HBase笔记(四)-数据读取过程(二)
简单地回顾一下scan的整个流程,如下图所示: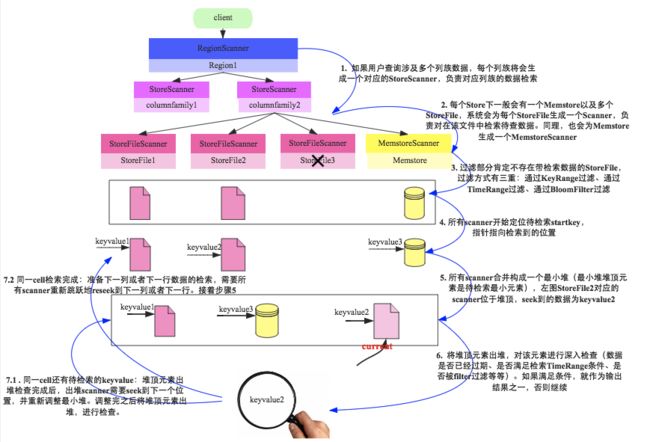
上图是一个简单的示意图,本文将会关注于隐藏在这个示意图中的核心细节,这里笔者挑出了其中几个比较重要的问题来说明。
1. 常说HBase数据读取要读Memstore、HFile和Blockcache,为什么上面Scanner只有StoreFileScanner和MemstoreScanner两种?没有BlockcacheScanner?
HBase中数据仅仅独立地存在于Memstore和StoreFile中,Blockcache中的数据只是StoreFile中的部分数据(热点数据),即所有存在于Blockcache的数据必然存在于StoreFile中。因此MemstoreScanner和StoreFileScanner就可以覆盖到所有数据。实际读取时StoreFileScanner通过索引定位到待查找key所在的block之后,首先检查该block是否存在于Blockcache中,如果存在直接取出,如果不存在再到对应的StoreFile中读取。
2. 数据更新操作先将数据写入Memstore,再落盘。落盘之后需不需要更新Blockcache中对应的kv?如果不更新,会不会读到脏数据?
如果理清楚了第一个问题,相信很容易得出这个答案:不需要更新Blockcache中对应的kv,而且不会读到脏数据。数据写入Memstore落盘会形成新的文件,和Blockcache里面的数据是相互独立的,以多版本的方式存在。
3. 读取流程中如何使用BloomFilter(简称BF)对StoreFile进行过滤?
过滤StoreFile发生在上图中第三步,过滤手段主要有三种:根据KeyRange过滤、根据TimeRange过滤、根据BF过滤。下面分别进行介绍:
(1)根据KeyRange过滤:因为StoreFile是中所有KV数据都是有序排列的,所以如果待检索row范围[startrow,stoprow]与文件起始key范围[firstkey,lastkey]没有交集,比如stoprow < firstkey 或者 startrow > lastkey,就可以过滤掉该StoreFile。
(2)根据TimeRange过滤:StoreFile中元数据有一个关于该File的TimeRange属性[minimumTimestamp, maxmumTimestamp],因此待检索的TimeRange如果与该文件时间范围没有交集,就可以过滤掉该StoreFile;另外,如果该文件所有数据已经过期,也可以过滤淘汰。
(3)根据BF过滤:BF在几乎所有的LSM模型存储领域都会用到,可说是标配,比如HBase、Kudu、RocksDB等等,用法也是如出一辙,和HBase一样,主要用来读取数据时过滤部分文件;除此之外,BF在大数据计算(分布式Join实现)中也扮演重要的角色。
现在来看看HBase中如何利用BF对StoreFile进行过滤(注:接下来所有关于HBase BF的说明都按照Row类型来,Row-Column类型类似),原理其实很简单:首先把BF数据加载到内存;然后使用hash函数对待检索row进行hash,根据hash后的结果在BF数据中进行寻址查看即可确定是否存在该HFile。第二步就是BF的原理,并没有什么好讲的,主要来看看HBase是如何将BF数据加载到内存的。
看过笔者之前文章的童鞋都知道,BF数据实际上是和用户KV数据一样存储在HFile中的,那就需要先看看BF信息是如何存储在HFile中的,查看官方文档中HFile(v2)组织结构图如下: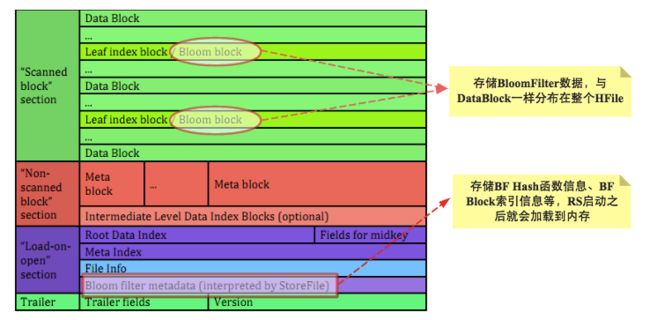
HFile组织结构中关于BF有两个非常重要的结构-Bloom Block与Bloom Index。Bloom Block主要存储BF的实际数据,可能这会大家要问为什么Bloom Block要分布在整个HFile?分布的具体位置如何确定?其实很简单,HBase在写数据的时候就会根据row生成对应的BF信息并写到一个Block中,随着用户数据的不断写入,这个BF Block就会不断增大,当增大到一定阈值之后系统就会重新生成一个新Block,旧Block就会顺序加载到Data Block之后。这里隐含了一个关键的信息,随着单个文件的增大,BF信息会逐渐变的很大,并不适合一次性全部加载到内存,更适合的使用方式是使用哪块加载哪块!
