HBase_HBase2.0+ Java API 操作指南 (三) 扫描器Scan
Hbase 取数据通过 Get 方法去取数据还是效率太低了。这里我们学习下如何获取一批数据。
这里我们首先学习下Scan ,Scan 是基础,在Scan中可以设置过滤器 Filter。
扫描器
扫描技术。这种技术类似于数据库系统中的游标(cursor), 并利用到了HBase 提供的底层顺序存储的数据结构。
扫描操作的工作方式类似于迭代器,用户无需调用scan() 方法创建实例。只需要调用 Table 的 getScanner() 方法,此方法返回真正的扫描器(scanner)实例的同时,用户也可以使用它迭代获取数据。
注意:要确保尽早始放扫描器实例,一个打开的扫描器会占用不少服务器资源,累计多了会占用大量的堆空间。当使用完 ResultScanner 之后应调用 它的 (Scan) close 方法,同时应该把 close 方法放到 try / finally 块中,以保证其在迭代获取数据过程中出现异常和错误时,仍能执行 close。
Table getScanner 方法
/**
* Returns a scanner on the current table as specified by the {@link Scan}
* object.
* Note that the passed {@link Scan}'s start row and caching properties
* maybe changed.
*
* @param scan A configured {@link Scan} object.
* @return A scanner.
* @throws IOException if a remote or network exception occurs.
* @since 0.20.0
*/
ResultScanner getScanner(Scan scan) throws IOException;
/**
* Gets a scanner on the current table for the given family.
*
* @param family The column family to scan.
* @return A scanner.
* @throws IOException if a remote or network exception occurs.
* @since 0.20.0
*/
ResultScanner getScanner(byte[] family) throws IOException;
/**
* Gets a scanner on the current table for the given family and qualifier.
*
* @param family The column family to scan.
* @param qualifier The column qualifier to scan.
* @return A scanner.
* @throws IOException if a remote or network exception occurs.
* @since 0.20.0
*/
ResultScanner getScanner(byte[] family, byte[] qualifier) throws IOException;
Scan 的构造器
/**
* Create a Scan operation across all rows.
*/
public Scan() {}
/**
* @deprecated use {@code new Scan().withStartRow(startRow).setFilter(filter)} instead.
*/
@Deprecated
public Scan(byte[] startRow, Filter filter) {
this(startRow);
this.filter = filter;
}
/**
* Create a Scan operation starting at the specified row.
*
* If the specified row does not exist, the Scanner will start from the next closest row after the
* specified row.
* @param startRow row to start scanner at or after
* @deprecated use {@code new Scan().withStartRow(startRow)} instead.
*/
@Deprecated
public Scan(byte[] startRow) {
setStartRow(startRow);
}
/**
* Create a Scan operation for the range of rows specified.
* @param startRow row to start scanner at or after (inclusive)
* @param stopRow row to stop scanner before (exclusive)
* @deprecated use {@code new Scan().withStartRow(startRow).withStopRow(stopRow)} instead.
*/
@Deprecated
public Scan(byte[] startRow, byte[] stopRow) {
setStartRow(startRow);
setStopRow(stopRow);
}
//拷贝模式
public Scan(Scan scan) throws IOException {
startRow = scan.getStartRow();
includeStartRow = scan.includeStartRow();
stopRow = scan.getStopRow();
includeStopRow = scan.includeStopRow();
maxVersions = scan.getMaxVersions();
batch = scan.getBatch();
storeLimit = scan.getMaxResultsPerColumnFamily();
storeOffset = scan.getRowOffsetPerColumnFamily();
caching = scan.getCaching();
maxResultSize = scan.getMaxResultSize();
cacheBlocks = scan.getCacheBlocks();
filter = scan.getFilter(); // clone?
