print(j,end = ' ')
j += 1
输出结果
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
用for语句来求出2-100之间的素数
from math import sqrt
for i in range(2,101):
flag = 1#赋初值
k = int(sqrt(i))
for j in range(2,k+1):
if i%j == 0:
flag = 0
break
if(flag):
print(i,end=',')
输出结果
2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,
- pass 语句
pass语句一般是为了保持程序的完整性而作为占位符使用,例如以下代码中 pass 没有任何操作。
count = 0
while count < 10:
count += 1
if count %3 == 0:
pass
else:
print(count)
输出结果
1
2
4
5
7
8
10
3.3.4.3 表达式
在Python中,诸如列表、元组、集合和字典都是可迭代对象,Python为这些对象的遍历提供了更加简洁的写法。例如如下列表对象 x 的遍历,且每个元素取值除以 10。
x = [1,2,3,4]
[i/10 for i in x]
输出结果
[0.1, 0.2, 0.3, 0.4]
上述[i/10 for i in x] 的写法称为列表表达式,这种写法比 for 循环更加简便,此外对于元组对象、集合对象、字典对象,这种写法依旧适用,最终产生一个列表对象。
#元组
x1 = (1,2,3)
[i/10 for i in x1]
#集合
x2 = {2,4,5}
[i/10 for i in x2]
#字典
x3 = {'a':3,'b':4,'c':5}
#输出字典的键
[i for i in x3.keys()]
#输出字典的值
[i for i in x3.values()]
此外,Python 还支持集合表达式与字典表达式用于创建集合、字典,例如如下形式创建集合。
#创建集合
{i for i in [1,1,1,2,2]}
Out[110]: {1, 2}
字典表达式可以用如下方式创建
#字典表达式
{key:value for key,value in [('a',1),('b',2),('c',3)]}
Out[111]: {'a': 1, 'b': 2, 'c': 3}
3.3.5 选择结构
if 语句

length1 = 3
length2 = 3
if length1 == length2:
print("The Square's area is",length1*length2)
输出结果
The Square's area is 9
下面介绍当条件表达式为真的时候的执行语句,以及条件表达式为假的时候执行另外的语句,也就是用到 else 语句。
else 语句

length1 = int(input("The First Side:"))
length2 = int(input("The Second Side:"))
if length1 == length2:
print("The Square's Area is",length1*length2)
else:
print("The Rectangle's Area is",length1*length2)
输出结果
The First Side:8
The Second Side:9
The Rectangle's Area is 72
elif 语句
语法规则