这些Bloom Block分散在HFile中的各个角落,就会带来一个问题:如何有效快速定位到这些BF Block?这就是Bloom Index的核心作用,与Data Index相同,Bloom Index也是一颗B+树,Bloom Index Block结构如下图所示: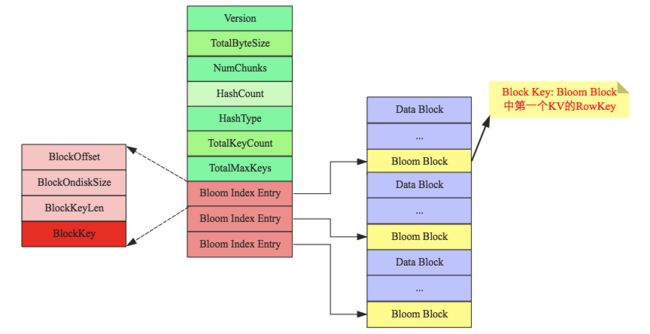
上图需要重点关注Bloom Block的Block Key:Block中第一个原始KV的RowKey。这样给定一个待检索的 rowkey,就可以很容易地通过Bloom Index定位到具体的Bloom Block,将Block加载到内存进行过滤。通常情况下,热点Bloom Block会常驻内存的!
到此为止,笔者已经解释清楚了HBase是如何利用BF在读取数据时根据rowkey过滤StoreFile的,相信Kudu、RocksDB中BF的原理基本相同。
再回到出发的地方,我们说在实际scan之前就要使用BF对StoreFile进行过滤,那仔细想下,到底用哪个rowkey过滤?实际实现中系统使用scan的startrow作为过滤条件进行过滤,这是不是有问题?举个简单的例子,假设小明检索的数据为[row1, row4],如果此文件不包含row1,而包含row2,这样在scan前你利用row1就把该文件淘汰掉了,row2这条数据怎么办?不是会被遗漏?
这里系统实现有个隐藏点,scan之前使用BF进行过滤只针对get查询以及scan单条数据的场景,scan多条数据并不会执行实际的BF过滤,而是在实际seek到新一行的时候才会启用BF根据新一行rowkey对所有StoreFile过滤。
4. 最小堆中弹出cell之后如何对该cell进行检查过滤,确保满足用户设置条件?检查过滤之后是继续弹出下一个cell,还是跳过部分cell重新seek到下一列或者下一行?
scan之所以复杂,很大程度上是因为scan可以设置的条件非常之多,下面所示代码为比较常规的一些设置:
Scan scan = new Scan();
scan.withStartRow(startRow) //设置检索起始row
.withStopRow(stopRow) //设置检索结束row
.setFamilyMap(Map familyMap>) //设置检索的列族和对应列族下的列集合
.setTimeRange(minStamp, maxStamp) // 设置检索TimeRange
.setMaxVersions(maxVersions) //设置检索的最大版本号
.setFilter(filter) //设置检索过滤器
… 在整个Scan流程的第6步,将堆顶kv元素出堆进行检查,实际上主要检查两个方面,其一是非用户条件检查,比如kv是否已经过期(列族设置TTL)、kv是否已经被删除,这些检查和用户设置查询条件没有任何关系;其二就是检查该kv是否满足用户设置的这些查询条件,代码逻辑还是比较清晰的,在此不再赘述。核心代码主要参考ScanQueryMatcher.match(cell)方法。
相比堆顶元素检查流程,笔者更想探讨堆顶元素kv检查之后的返回值-MatchCode,这个Code可不简单,它会告诉scanner是继续seek下一个cell,还是直接跳过部分cell直接seek到下一列(对应INCLUDE_AND_SEEK_NEXT_COL或SEEK_NEXT_COL),抑或是直接seek到下一行(对应INCLUDE_AND_SEEK_NEXT_ROW或SEEK_NEXT_ROW)。还是举一个简单的例子:
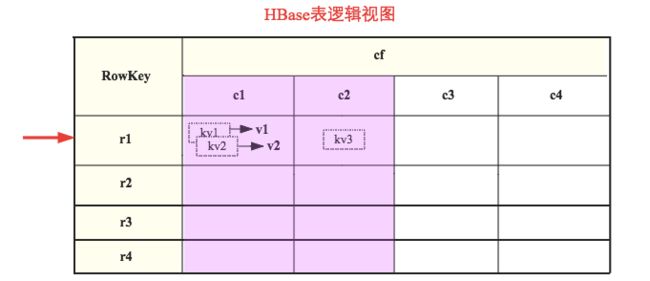
上图是待查表,含有一个列族cf,列族下有四个列[c1, c2, c3, c4],列族设置MaxVersions为2,即允许最多存在2个版本。现在简单构造一个查询语句如下:
Scan scan = new Scan(r1, r4); // 表示检索范围为[r1, r4]
scan.setFamilyMap(Map>) //仅检索列族cf下的c1列和c2列
.setMaxVersions(1) //设置检索的最大版本号为1 下面分别模拟直接跳过部分纪录seek到下一列(INCLUDE_AND_SEEK_NEXT_COL)的场景以及跳过部分列直接seek到下一行(INCLUDE_AND_SEEK_NEXT_ROW)的场景:
(1)假设当前检索r1行,堆顶元素为cf:c1下的kv1(版本为v1),按照设置条件中检索的最大版本号为1,其他条件都满足的情况下就可以直接跳过kv2直接seek到下一列-c2列。这种场景下就会返回INCLUDE_AND_SEEK_NEXT_COL。
(2)假设当前检索r1行,堆顶元素为cf:c2下的kv3(仅有1个版本),满足设置的版本条件,系统检测到c2是检索的最后一列之后(c3、c4并不需要检索),就会返回指示-略过c3、c4直接seek到下一行。这种场景下就会返回INCLUDE_AND_SEEK_NEXT_ROW。