loadColumnFamiliesOnDemand = scan.getLoadColumnFamiliesOnDemandValue();
consistency = scan.getConsistency();
this.setIsolationLevel(scan.getIsolationLevel());
reversed = scan.isReversed();
asyncPrefetch = scan.isAsyncPrefetch();
small = scan.isSmall();
allowPartialResults = scan.getAllowPartialResults();
tr = scan.getTimeRange(); // TimeRange is immutable
Map> fams = scan.getFamilyMap();
for (Map.Entry> entry : fams.entrySet()) {
byte [] fam = entry.getKey();
NavigableSet cols = entry.getValue();
if (cols != null && cols.size() > 0) {
for (byte[] col : cols) {
addColumn(fam, col);
}
} else {
addFamily(fam);
}
}
for (Map.Entry attr : scan.getAttributesMap().entrySet()) {
setAttribute(attr.getKey(), attr.getValue());
}
for (Map.Entry entry : scan.getColumnFamilyTimeRange().entrySet()) {
TimeRange tr = entry.getValue();
setColumnFamilyTimeRange(entry.getKey(), tr.getMin(), tr.getMax());
}
this.mvccReadPoint = scan.getMvccReadPoint();
this.limit = scan.getLimit();
this.needCursorResult = scan.isNeedCursorResult();
setPriority(scan.getPriority());
}
Scan返回值 ResultScanner类
扫描操作不会通过一次RPC请求返回所有匹配的行,而是以行为单位进行返回。ResultScanner 把扫描器转换为类似的get 操作,它将每一行数据封装成一个Result实例,并将所有的Result 实例放入一个迭代器中。
Result next() throws IOException
Result[] next(int nbRows) throws IOException
void close()
Scan 的优化点
扫描器缓存:
resultScanner的每一次 next 调用都会为每行数据生成一个单独的RPC请求。即使使用next(int nbRows)方法,该方法仅仅是在客户端循环地调用next()方法。
因此可以利用扫描器缓存,让一次RPC请求获取多行数据。(默认不开启)
相关设置
void setScannerCaching(int scannerCaching)
int getScannerCaching()
批量参数
缓存是面向行一级的操作,而批量则是面向列一级的操作。批量可以让用户选择每一次 ResultScanner 实例的 next() 操作要去会取回多少列。
/**
* Set the maximum number of cells to return for each call to next(). Callers should be aware
* that this is not equivalent to calling {@link #setAllowPartialResults(boolean)}.
* If you don't allow partial results, the number of cells in each Result must equal to your
* batch setting unless it is the last Result for current row. So this method is helpful in paging
* queries. If you just want to prevent OOM at client, use setAllowPartialResults(true) is better.
* @param batch the maximum number of values
* @see Result#mayHaveMoreCellsInRow()
*/
public Scan setBatch(int batch) {
if (this.hasFilter() && this.filter.hasFilterRow()) {
throw new IncompatibleFilterException(
"Cannot set batch on a scan using a filter" +
" that returns true for filter.hasFilterRow");
}
this.batch = batch;
return this;
}
当用户想尽量提高和利用系统性能时,需要为这两个参数选择一个合适的组合。
只有当用户使用批量模式后,行内(intra-row)扫描功能才会启用。
两个参数共同作用
示例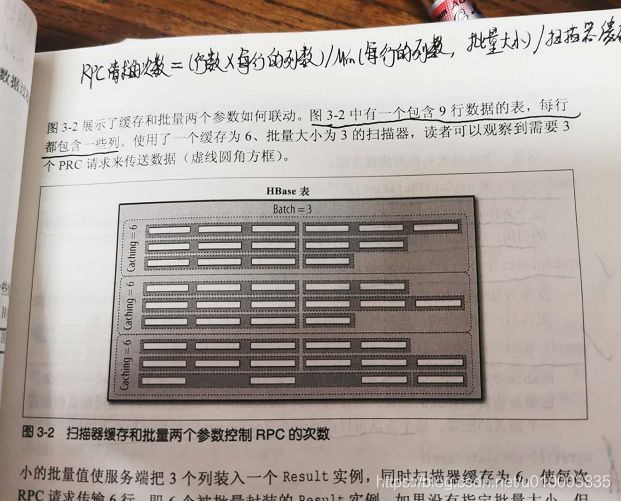
数据样例
hbase(main):006:0> scan 'test3',{VERSIONS=>3}
ROW COLUMN+CELL
ce_shi1 column=author:name, timestamp=1587558488841, value=zhouyuqin
ce_shi1 column=author:name, timestamp=1587402132957, value=nicholas
ce_shi1 column=author:name, timestamp=1587402040153, value=nicholas
ce_shi1 column=author:nickname, timestamp=1587402040153, value=lee
ce_shi2 column=author:name, timestamp=1587402132957, value=spark
ce_shi2 column=author:name, timestamp=1587402040153, value=spark
ce_shi2 column=author:nickname, timestamp=1587402132957, value=hadoop
ce_shi2 column=author:nickname, timestamp=1587402040153, value=hadoop
ce_shi3 column=author:age, timestamp=1587558488841, value=12
ce_shi3 column=author:name, timestamp=1587558488841, value=sunzhenhua
test33 column=author:name, timestamp=1587402133000, value=sunzhenhua
test33 column=author:name, timestamp=1587402040188, value=sunzhenhua
test33 column=author:name, timestamp=1587400015581, value=sunzhenhua
4 row(s)
Took 0.0846 seconds
代码:
package hbase_2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
/**
* Created by szh on 2020/4/22.