如果满足第一个条件,就执行第一个条件的代码块;如果第一个条件不满足,但是满足第二个条件,那么就执行第二个条件的代码块;以此类推,直到以上所有的条件都不满足,就执行else语句的代码块。
以下举出一个小例子:输入形状的编号,最后会输出这个编号对应的形状。主要是让大家熟悉语法规则以及对齐的地方和缩进的地方。
k = input('input the index of shape:')
if k == '1':
print(circle)
elif k == '2':
print('oval')
elif k == '3':
print('retangle')
elif k == '4':
print('triangle')
else:
print('you input the invalid number')
我们可以看到,这里 if 与 elif 、else 都是对齐的;其中 if 、elif 和 else 下面的代码块都是要用缩进的方式。
输出的结果
input the index of shape:4
triangle
假设在一个条件里面我们还要再来分一种或者两种以上的情况,,比如上面的例子中 k 等于3的情况下,我们又要分它有几种情况,这就需要下面讲的条件嵌套。
条件嵌套
条件里面套条件就是条件嵌套
在 k 等于 3 的时候,我们又再分两种情况。
k = input('input the index of shape:')
if k == '1':
print(circle)
elif k == '2':
print('oval')
#条件嵌套
elif k == '3':
length1 = int(input("the first side:"))
length2 = int(input("the first side:"))
if length1 == length2:
print("the square's area is",length1*length2)
else:
print("the rectangle's area is",length1*length2)
elif k == '4':
print('triangle')
else:
print('you input the invalid number')
输出结果
input the index of shape:3
the first side:8
the first side:2
the rectangle's area is 16
猜数字游戏
程序随机产生一个0~300间的整数,玩家竞猜,系统给出“猜中”、“太大了”或“太小了”的提示。
首先需要用到random 模块的 randint() 这个函数,这个函数的功能就是你后面给出的参数之间的一个数的范围,就是它产生的结果。比如下面的例子中 x 就会获得在0~300间随机产生的一个数,这是系统给出的 x 的值。我们使用内建函数中的 input()函数来获取用户的输入。
#猜数字的游戏
from random import randint
x = randint(0,300)
print(x)
digit = int(input("Please input a number between 0~300:"))
if digit == x:
print("x is",x," Bingo!")
elif digit > x:
print("x is",x," The number is too large!")
else:
print("x is",x," The number is too small!")
输出结果
19
Please input a number between 0~300:50
x is 19 The number is too large!
条件编程练习
练习题1:编写一个输入分数,输出分数等级的程序,具体为
Score Grade
90~100 A
70~89 B
60~69 C
0~59 D
others Invalid score
请添加必要的输入输出语句,尽量让程序友好。
score = eval(input("enter the score: "))
if 0<= score <= 100:
if 90 <= score <= 100:
grade = "A"
elif score >= 70:
grade = "B"
elif score >= 60:
grade = "C"
elif score >= 0:
grade = "D"
#字符串的format()方法中参数输出的位置和格式等由其前面字符串中的{}位置和格式(d表示十进制)决定
print("The grade of {} is {}.".format(score,grade))
else:
print("Invalid score")
练习题1的输出结果
enter the score: 96
The grade of 96 is A.
enter the score: 72
The grade of 72 is B.
enter the score: 65
The grade of 65 is C.
enter the score: 58
The grade of 58 is D.
enter the score: 101
Invalid score
练习题2:编写程序,从键盘输入一个二元一次方程 ax^2+bx+c=0 的三个参数a、b、c(均为整数),求此方程的实根。如果方程有实根,则输出实根(保留一位小数),如果没有实根则输出没有实根的信息。
from math import sqrt
a,b,c = eval(input())
t = b*b-4*a*c
if t>0:
x1 = (-b+sqrt(t))/(2*a)
x2 = (-b-sqrt(t))/(2*a)
print('x1 = {:.1f},x2 = {:.1f}'.format(x1,x2))
elif t==0:
x = -b/(2*a)
print('x = {:.1f}'.format(x))
else:
print("no real solution")
2,2,3
no real solution
3.4 Python 的函数与模块
3.4.1 Python 的函数
函数(一)
-
函数可以看成类似成数学中的函数
-
完成一个特定功能的一段代码
-
类型函数type()
函数(二)
-
内建函数:不需要另外导入的一些函数
-
str() 和 type() 适用于所有标准类型
| 函数 | 功能 | 函数 | 功能 |
|---|---|---|---|
| abs() | 绝对值函数 | bool() | 将变量转换为布尔值 |
| oct() | 将一个整数转换成八进制字符串 | round() | 四舍五入 |
| int() | 将其他数据类型转换为整型 | hex() | 将十进制整数转换为十六进制,以字符串形式语法 |
| divmod() | divmod(a,b)接受两个数值(非复数),返回两个数值的相除得到的商,和余数组成的元组 | ord() | 返回对应字符的ascii码 |
| pow() | pow(x,y[,z])两个必需参数和一个可选参数,结果返回x**y,如果可选参数有传入值,则返回幂乘之后再对z取模(相当于pow(x,y)%z | float() | 将其他数据类型转换为浮点型 |
| chr() | range(256)内的(就是0-255)整数做参数,返回一个对应的字符 | complex() | 创建复数或转换为复数 |
| 函数 | 功能 | 函数 | 功能 |
|---|---|---|---|
| dir() | 列出对象的所有属性 | input() | 获取用户输入的信息 |
| help() | 返回对象的帮助信息 | open() | 打开一个文件,返回一个文件读写对象,然后可以对问卷进行相应读写操作 |
| len() | 返回对象的长度 | range() | 创建一个整数列表 |
Python还有很多的内建函数,感兴趣的小伙伴可以在Python中输入下面一行代码可以查看从abs开始到zip结束的一些内建函数。不明白的可以使用help()查看帮助。
#查看内建函数
dir(__builtins__)
小练习:编写一个输入输出的程序
编程实现输入姓、名的提示语并接受用户输入,并单独显示姓、名和全名。
surname = input('Input your surname: ')
firstname = input('Input your firstname: ')
print('Your surname is:',surname)
print('Your firstname is:',firstname)
print('Your full name is:',surname,firstname)
输出结果
Input your surname: Ma
Input your firstname: Zhongjun
Your surname is: Ma
Your firstname is: Zhongjun
Your full name is: Ma Zhongjun
1. 自定义函数
函数在调用前必须先定义,可以是系统事先定义好的内置函数,也可以是用户自定义函数。
def 后面是函数名,再加一对括号,中间是一个参数,而这个参数是可选的,后面再跟一个冒号,回车之后的是函数体的代码块。下面的例子中 ‘apply operation + to argument’ 这是一个字符串,这个在Python当中被称为DocString,一个文档字符串,它是程序的注释,放在最前面,通常写函数的时候需要写DocString,当我们要看其他函数的注释的时候,使用print后面加一个“函数名.__doc__"(doc左右两边是两个下划线),进行查看。
def add(x):
'apply operation + to argument'
return (x+x)
测试结果
add('嘻哈')
Out[270]: '嘻哈嘻哈'
add()
Traceback (most recent call last):
File "" , line 1, in <module>
add()
TypeError: add() missing 1 required positional argument: 'x'
自定义函数的调用
- 函数名加上函数运算符,一对小括号
- 括号之间是所有可选的参数
- 即使没有参数,小括号也不能省略
如果本身带有参数,调用的时候不写参数则会报错。
自定义函数:输出1-100之间的素数。
from math import sqrt
#判断素数的自定义函数部分
def isprime(x):
if x == 1:
return False
k = int(sqrt(x))
for j in range(2,k+1):
if x % j == 0:
return False
return True
for i in range(2,101):
if isprime(i):
print(i,end=' ')
输出结果
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
默认参数(一)
函数的参数可以有一个默认值,如果提供有默认值,在函数定义中,默认参数以赋值语句的形式提供。
f()#使用默认参数
x is a correct word
Ok
默认参数(二)
默认参数的值可以改变
f(False)#更改默认参数值
Ok
默认参数(三)
默认参数一般需要放置在参数列表的最后
def f(y = True,x):
'''x and y both correct words or not'''
if y:
print(x,' and y both correct.')
print(x,' is Ok.')
测试结果
File "" , line 1
def f(y = True,x):
^
SyntaxError: non-default argument follows default argument
函数执行之后会报错,比如f(False)的时候,实参False是传递给形参y还是x就没法确定,因此在Python当中就要求默认参数要放到参数列表的最后。
关键字参数
- 关键字参数是让调用者通过参数名区分参数。
- 允许改变参数列表中的参数顺序
def key(x,y):
if y:
print(x,' and y both correct')
print(x,' is OK')
测试1
key(68,False)
68 is OK
测试1中函数的参数没有特殊的形式,通常称作为位置参数。如果搞错位置,结果往往会搞错。
如果有多个位置参数的话,参数的顺序经常会记错,记乱。为了解决这样的情况,我们可以使用参数的名字进行调用。这就是我们要说的关键字参数。
我们在调用的时候可以直接把参数名写下来,这样我们就不用考虑参数的顺序。
测试2
key(y = False,x = 68)
68 is OK
测试3
key(y = False,68)
输出结果
File "" , line 1
key(y = False,68)
^
SyntaxError: positional argument follows keyword argument
测试4
key(x = 68,False)
输出结果
File "" , line 1
key(x = 68,False)
^
SyntaxError: positional argument follows keyword argument
出错的原因是非关键字参数跟在关键字参数的后面,也就是意味着一旦你使用了关键字参数,后面就必须是关键字参数。进一步来说:关键字参数的使用已经把整个的参数表打乱了,所以一旦它开始,我们后面必须把所有的参数名都写下来。
传递函数
- 函数可以像参数一样传递给另外一个函数
def add2(x):
return (x+x)
def self2(f,y):
print(f(y))
self2(add2,2.5)
测试结果
5.0
f(y)中输送一个函数名给self2函数的第一个参数,把函数名当作一个普通参数一样传给另外一个函数,称为传递函数,self2()函数的调用过程是:print(add2(2.2))
2. lambda 函数
- 匿名函数
- 没有return
- 不需要有定义函数的过程
def sumx(x):
return (x+x)
sumx(5)
#lambda
r = lambda x:x+x
r(5)
输出的结果都是10。
在lambda函数中是把右边的运算结果赋给变量 r ,lambda函数不需要取函数名,但是最后调用的时候还是需要一个变量名。
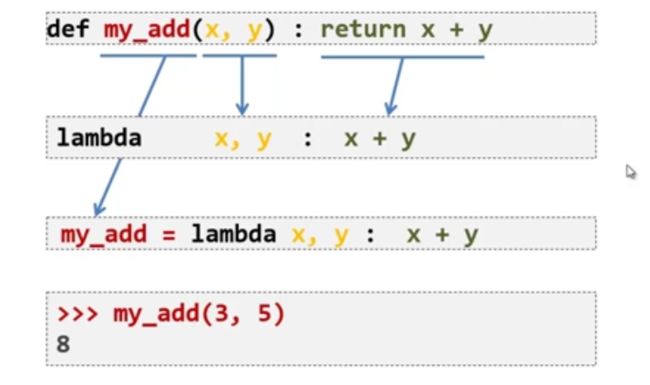
lambda函数的编程类似与filter()、reduce()等这些函数结合起来还是非常方便。
g = lambda x:x+1
g(2)
该函数相当于如下自定义函数
def g(x):
return (x+1)
g(2)
函数的参数
函数的参数可以分为形式参数与实际参数,形式参数作用与函数的内部,其不是一个实际存在的变量,当接受一个具体值时(实际参数),复制将具体值传递到函数内部进行运算。实际参数即具体值,通过形式参数传递到函数内部参与运算并输出结果。比如下面自定义的函数avg,形式参数为x,实际参数为一个列表。
def avg(x):
mean_x = sum(x)/len(x)
return(mean_x)
avg([23,34,12,34,56,23])
输出结果
Out[113]: 30.333333333333332
函数参数的传递有两种方式:按位置和按关键字。当函数的形式参数过多时,一般采用按关键字传递的方式,通过形式参数名 = 实际参数的方式传递参数,如下所示,函数 age 有四个参数,可以通过指定名称的方式使用,也可以按照顺序进行匹配。
def age(a,b,c,d):
print(a)
print(b)
print(c)
print(d)
#关键字指定名称
age(a = 'young',c = 'median',b = 'teenager', d = 'old')
#按位置顺序匹配
age('young', 'teenager', 'median', 'old')
输出结果
young
teenager
median
old
函数的参数中,亦可以指定形式参数的默认值,此时该参数称为可选参数。
3.4.2 Python 的模块
模块(一)
非内建函数如何使用?
floor()是向下取整函数,如果我们直接使用这个函数,系统会报错,错误信息会提示:name ‘floor’ 没有定义,这是因为floor()并不是内建函数,它属于数学库函数,它包含在math这个模块里面。
floor(5.9)
报错信息
Traceback (most recent call last):
File "" , line 1, in <module>
floor(5.9)
NameError: name 'floor' is not defined
非内建函数,我们在使用时首先要把它的模块 import 进来,也就是导入,因此,如果要使用floor()这个函数,我们要把它的模块通过"import math" 这样的方式进行导入。
from math import *
floor(36.8)
floor(-35.9)
输出结果
36
-36
模块(二)
-
一个完整的Python文件即是一个模块
- 文件:物理上的组织方式 math.py
- 模块:逻辑上的组织方式 math
-
Python通常用“import 模块"的方式将现成模块中的函数、类等重用到其他代码中
import math
math.sqrt(9)
导入成功之后,可以使用里面的一些变量或者函数
模块(三)导入多个模块
模块里导入指定的模块属性,也就是把指定名称导入到当前作用域。
import ModuleName
#导入多个模块
import ModuleName1,ModuleName2,...#import 加上多个模块名,用逗号分隔
#在模块里面导入指定的模块属性
from Module1 import ModuleElement#from 加上模块名,接着import 加上后面的模块属性
区别:这两者之间,一个是把模块中的所有函数和类都导入;另外一个是导入了其中部分的函数或者类。
3.4.3 Python 的包
- 一个有层次的文件目录结构
- 定义了一个由模块和子包组成的Python应用程序执行环境
下面的例子中,AAA是最顶层的包,CCC、DDD、EEE这样的一些是它的子包,而像c1、c2就是它的模块。如果我们要调用模块c1中的函数func1(),我们可以通过下面两种方式进行调用。

