Jigsaw Unintended Bias in Toxicity Classification竞赛bilstm+glove embedding解法
0.写在前面
0.1本文配套github:
https://github.com/willinseu/kaggle-Jigsaw-Unintended-Bias-in-Toxicity-Classification-solution
如果你觉得本文对你有帮助,或者有提高,请点一个star以表支持,感谢~
同时与上一篇博文的github项目是对接的:
https://github.com/willinseu/kesci-urdu-sentiment-analysis
0.2 数据集
数据:
https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data
0.3一些说明
本文要求你具有神经网络,pandas,keras的基础知识。
如果你是一个nlp基础较为薄弱的人,建议先看本文的兄弟篇:
用lstm实现nlp情感分析(roman urdu小语种为例)代码+原理详解,再看本篇(提高篇)
不然会对tokenizer等用法很陌生,而且对整体的nlp思路也会不清晰。
如果你基础扎实,对于各种nlp手法都很熟悉,建议直接去kaggle比赛页阅读相关内容,本文仅是为了帮助一些初学者。
0.4文章截图说明
文中会出现多处jupyter代码截图。截图均来自我的github。如需要请前往文中开头的链接。
0.5 关于原代码
代码大部分来自:https://www.kaggle.com/thousandvoices/simple-lstm?scriptVersionId=12556909
但是其实对于初学者而言,原代码很难看懂,所以这就是我写这篇博客的目的。
并且github中用notebook写了下注释。
1.赛题分析
比赛呢,简单说来还是一个情感分析的二分类问题。但说复杂点了,就是一个多输出的二分类问题。
我们先看一眼这个数据集,再做讨论。
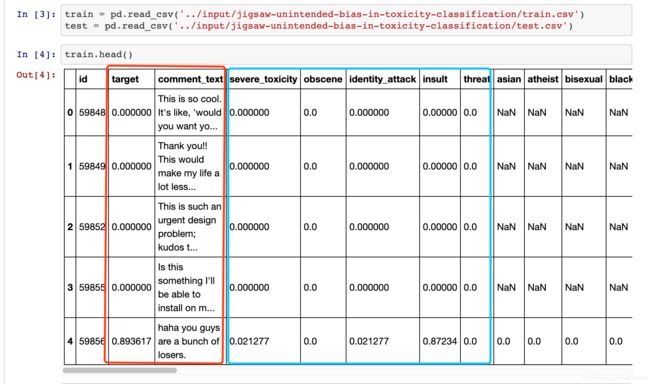
我们这里默认target>0.5的为1,<0.5的为0,这样问题就是一个二分类问题了。
我们在上一篇博文中见到的只有图中的红框。意思很简单,给你一句话,那你就要给我它的输出是0还是1,经典的情感分析问题。
当然了,对于本数据集,你也完全可以忽略掉全部,只看红框,然后搭建网络做判别,我在我的github上也实现了这种初级解法,auc可以达到0.9左右。
1.1只关注红框与关注红+蓝的区别到底是什么?
这其实是一个很重要的问题!!!但是经常有人会说:这不显而易见吗?你用到的数据多了,模型肯定好。feature越多越好木问题的~
请思考的更深入一些。Think Deep.