(1)import 包名.子包名.模块名
#第一种方式
import AAA.CCC.c1
AAA.CCC.c1.func1(123)
(2)from import
直接把 c1 模块中的函数 func1()导入
#第二种方式
from AAA.CCC.c1 import func1
func1(123)
3.5 Pandas 读取结构化数据
3.5.1 读取数据
import os
import pandas as pd
os.chdir("G:\python学习")#设置工作路径
sample = pd.read_csv('data/sample.csv')
sample
输出结果
Out[134]:
name scores
0 小明 79
1 晓东 85
2 小白 95
按照惯例,Pandas 会以 pd 作为别名, pd.read_csv 函数可以实现读取 指定路径下的 csv 数据,然后返回一个 DataFrame 对象。
此外,read_csv 函数有很多参数可以设置,这里列出常用参数。
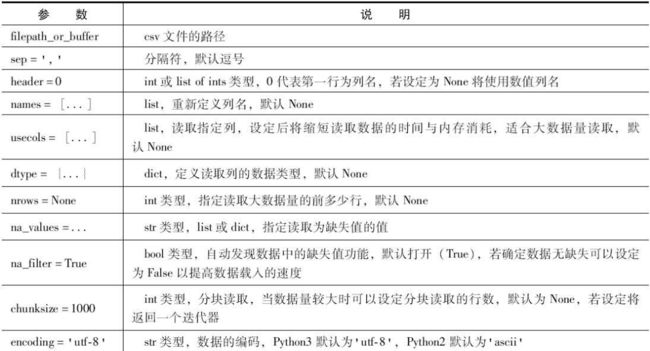
读取指定行和指定列
使用参数usecol和 nrows 读取指定的列和前 n 行,这样可以加快数据读取速度。
#读取name一列,仅读取前一行
sample_subset = pd.read_csv('data/sample.csv',\
usecols = ['name'],\
nrows = 1)
sample_subset
输出结果
Out[136]:
name
0 小明
第四章 描述性统计分析与绘图
4.1 描述性统计进行数据探索
4.1.3 连续变量的分布与集中
不同的分布情况下,均值、中位数、众数差异。

sndHsPr数据集是一份二手房屋价格的数据
| 变量名 | 含义 | 变量名 | 含义 | 变量名 | 含义 |
|---|---|---|---|---|---|
| dist | 城区(拼音) | roomnum | 卧室数 | halls | 厅数 |
| floor | 楼层 | subway | 是否地铁房 | school | 是否学区房 |
| AREA | 房屋面积 | price | 单位面积房价 | district | 城区(中文,衍生) |
#设置工作区间
import pandas as pd
import os
os.chdir(r'F:\Python_book\4Describe')
snd = pd.read_csv("sndHsPr.csv")
求出price的均值、中位数、方差与标准差(其中agg()函数的功能是归并若干个函数的结果)
#求均值、中位数、方差与标准差
snd.price.agg(['mean','median','sum','var','std'])
输出结果
Out[291]:
mean 6.115181e+04
median 5.747300e+04
sum 9.912709e+08
var 4.969938e+08
std 2.229336e+04
Name: price, dtype: float64
求出price的四分位数
#求四分位数
snd.price.quantile([0.25,0.5,0.75])
输出结果
Out[292]:
0.25 42812.25
0.50 57473.00
0.75 76099.75
Name: price, dtype: float64
查看price变量的分布,这里的bins参数表示直方图下的区间个数
#直方图
snd.price.hist(bins=20)#bins参数表示直方图下的区间个数
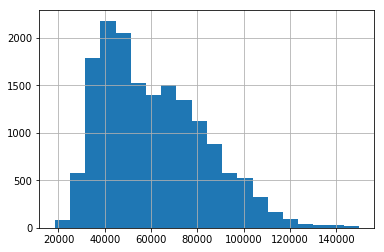
可以看出单位面积房价略有一些右偏。
4.1.4 连续变量的离散程度
只描述数据的集中水平是不够的,因为这样会忽视数据的差异情况。这里需要引入另一种指标或统计量用以描述数据的离散程度。
- 极差:即变量的最大值与最小值之差
- 方差与标准差
snd.price.max()-snd.price.min()#极差
snd.price.agg(['var','std'])#var:方差;std:标准差
4.1.5 数据分布的对称与高矮
偏度即数据分布的偏斜程度;峰度即数据分布的高矮程度。
标准正态分布(均值为0,标准差为1)的变量,其偏度和峰度都为0。
-
偏度大小以及正负取决于分布偏移的方向及程度
- 左偏分布:偏度小于0
- 对称分布:偏度等于0
- 右偏分布:偏度大于0
-
峰度大小以及正负取决于分布较标准正态分布的高矮
- 峰度大于0,说明变量的分布相比较标准正态分布更加密集
- 峰度小于0,说明变量的分布相比较标准正态分布更加分散
在Pandas 中,提供了skew 和 kurtosis 方法实现偏度和峰度。
例如:模拟100个标准正态分布的随机数?
normal = pd.Series(np.random.randn(1000),name = 'normal')
normal.skew()#偏度
normal.kurtosis()#峰度
4.2 制作报表与统计制图
获取每个城区的频次
snd.district.value_counts()#value_counts()函数获取每城区出现的频次
输出结果
Out[307]:
丰台区 2947
海淀区 2919
朝阳区 2864
东城区 2783
西城区 2750
石景山区 1947
Name: district, dtype: int64
"kind = "为图表类型,柱形图为 bar, 饼形图为 pie。
#条形图与饼图
#如遇中文显示问题可加入以下代码
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
snd.district.value_counts().plot(kind = 'bar')
#snd.district.value_counts().plot(kind = 'pie')


表分析:分析两个分类变量的联合分布情况,提供每个单元格的频次、百分比和边沿情况。表分析(也称为交叉表)用的函数为pd.crosstab()。
pd.crosstab(snd.subway,snd.school)#分析subway与school之间的关系
输出结果
Out[312]:
school 0 1
subway
0 2378 413
1 8919 4500
可以使用标准化的堆叠柱形图对表分析的结果进行展示。其步骤是先获取交叉表的结果,然后使用div(sub_sch.sum(1),axis = 0)函数计算交叉表的行百分比,然后做柱形图。
sub_sch = pd.crosstab(snd.subway,snd.school)
sub_sch = sub_sch.div(sub_sch.sum(1),axis=0)
sub_sch.plot(kind='bar',stacked=True)
输出结果

还可以使用stack2dim()函数制作,snd为当前所使用的数据框,i、j为两个分类变量的变量名称,要求带引号。
from stack2dim import *
stack2dim(snd, i="subway", j="school")

- 汇总统计量:按照某个分类变量分组,对连续变量进行描述性统计。
snd.price.groupby(snd.district).agg(['mean','max','min'])
输出结果
Out[319]:
mean max min
district
东城区 71883.595041 149254 20089
丰台区 42500.904309 87838 18348
朝阳区 52800.624651 124800 23011
海淀区 68757.602261 135105 25568
石景山区 40286.889574 100000 18854
西城区 85674.778545 149871 21918
盒须图也称为箱线图,能够提供某变量分布以及异常值的信息。
import seaborn as sns
sns.boxplot(data = snd,x='district', y='price')

箱线图提供了识别异常值的一个标准:异常值通常被定义为大于Q3+1.5IQR或小于Q1-1.5IQR。
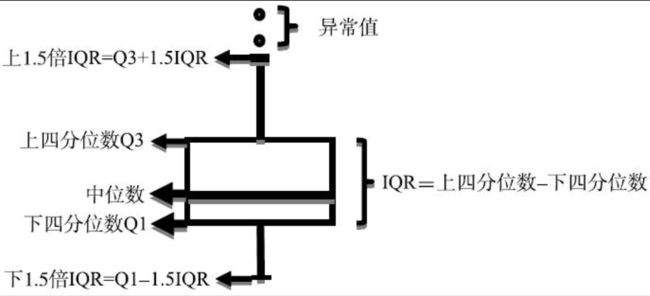
- Q1:下四分位数,表示全部观测值中有四分之一的数据取值比它小
- Q3:上四分位数,表示全部观测值中有四分之一的数据取值比它大
- IQR: 称为四分位数间距,是上四分位数与下四分位数的差,这个范围代表了数据中50%的数据
- 中位数:代表变量中位数中总体分布中的位置
柱形图
使用每个城区单位面积房屋均价作为柱高。
snd.price.groupby(snd.district).mean().plot(kind='bar')
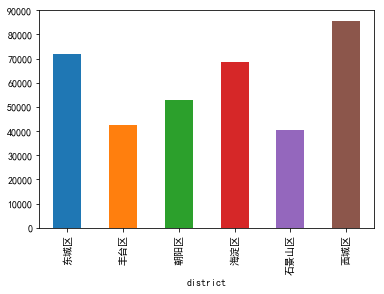
如果我们关心的是每个城区平均房屋价格的排序情况,则使用条形图。
#每个城区平均房屋价格的排序情况
snd.price.groupby(snd.district).mean().sort_values(ascending = True).plot(kind='barh')

条形图与柱形图非常相似,按照因子排序展现数据的时候常用柱状图(例如使用时间作为因子);如果因子是无序的,同时按照数据大小进行展示时常用条形图(例如展示不同地区的房价,房价从高到低排序)。
散点图
使用房屋使用面积和单位面积房价这两个变量之间的关系。
snd.plot.scatter(x = 'AREA', y = 'price')