下面开始我们的分析:
我们可以很明显的发现,你只关注红框,那么数据集你没有完全利用到,蓝框的数据你都没用到。说专业点,你的网络只关注到了1或者0,或者说你只告诉了它是不是toxic,那他的表现自然不能太好。但是如果你告诉网络,这句话的toxic程度为0.8,insult(辱骂)程度为0.7,…那么这句话就真正被网络fit进去了。
或者换句话说,一句话toxic程度是0.6,另一句是0.9,而我们都认为是1。那么其中的差异性就被我们丢失了,所以关于在这一个二分类问题中关注这些连续型变量就是这个目的。所以我们需要把float形式的target加进去。剩下的feature加进去也是一个道理。
所以我们的问题是一个多输出问题,训练集的构造也应该是这样:
x_train = preprocess(train['comment_text'])
y_train = np.where(train['target'] >= 0.5, 1, 0)
y_aux_train = train[['target', 'severe_toxicity', 'obscene', 'identity_attack', 'insult', 'threat']]
x_test = preprocess(test['comment_text'])

1.2代码思路说明
一、预处理阶段
- 文本预处理,去除特殊符号等
- 利用glove/fasttext 进行数据的编码,生成权重矩阵
二、模型构建以及训练
2.文本预处理
在本代码中,我们只进行了简单的处理:
def preprocess(data):
'''
Credit goes to https://www.kaggle.com/gpreda/jigsaw-fast-compact-solution
'''
punct = "/-'?!.,#$%\'()*+-/:;<=>@[\\]^_`{|}~`" + '""“”’' + '∞θ÷α•à−β∅³π‘₹´°£€\×™√²—–&'
def clean_special_chars(text, punct):
for p in punct:
text = text.replace(p, ' ')
return text
data = data.astype(str).apply(lambda x: clean_special_chars(x, punct))
return data
可以看到仅仅是去除了一些字符而已。我不打算对这个函数多讲,因为不复杂,而且不是本文重点。
如果想看到一些稍微复杂的预处理,我做了一些,在我的github的V1-fundamental中。
https://github.com/willinseu/kaggle-Jigsaw-Unintended-Bias-in-Toxicity-Classification-solution/blob/master/v1-fundamental.ipynb
3.如何使用glove生成权重矩阵。
对应代码:
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
def build_matrix(word_index, path):
embedding_index = load_embeddings(path)
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
try:
embedding_matrix[i] = embedding_index[word]
except KeyError:
pass
return embedding_matrix
我这里的权重矩阵指的是:
x = Embedding(*embedding_matrix.shape, weights=[embedding_matrix], trainable=False)(words)
中出现的embedding_matrix。
关于本小节内容,同样为了使本文不过于臃肿,我写在了:
如何使用glove,fasttext等词库进行word embedding?(原理篇)
如何使用glove,fasttext等词库进行word embedding?(代码篇)
使用的数据集正是本比赛的数据,所以不用担心不对应的问题。
4模型构建⭐️
这是本文旨在重点写的地方。
首先,看一下模型构建的代码:
def build_model(embedding_matrix, num_aux_targets):
words = Input(shape=(MAX_LEN,))
x = Embedding(*embedding_matrix.shape, weights=[embedding_matrix], trainable=False)(words)
x = SpatialDropout1D(0.3)(x)
x = Bidirectional(CuDNNLSTM(LSTM_UNITS, return_sequences=True))(x)
x = Bidirectional(CuDNNLSTM(LSTM_UNITS, return_sequences=True))(x)
hidden = concatenate([
GlobalMaxPooling1D()(x),
GlobalAveragePooling1D()(x),
])
hidden = add([hidden, Dense(DENSE_HIDDEN_UNITS, activation='relu')(hidden)])
hidden = add([hidden, Dense(DENSE_HIDDEN_UNITS, activation='relu')(hidden)])
result = Dense(1, activation='sigmoid')(hidden)
aux_result = Dense(num_aux_targets, activation='sigmoid')(hidden)
model = Model(inputs=words, outputs=[result, aux_result])
print(model.summary())
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
用了一个函数封装模型,确实是很值得借鉴的方法。
我们一点点分析:
首先,模型接受到的是输入数据是(None,220)的数据,其中220是填充长度。之后喂进去Embedding层,是一个什么操作过程呢?其实这些我在上一篇nlp博文说过,首先会做一个onehot的变化,变成(None,220,100000)。
其中100000在此处提及过:

它代表我们认为的不同的单词数。之后,我们的权重矩阵形状是(100000,300)的形状的。为什么?请看第三节。
二者相乘,所以Embedding层的输出是(None,220,300)。下面是一个Dropout操作,也是为了让每一个epoch喂进去的数据都稍有差异,或者你可以通俗的理解成防止过拟合。不过这里用的是SpatialDropout1D。这是个啥?