第五章 数据整合和数据清洗
5.1 数据整合
5.1.1 行列操作
Pandas数据框可以方便地选择指定列、指定行,例如创建一个数据框,产生一组4行5列的正态分布随机数,columns参数表示定义相应的列名。
sample = pd.DataFrame(np.random.randn(4,5),columns = ['First','Second','Third','Fourth','Fifth'])
sample
输出结果
Out[333]:
First Second Third Fourth Fifth
0 -0.867004 -1.161871 -1.105819 0.943504 -0.552097
1 -0.363334 0.075978 -1.195192 1.119592 1.282178
2 -1.900368 0.239162 0.275959 -0.076309 0.814495
3 -0.707469 1.035810 1.171252 0.299344 -1.349734
- 选择单列
- 直接以列名选择列
- ix、iloc、loc方法
- iloc方法只能使用数值作为索引选择行、列
- loc方法在选择列时只能使用字符索引
- ix方法可以使用两种索引
选择第一列
sample['First']#以列名进行访问
sample.iloc[:,0]#iloc方法
sample.loc[:,'First']#loc方法
sample.ix[:,'First']#ix方法
输出结果
Out[336]:
0 -0.867004
1 -0.363334
2 -1.900368
3 -0.707469
Name: First, dtype: float64
注意,选择单列时,返回的是Pandas序列结构的类,也可以使用以下方法在选择单列时返回Pandas数据框类。
sample[['First']]
- 选择多行和多列
数据框选择行时,可以直接使用行索引进行选择。
注意:ix或loc方法选择时,行索引是前后都包括的,这与列表索引不太一样;
若习惯使用列表索引那样前包后不包,可以使用iloc。
sample.ix[0:3,1:4]#行索引:前后都包括,四行三列
输出结果
Out[337]:
Second Third Fourth
0 -1.161871 -1.105819 0.943504
1 0.075978 -1.195192 1.119592
2 0.239162 0.275959 -0.076309
3 1.035810 1.171252 0.299344
sample.iloc[0:3,1:4]#行索引:前包括,后不包括,三行三列
输出结果
Out[338]:
Second Third Fourth
0 -1.161871 -1.105819 0.943504
1 0.075978 -1.195192 1.119592
2 0.239162 0.275959 -0.076309
- 创建、删除
创建新列有两种方法
- 直接通过赋值
- assign方法
新建列’new_1’,取值由原先两列计算得出
sample['new_1'] = sample['First'] - sample['Second']
sample
输出结果
Out[340]:
First Second Third Fourth Fifth new_1
0 -0.867004 -1.161871 -1.105819 0.943504 -0.552097 0.294867
1 -0.363334 0.075978 -1.195192 1.119592 1.282178 -0.439313
2 -1.900368 0.239162 0.275959 -0.076309 0.814495 -2.139530
3 -0.707469 1.035810 1.171252 0.299344 -1.349734 -1.743279
新建列’new_2’和’new_3’,使用assign方法来完成。
sample.assign(new_2 = list('1234'),new_3 = list('4567'))
sample.shape
输出结果
Out[342]:
First Second Third Fourth Fifth new_1 new_2 new_3
0 -0.867004 -1.161871 -1.105819 0.943504 -0.552097 0.294867 1 4
1 -0.363334 0.075978 -1.195192 1.119592 1.282178 -0.439313 2 5
2 -1.900368 0.239162 0.275959 -0.076309 0.814495 -2.139530 3 6
3 -0.707469 1.035810 1.171252 0.299344 -1.349734 -1.743279 4 7
Out[343]: (4, 6)
new_sample = sample.assign(new_2 = list('1234'),new_3 = list('4567'))
new_sample.shape
输出结果
Out[346]: (4, 8)
注意:assign这种方式生成的新变量不会保留在原始表中,需要赋值给新表才可以。
删除列时,可以使用数据框的方法drop。
sample.drop('First',axis=1)#删除一列:'First'
sample.drop(['Second','Third'],axis=1)#删除多列:'Second'、'Third'
5.1.2 条件查询
首先生成示例数据框
record = pd.DataFrame({'name':['Bob','Lindy','Mark','Miki','Sully','Rose'],
'score':['98,78,87,77,65,67'],
'group':[1,1,1,2,1,2]})
- 单条件
涉及条件查询时,一般会使用一些比较运算符,例如”>“ ”==“ ”<=“等,比较运算符产生布尔类型的索引可用于条件查询,例如 record 数据框查询score大于70分的人,首先生成bool索引。
record.score >70
输出结果
Out[353]:
0 True
1 True
2 True
3 True
4 False
5 False
Name: score, dtype: bool
再通过指定索引进行条件查询,返回bool值为True的数据。
record[record.score >70]
输出结果
Out[354]:
group name score
0 1 Bob 98
1 1 Lindy 78
2 1 Mark 87
3 2 Miki 77
- 多条件
多条件查询时,涉及bool运算符,Pandas支持以下bool运算符
| bool运算符 | 意义 |
|---|---|
| & | 与 |
| ~ | 非 |
| | | 或 |
record [(record.score >70) & (record.group ==1)]#&:与
record [~(record.group == 2)]#~:非
record [(record.group == 2 ) | (record.group ==1)]#|:或
- query
Pandas数据框提供了方法query,可以完成指定的条件查询。
#query
record.query('score > 70')
record.query('(score >70) & (group ==1)')
record.query('~(group == 2)')
record.query('(group == 2 ) | (group ==1)')
- 其他
Pandas还提供了一些有用的方法可以更加简便地完成查询任务。
| 方法 | 示例 | 对象 | 解释 |
|---|---|---|---|
| between | Df [ Df. col. between (10,20) ] | pandas.Series | col 在10到20之间的记录 |
| isin | Df [ Df. col. isin (10,20) ] | pandas.Series | col 等于10或20的记录 |
| str.contains | Df [ Df. col. str.contains ( '[M] + ’ ) ] | pandas.Series | col匹配以M开头的记录 |
between方法类似与SQL中between and,例如查record中分数在70到80之间的记录,这里70与80的边界是包含在内的,若不希望包含在内可以将inclusive参数设定为False。
#between
record[record['score'].between(70,80,inclusive = True)]
对于字符串来说,可以使用isin方法进行查询,例如筛选姓名为’Bob’ 'Lindy’的人的记录
#isin
record[record['name'].isin(['Bob','Lindy'])]
此外,还可以使用str.contains来进行正则表达式匹配进行查询,例如查询姓名以M开头的人的所有记录。
#str.contains
record[record['name'].str.contains('[M]+')]
5.1.3 横向连接
Pandas数据框提供了merge方法以完成各种表的横向连接操作,这种连接操作与SQL语句的连接操作是类似的,包括内连接、外连接。
- 内连接
内连接(inner join):查找结果只包括两张表中匹配的观测。

首先创建示例的两个数据框
df1 = pd.DataFrame({'id':[1,2,3],'col1':['a','b','c']})
df2 = pd.DataFrame({'id':[3,5],'col2':['d','e']})
内连接使用merge函数,根据公共字段保留两表共有的信息,how='inner’参数表示使用内连接,on表示两表连接的公共字段,若公共字段在两表名称不一致时,可以通过left_on和right_on指定。
df1.merge(df2,how='inner',on='id')
df1.merge(df2,how='inner',left_on='id',right_on='id')
输出结果
Out[373]:
col1 id col2
0 c 3 d
- 外连接
外连接(outer join)包括左连接、右连接和全连接三种连接。

- 左连接通过公共字段,保留左表的全部信息,右表在左表缺失的信息会以NaN补全;
- 右连接通过公共字段,保留右表的全部信息,左表在右表缺失的信息会以NaN补全;
- 全连接通过公共字段,保留两表的全部信息,两表互相缺失的信息会以NaN补全。
df1.merge(df2,how='left',on='id')#左连接
df1.merge(df2,how='right',on='id')#右连接
df1.merge(df2,how='outer',on='id')#全连接
输出结果
Out[374]:
col1 id col2
0 a 1 NaN
1 b 2 NaN
2 c 3 d
Out[375]:
col1 id col2
0 c 3 d
1 NaN 5 e
Out[376]:
col1 id col2
0 a 1 NaN
1 b 2 NaN
2 c 3 d
3 NaN 5 e
- 行索引连接
除了类SQL连接外,Pandas也提供了直接按照行索引连接,使用pd.concat函数或数据框的join方法。
示例
df11 = pd.DataFrame({'id1':[1,2,3],'col1':['a','b','c']},index=[1,2,3])
df12 = pd.DataFrame({'id2':[1,2,3],'col2':['aa','bb','cc']},index=[1,3,2])
上述两表中,df11索引为1、2、3,df12行索引为1、3、2,按照索引连接后,索引行会一一对应。pd.concat可以完成横向和纵向合并,这可以通过参数”axis=“来控制,当参数”axis=1“时表示进行横向合并。
pd.concat([df11,df12],axis=1)#axis=1表示横向合并
df11.join(df12)
输出结果
Out[389]:
col1 id1 col2 id2
1 a 1 aa 1
2 b 2 cc 3
3 c 3 bb 2
5.1.4 纵向合并
某公司四个季度的销售数据分散于四张表上,四张表字段名与含义完全相同,如果汇总全年的数据,按摩需要拼接四张表,此时涉及数据的纵向合并。
df1 = pd.DataFrame({'id':[10,11,12,13,14],'col':['A','B','C','D','E']})
df2 = pd.DataFrame({'id':[15,16,17],'col':['F','G','H']})
ignore_index = True 表示忽略 df1 和 df2 的原先索引,合并并重新排序索引。
pd.concat([df1,df2],ignore_index = True,axis=0)
输出结果
Out[395]:
col id
0 A 10
1 B 11
2 C 12
3 D 13
4 E 14
5 F 15
6 G 16
7 H 17
注意到这种纵向连接是不去除完全重复的行的,若希望纵向连接并去除重复值,可直接调用数据框的 drop_duplicates 方法,类似于 SQL 中的 UNION 操作。
pd.concat([df1,df2],ignore_index = True,axis=0).drop_duplicates()
此外,在进行纵向合并时,若连接的表的列名或列个数不一致时,不一致的位置会产生缺失值。
如下所示,首先将 df1 的列 col 重新命名为 new_col
df3 = df1.rename(columns = {'col':'new_col'})
此时再进行纵向合并,不一致处填补为NaN。
pd.concat([df3,df2],ignore_index = True,axis=0).drop_duplicates()
输出结果
Out[398]:
col id new_col
0 NaN 10 A
1 NaN 11 B
2 NaN 12 C
3 NaN 13 D
4 NaN 14 E
5 F 15 NaN
6 G 16 NaN
7 H 17 NaN
5.1.5 排序
在很多分析任务中,需要按照某个或某些指标对数据进行排序。Pandas在排序时,根据排序的对象不同可细分为以下三种:
- sort_value:对值进行排序;
- sort_index:对索引进行排序;
- sortlevel:对多维索的不同级别 level 进行排序。
最常见的是按照数值进行排序。
示例
sample = pd.DataFrame({'name':['Bob','Lindy','Mark','Miki','Sully','Rose'],
'score':[98,78,87,77,77,np.nan],
'group':[1,1,2,2,3,3]})
第一个参数表示排序的依据列,此处设为 score ;ascending = False 代表降序排序,设定为 True 时表示升序排序(默认);na_position = ‘last’ 表示缺失值数据排序在数据的最后位置(默认),该参数还可以设定为 ‘first’ 表示缺失值排序在数据的最前面。
#默认为升序排序,将缺失值数据排序在数据的最后位置(默认),还可以设置为'first'在最前面
sample.sort_values('score',ascending = False,na_position = 'last')
当然,排序的依据变量也可以是多个列,例如按照班级(group)、成绩(score)升序。
sample.sort_values(['group','score'])
5.1.6 分组汇总
公司销售数据分析中,希望按照销售区域找到最高销售量记录,这就涉及分组汇总,即 SQL 中的 group by 语句。分组汇总操作中,会涉及分组变量、度量变量和汇总统计量。Pandas 提供了 groupby 方法进行分组汇总。
示例:
| 变量 | 含义 |
|---|---|
| chinese | 语文 |
| class | 班级 |
| grade | 年级 |
| math | 数学 |
| name | 姓名 |
读取数据
os.chdir(r'F:\Python_book\5Preprocessing')
st_data = pd.read_csv('sample.csv',encoding = 'gbk')
st_data.head(6)
输出结果
Out[408]:
chinese class grade math name
0 88 1 1 98.0 Bob
1 78 1 1 78.0 Lindy
2 86 1 1 87.0 Mark
3 56 2 2 77.0 Miki
4 77 1 2 77.0 Sully
5 54 2 2 NaN Rose
年级(grade)为分组变量,数学成绩(math)为度量变量,现需要查询年级1和年级2数学最高成绩。 groupby 后参数 ‘grade’ 表示数据中的分组变量,max 表示汇总统计量为 max(最大)。
st_data.groupby('grade')[['math']].max()
输出结果
Out[409]:
math
grade
1 98.0
2 77.0
- 分组变量
在进行分组汇总时,分组变量可以有多个,例如,按照 “年级” 、“班级” 顺序对数学成绩查询平均值,此时在 groupby 后接多个分组变量,以列表形式写出。
st_data.groupby(['grade','class'])[['math']].mean()
输出结果
Out[410]:
math
grade class
1 1 87.666667
2 1 77.000000
2 77.000000
- 汇总变量
在进行分组汇总时,汇总变量也可以有多个,例如按照年级汇总数学、语文成绩,汇总统计量均为均值。在 groupby 后直接使用中括号筛选相应列,再接汇总统计量。
st_data.groupby(['grade'])['math','chinese'].mean()
- 汇总统计量
groupby 后可接的汇总统计量如下表
| 统计量 | 含义 | 统计量 | 含义 |
|---|---|---|---|
| mean | 均值 | mad | 平均绝对偏差 |
| max | 最大值 | count | 计数 |
| min | 最小值 | skew | 偏度 |
| median | 中位数 | quantile | 指定分位数 |
| std | 标准差 |
这些统计量方法可以直接接 groupby 对象使用,此外,agg 方法提供了一次汇总多个统计量的方法,例如,汇总各个班级的数学成绩的均值、最大值和最小值。
st_data.groupby('class')['math'].agg(['mean','min','max'])
输出结果
Out[413]:
mean min max
class
1 85.0 77.0 98.0
2 77.0 77.0 77.0
- 多重索引
我们注意到,在进行分组汇总操作时,产生的结果并不是常见的二维表数据框,而是具有多重索引的数据框,这里介绍Pandas数据框的多重索引功能。
df = st_data.groupby(['grade','class'])['math','chinese'].agg(['min','max'])
df
上述以年级、班级对学生的数学、语文成绩进行分组汇总,汇总统计量为均值。此时 df 数据框中有两个行索引和两个列索引。
输出结果
Out[415]:
math chinese
min max min max
grade class
1 1 78.0 98.0 78 88
2 1 77.0 77.0 77 77
2 77.0 77.0 54 56
查询列索引
当需要筛选列时,第一个中括号筛选第一重列索引,第二个中括号代表筛选第二重列索引。
例如查询各个年级、班级的数学成绩的最小值。
df['math']['min']
此外,也可以以 ix 方法查询指定的列,注意多重列索引以“()”方式写出。
输出结果
Out[416]:
grade class
1 1 78.0
2 1 77.0
2 77.0
Name: min, dtype: float64
查询行索引
df.ix[(1,1),('chinese','min')]#78
df.ix[(2,1),('chinese','min')]#77
df.ix[(2,2),('chinese','min')]#54
5.1.7 拆分、堆叠列
- 拆分列
在进行数据处理时,有时要将原数据的指定列按照列的内容拆分为新的列。
上述数据中,原数据的行由标识变量cust_id,分组变量type,值变量Monetary组成,经过拆分后,相当于原先分组变量type中的每个取值成为新列,相应值由原数据值变量Monetary的取值填补。
table = pd.DataFrame({'cust_id':[101,102,103,101,102],
'type':['Normal','Special_offer','Normal','Special_offer','Special_offer'],
'Monetary':[3608,420,1894,3503,4567]})
现需要将type拆分为两列,这里使用pd.pivot_table函数,第一个参数为待拆分的表;index表示原数据中的标示列,也可以称作为横向索引;colnumns表示该变量中的取值将会成为新变量的变量名,在这里就是把type中的值作为列;values表示待拆分的列,也就是把values的列的值进入函数运算(拆分列后默认汇总函数为均值,且缺失值情况NaN填补。
pd.pivot_table(table,index = 'cust_id',columns='type',values='Monetary')
输出结果
Out[425]:
type Normal Special_offer
cust_id
101 3608.0 3503.0
102 NaN 2493.5
103 1894.0 NaN