同样,我另开了一篇博客说它,参见:神经网络高阶技巧4–关于SpatialDropout1D
现在你可以理解成特殊形式的dropout,并且请牢记此dropout多用在Embedding后。这层输出肯定仍是(None,220,300),只不过会有一些维度会被置0。形状不会改变的。
之后是双层的bilstm
x = Bidirectional(CuDNNLSTM(LSTM_UNITS, return_sequences=True))(x)
x = Bidirectional(CuDNNLSTM(LSTM_UNITS, return_sequences=True))(x)
hidden = concatenate([
GlobalMaxPooling1D()(x),
GlobalAveragePooling1D()(x),
])
hidden = add([hidden, Dense(DENSE_HIDDEN_UNITS, activation='relu')(hidden)])
hidden = add([hidden, Dense(DENSE_HIDDEN_UNITS, activation='relu')(hidden)])
其中的一些难以琢磨的点我也都写在了别的博文中
关于什么是CuDNNLSTM,参见:神经网络高阶技巧2–采用CuDNNLSTM,别再用LSTM了!
关于lstm的参数return_sequences=True,参见本博客开头提到了兄弟篇章。
关于add与concatenate,参见:
神经网络高阶技巧3–对层操作之add与concatenate以及keras的summary中[0][0]的解释
关于 GlobalMaxPooling1D()(x),
GlobalAveragePooling1D()(x),我写在了:
神经网络高阶技巧5–关于GolbalAveragePooling与GlobalMaxPooling
所以说。。。想把一篇代码讲明白,真不是一件简单的事。。。
你把一系列再穿起来,就不难理解了。
由于代码中有一句话:
embedding_matrix = np.concatenate(
[build_matrix(tokenizer.word_index, f) for f in EMBEDDING_FILES], axis=-1)
就是同时利用了glove/fasttext两个300维的矩阵,合并成了600.所以下面出现的数字和我刚才说的不同,不是300,而是600.
模型长这样:
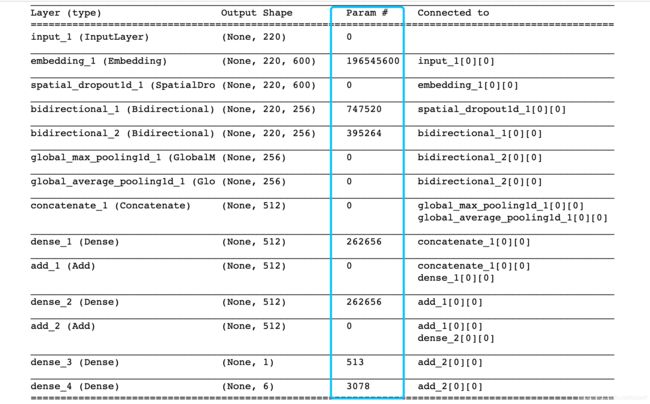

5.参数个数详解
为什么Embedding层参数是那么多?
Sorry.这里我之前写错了一点,
这个变量虽然定义了但是没有用。但是本质没变
所以这里的权重矩阵是(327576,600)。327576*600=196545600。327576是整个数据集不同的词的个数。 但是这是不可训练的参数,因为这个矩阵我们提前导入进去了。或者说训练好了。
剩余参数计算请参照我开头提到的兄弟博客。
6模型训练及预测⭐️
checkpoint_predictions = []
weights = []
for model_idx in range(NUM_MODELS):
model = build_model(embedding_matrix, y_aux_train.shape[-1])
for global_epoch in range(EPOCHS):
model.fit(
x_train,
[y_train, y_aux_train],
batch_size=BATCH_SIZE,
epochs=1,
verbose=2,
callbacks=[
LearningRateScheduler(lambda epoch: 1e-3 * (0.6 ** global_epoch))
]
)
checkpoint_predictions.append(model.predict(x_test, batch_size=2048)[0].flatten())
weights.append(2 ** global_epoch)
predictions = np.average(checkpoint_predictions, weights=weights, axis=0)
关于其中的LearningRateScheduler,请参见:
神经网络高阶技巧1–Learning Rate Scheduler
至于其中的权重与学习率,其实不难理解。
权重为2的0次方,1次方。。。。。
也就是[1,2,4,8,1,2,4,8]以此作为8个epoch输出的权重。
然后每个epoch的学习率,参见刚才的链接。
总结下,就是每个epoch的预测输出都会被存储在checkpoint_predictions里。然后每个epoch的输出都有一个权重,显然随着epoch的增大,权重要增大。所以是1,2,4,8的增序。
至于为什么要循环两遍,仅仅是为了获得更加鲁棒的输出而已,在这两遍的循环中,执行内容是一样的。