此外,pd.pivot_table函数提供了fill_value参数和aggfunc函数用于指定拆分列后的缺失值和分组汇总函数。
缺失值填补为0,汇总统计量为求和。
pd.pivot_table(table,index = 'cust_id',columns='type',
values='Monetary',fill_value=0,aggfunc='sum')
- 堆叠列
堆叠列是拆分列的反操作,当存在表示列中有多个数值变量的时候,可以通过堆叠列将多列的数据堆积成一列。
Pandas提供了pd.melt函数用于完成堆叠列
table1 = pd.pivot_table(table,index='cust_id',
columns='type',
values='Monetary',
fill_value=0,
aggfunc=np.sum).reset_index()
table1
输出结果
Out[428]:
type cust_id Normal Special_offer
0 101 3608 3503
1 102 0 4987
2 103 1894 0
对table1进行堆叠列操作,table1代表待堆叠列的列名,id_vars代表标示变量,value_vars代表待堆叠的变量,value_name为堆叠后值变量列的名称,var_name为堆叠后堆叠变量的名称。
table1
pd.melt(table1,
id_vars='cust_id',
value_vars=['Normal','Special_offer'],
value_name='Monetary',
var_name='TYPE')
输出结果
Out[429]:
cust_id TYPE Monetary
0 101 Normal 3608
1 102 Normal 0
2 103 Normal 1894
3 101 Special_offer 3503
4 102 Special_offer 4987
5 103 Special_offer 0
5.18 赋值与条件复制
- 赋值
在一些特定场合,如错误值处理、异常值处理,可能会对原数据的某些值进行修改,此时会涉及类似SQL的insert或update操作。Pandas提供了一些方法能够快速高效地完成赋值操作。
如下数据中,有学生成绩为999分,希望替换为缺失值。
sample = pd.DataFrame({'name':['Bob','Lindy','Mark','Miki','Sully','Rose'],
'score':[99,78,999,77,77,80],
'group':[1,1,1,2,1,2]})
可使用replace方法替换值
sample.score.replace(999,np.nan)
输出结果
Out[431]:
0 99.0
1 78.0
2 NaN
3 77.0
4 77.0
5 80.0
Name: score, dtype: float64
遇到一次替换多个值时,还可以写成字典形式,如下所示,该操作将 sample 数据框中, score 列所有取值为999的值替换为NaN,name 列中取值为 ‘Bob’ 替换为NaN。
sample.replace({'score':{999:np.nan},
'name':{'Bob':np.nan}})
输出结果
Out[432]:
group name score
0 1 NaN 99.0
1 1 Lindy 78.0
2 1 Mark NaN
3 2 Miki 77.0
4 1 Sully 77.0
5 2 Rose 80.0
如Kaggle 共享单车需求量预测中
dataset['season'] = dataset['season'].map({1:'spring',2:'summer',3:'fall',4:'winter'})
dataset['weather'] = dataset['weather'].map({1:'Good',2:'Normal',3:'Bad',4:'Very Bad'})
将量化的季节特征和天气特征转化为字符串描述的数据。
- 条件赋值
一般在修改数据时,都是进行条件查询后再进行赋值。这里以 sample 数据为例
sample
Out[433]:
group name score
0 1 Bob 99
1 1 Lindy 78
2 1 Mark 999
3 2 Miki 77
4 1 Sully 77
5 2 Rose 80
条件赋值可以通过 apply 方法完成,Pandas 提供的 apply 方法可以对一个数据框对象进行行、列的遍历操作,参数 axis 设定0时代表对行class_n循环,axis 设定为1时代表对列循环,且 apply 后接的汇总函数是可以自定义的。
现需要根据 group 列生成新列 class_n:当 group 为1时,class_n 列为 class1,当 group 为2时,class_n列为 class2,使用 apply 如下所示:
def transform(row):
if row['group']==1:
return ('class1')
elif row['group']==2:
return ('class2')
sample.apply(transform,axis=1)
输出结果
Out[436]:
0 class1
1 class1
2 class1
3 class2
4 class1
5 class2
dtype: object
apply 产生 pd.Series 类型的对象,进而可以通过 assign 加入到数据中。
sample.assign(class_n = sample.apply(transform,axis=1))
输出结果
Out[435]:
group name score class_n
0 1 Bob 99 class1
1 1 Lindy 78 class1
2 1 Mark 999 class1
3 2 Miki 77 class2
4 1 Sully 77 class1
5 2 Rose 80 class2
除了apply方法外,还可以通过条件查询直接赋值,如下所示,注意第一句“sample = sample.copy()”最好不要省略,否则可能会产生警告信息。
sample = sample.copy()
sample.loc[sample.group==1,'class_n'] = 'class1'
sample.loc[sample.group==2,'class_n'] = 'class2'
sample
输出结果
Out[440]:
group name score class_n
0 1 Bob 99 class1
1 1 Lindy 78 class1
2 1 Mark 999 class1
3 2 Miki 77 class2
4 1 Sully 77 class1
5 2 Rose 80 class2
如 Kaggle 泰坦尼克号预测乘客的获救情况
Sex 有两个属性:male 和 female,代表男性和女性。为了方便分类器处理,我们可以用1和0代替。
titianic_data['Sex'] = titianic_data['Sex'].apply(lambda x:1 if x == "male" else 0)
5.2 数据清洗
数据清洗是数据分析的必备环节,在进行分析过程中,会有很多不符合分析要求的数据,例如重复、错误、缺失、异常类数据。
5.2.1 重复值处理
Pandas 提供查看、处理重复数据的方法duplicated和drop_duplicate。
示例
sample = pd.DataFrame({'id':[1,1,1,3,4,9],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'score':[99,99,87,77,77,np.nan],
'group':[1,1,1,2,1,2]})
查看重复值
#查看重复值
sample[sample.duplicated()]
输出结果
Out[442]:
group id name score
1 1 1 Bob 99.0
删除重复值
#去重
sample.drop_duplicates()
Out[444]:
group id name score
0 1 1 Bob 99.0
2 1 1 Mark 87.0
3 2 3 Miki 77.0
4 1 4 Sully 77.0
5 2 9 Rose NaN
drop_duplicates 方法还可以按照某列去重,例如去除 id 列重复的所有记录:
sample.drop_duplicates('id')
Out[445]:
group id name score
0 1 1 Bob 99.0
3 2 3 Miki 77.0
4 1 4 Sully 77.0
5 2 9 Rose NaN
5.2.2 缺失值处理
一般地,连续变量可以使用均值或中位数进行填补;分类变量可以使用众数进行填补;如果缺失变量比较重要,一般采用建模方法进行填补,具体使用哪种方法,根据具体案例和业务要求来使用。
示例
sample = pd.DataFrame({'id':[1,1,1,3,4,np.nan],
'name':['Bob','Bob','Mark','Miki','Sully',np.nan],
'score':[99,np.nan,87,77,76,np.nan],
'group':[1,1,np.nan,2,1,np.nan]})
sample
输出结果
Out[447]:
group id name score
0 1.0 1.0 Bob 99.0
1 1.0 1.0 Bob NaN
2 NaN 1.0 Mark 87.0
3 2.0 3.0 Miki 77.0
4 1.0 4.0 Sully 76.0
5 NaN NaN NaN NaN
- 查看缺失情况
在进行数据分析钱,一般需要了解数据的缺失情况,在 Python 中可以构造一个 lambda 函数来查看缺失值, lambda函数中,sum(col.isnull()) 表示当前列有多少缺失,col.size 表示当前列总共有多少行数据。
sample.apply(lambda col:sum(col.isnull())/col.size)
输出结果
Out[449]:
group 0.333333
id 0.166667
name 0.166667
score 0.333333
dtype: float64
- 指定值填补
Pandas 数据框提供了 fillna 方法完成对缺失值的填补,例如对sample表的列score填补缺失值,填补方法为均值。
sample.score.fillna(sample.score.mean())
#中位数
#sample.score.fillna(sample.score.median())
- 缺失值指示变量
Pandas 数据框对象可以直接调用方法isnull产生缺失值指示变量,例如产生score变量的缺失值指示变量。
若想转换为数值0、1型指示变量,可以使用apply方法,int表示将该列替换为int类型。
sample.score.isnull()
#sample.score.isnull().apply(int)
输出结果
Out[453]:
0 False
1 True
2 False
3 False
4 False
5 True
Name: score, dtype: bool
5.2.3 噪声值处理
噪声值是指数据中有一个或几个数值与其他数值相比差异较大的值,又称为异常值、离群值。
一般异常值的检测方法有基于统计的方法、基于聚类的方法,以及一些专门检测异常值的方法等。
- 简单统计
如果使用Pandas,我们可以直接使用describe()来观察数据的统计性描述(只是粗略的观察一些统计量),不过统计数据为连续型。如学生成绩的最大值为999,这也可以直接判断为异常值。

或者使用散点图也能很清晰地观察到异常值的存在

- 拉依达准则
这个准则有个条件:数据需要服从正态分布。异常值如超过3倍标准差,那么可以将其视为异常值。
正负3 σ \sigma σ的概率为99.7%,那么距离平均值3 σ \sigma σ之外的值出现的概率为
P ( ∣ x − u ∣ > 3 σ ) ≤ 0.003 P(|x-u|>3\sigma)\leq0.003 P(∣x−u∣>3σ)≤0.003
属于极小个别的小概率事件,如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
- 箱线图
这种方法是利用箱线图的**四分位距(IQR)**对异常值进行检测。
四分位距(IQR)就是上四分位距与下四分位距的差值。我们通过IQR的1.5倍为标准,规定:小于下四分位距-1.5IQR距离,或者大于上四分位距+1.5IQR距离 的点为异常值。
使用numpy的percentile方法
Percentile = np.percentile(df['length'],[0,25,50,75,100])
IQR = Percentile[3]-Percentile[1]
Uplimit = Percentile[3]+IQR*1.5
Downlimit = Percentile[1]-IQR*1.5
也可以使用seaborn的可视化方法boxplot来实现

红色箭头所指就是异常值。
还有很多方法,这里给出链接,感兴趣的读者可以自行学习。
【Python数据分析基础】: 异常值检测和处理
5.3 RFM方法在客户行为分析上的运用
5.3.1 行为特征提取的RFM方法论
根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有3个重要指标,分布如下:
- 最近一次消费(Recency)
最近一次消费指的是客户上一次购买的时间。上一次消费时间越近的客户,对提供即使的商品或服务也最有可能有所反应。
- 消费频率(Frequency)
消费频率是客户在限定的期间内所购买的次数。最常购买的客户,也是满意度最高的客户。这个指标是“忠诚度”很好的代理变量。
- 消费金额(Monetary)
消费金额是最近消费的平均金额,是体现客户短期价值的重要变量。
5.3.2 使用RFM方法计算变量
RFM_TRAD_FLOW为某一段时间内某零售商客户的消费记录
| 名称 | 类型 | 标签 |
|---|---|---|
| transID | 数值 | 记录ID |
| cumid | 数值 | 客户编号 |
| time | 日期 | 收银时间 |
| amount | 数值 | 销售金额 |
| type_lable | 字符 | 销售类型:特价、退货、赠送、正常 |
| type | 字符 | 销售类型,同上,显示为英文:Special_offer、returned_goods、Presented、Normal |
读取数据
rfm_traindata = pd.read_csv('RFM_TRAD_FLOW.csv',encoding = 'gbk')
rfm_traindata.head()
输出结果
Out[456]:
transID cumid time amount type_label type
0 9407 10001 14JUN09:17:58:34 199.0 正常 Normal
1 9625 10001 16JUN09:15:09:13 369.0 正常 Normal
2 11837 10001 01JUL09:14:50:36 369.0 正常 Normal
3 26629 10001 14DEC09:18:05:32 359.0 正常 Normal
4 30850 10001 12APR10:13:02:20 399.0 正常 Normal
分析客户对不同品类的购物金额,这需要按照客户ID和购物类别,对购物金额进行计算购物总花费金额。
M = rfm_traindata.groupby(['cumid','type'])[['amount']].sum()
M.head(7)
输出结果
Out[460]:
amount
cumid type
10001 Normal 3608.0
Presented 0.0
Special_offer 420.0
returned_goods -694.0
10002 Normal 1894.0
Presented 0.0
returned_goods -242.0
按照cumid分组,对amount变量进行拆分,拆分后的变量名由type的不同取值提供。
M_trans = pd.pivot_table(M,index='cumid',columns='type',values='amount')
M_trans.head(7)
输出结果
Out[462]:
type Normal Presented Special_offer returned_goods
cumid
10001 3608.0 0.0 420.0 -694.0
10002 1894.0 0.0 NaN -242.0
10003 3503.0 0.0 156.0 -224.0
10004 2979.0 0.0 373.0 -40.0
10005 2368.0 0.0 NaN -249.0
10006 2534.0 0.0 58.0 -733.0
10007 4021.0 0.0 179.0 -239.0
用户的购买频次和最近一次消费R的计算方法,按照用户分组后分别汇总任意变量的频次以及time变量的最大值。
#RFM的F
f= rfm_traindata.groupby(['cumid','type'])[['amount']].count()
f.head(7)
f_trans = pd.pivot_table(f,index='cumid',columns='type',values='amount')
f_trans.head(7)
##RFM的R
import time
# 先将非标准字符串时间格式化为时间数组,再转换为时间戳便于计算
rfm_traindata['time'] = rfm_traindata['time'].map(lambda x: time.mktime(time.strptime(x, '%d%b%y:%H:%M:%S')))
# 查找每个购物ID每个销售类型下的最近时间
R= rfm_traindata.groupby(['cumid','type'])[['time']].max()
R.head(7)
# 转化为透视表
R_trans = pd.pivot_table(R,index='cumid',columns='type',values='time')
R_trans.head(7)
5.3.3 数据整理与汇报
我们希望计算特价商品购买比例这样一个指标,该比例越高,说明这个客户对打折商品越感兴趣。但是不能直接计算,因为 Special_offer 有大量的缺失值,这是因为有很多客户从未购买过打折商品,因此该变量的缺失值需要用“0”替换。
M_trans ['Special_offer'] = M_trans['Special_offer'].fillna(0)
最后一步:计算购买特价商品的比例,并按照该比例降序排序。
M_trans ['Spe_ratio'] = M_trans ['Special_offer'] / (M_trans ['Special_offer'] + M_trans ['Normal'] )
M_trans.sort_values('Spe_ratio',ascending = False,na_position = 'last').head()
输出结果
Out[482]:
type Normal Presented Special_offer returned_goods Spe_ratio
cumid
10151 765.0 0.0 870.0 NaN 0.532110
40033 1206.0 0.0 761.0 -848.0 0.386884
40236 1155.0 0.0 691.0 -793.0 0.374323
30225 1475.0 0.0 738.0 -301.0 0.333484
20068 1631.0 0.0 731.0 -239.0 0.309483
排在最前面的就是对打折商品偏好最高的客户,从上至下依次递减,基于以上分析,为了提升打折促销的效果,只要按照上面的计算结果由上至下筛选客户,并选定对打折偏好较高的部分用户进行定向营销。
参考资料
- 常国珍,赵仁乾,张秋剑.《Python数据科学:技术详解与商业实战》,北京:机械出版社,2018.7.
- 中国大学MOOC:南京大学.张莉.《用Python玩转数据》
- 【Python数据分析基础】: 异常值检测和处理