* @author szh
*/
public class Hbase_BasicScan {
public static void main(String[] args) throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "cdh-manager,cdh-node1,cdh-node2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
Connection conn = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("test3");
Table table = conn.getTable(tableName);
//设置客户端缓存大小
Scan scan = new Scan();
scan.setMaxVersions(3);
ResultScanner scanner = table.getScanner(scan);
for(Result res : scanner){
System.out.println(res);
}
scanner.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
//TimeRange 默认只返回一个版本
// * Get versions of columns only within the specified timestamp range,
// * [minStamp, maxStamp). Note, default maximum versions to return is 1. If
// * your time range spans more than one version and you want all versions
// * returned, up the number of versions beyond the default.
Scan scan2 = new Scan();
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan2.setCaching(10); //设置客户端一次取数据缓存数据的多少
scan2.addFamily(Bytes.toBytes("author"));
scan2.setTimeRange(1587402040153L,1587558488841L);
ResultScanner scanner2 = table.getScanner(scan2);
for(Result res : scanner2){
System.out.println(res);
}
scanner2.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
Scan scan3 =
// 不推荐使用
//new Scan(Bytes.toBytes("ce_shi1"),Bytes.toBytes("ce_shi9"));
new Scan().withStartRow(Bytes.toBytes("ce_shi1")).withStopRow(Bytes.toBytes("ce_shi9"));
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan3.setCaching(10); //设置客户端一次取数据缓存数据的多少
ResultScanner scanner3 = table.getScanner(scan3);
for(Result res : scanner3){
System.out.println(res);
}
scanner3.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
Scan scan4 =
// 不推荐使用
//new Scan(Bytes.toBytes("ce_shi1"),Bytes.toBytes("ce_shi9"));
new Scan().withStartRow(Bytes.toBytes("ce_shi1")).withStopRow(Bytes.toBytes("ce_shi9"));
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan4.setCaching(10); //设置客户端一次取数据缓存数据的多少
scan4.setBatch(1);
ResultScanner scanner4 = table.getScanner(scan4);
for(Result res : scanner4){
System.out.println(res);
}
scanner4.close();
table.close();
}
}
输出
package hbase_2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
/**
* Created by szh on 2020/4/22.
* @author szh
*/
public class Hbase_BasicScan {
public static void main(String[] args) throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "cdh-manager,cdh-node1,cdh-node2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
Connection conn = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("test3");
Table table = conn.getTable(tableName);
//设置客户端缓存大小
Scan scan = new Scan();
scan.setMaxVersions(3);
ResultScanner scanner = table.getScanner(scan);
for(Result res : scanner){
System.out.println(res);
}
scanner.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
//TimeRange 默认只返回一个版本
// * Get versions of columns only within the specified timestamp range,
// * [minStamp, maxStamp). Note, default maximum versions to return is 1. If
// * your time range spans more than one version and you want all versions
// * returned, up the number of versions beyond the default.
Scan scan2 = new Scan();
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan2.setCaching(10); //设置客户端一次取数据缓存数据的多少
scan2.addFamily(Bytes.toBytes("author"));
scan2.setTimeRange(1587402040153L,1587558488841L);
ResultScanner scanner2 = table.getScanner(scan2);
for(Result res : scanner2){
System.out.println(res);
}
scanner2.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
Scan scan3 =
// 不推荐使用
//new Scan(Bytes.toBytes("ce_shi1"),Bytes.toBytes("ce_shi9"));
new Scan().withStartRow(Bytes.toBytes("ce_shi1")).withStopRow(Bytes.toBytes("ce_shi9"));
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan3.setCaching(10); //设置客户端一次取数据缓存数据的多少
ResultScanner scanner3 = table.getScanner(scan3);
for(Result res : scanner3){
System.out.println(res);
}
scanner3.close();
System.out.println("=============================");
System.out.println("=============================");
System.out.println("=============================");
Scan scan4 =
// 不推荐使用
//new Scan(Bytes.toBytes("ce_shi1"),Bytes.toBytes("ce_shi9"));
new Scan().withStartRow(Bytes.toBytes("ce_shi1")).withStopRow(Bytes.toBytes("ce_shi9"));
/**
* Set the number of rows for caching that will be passed to scanners.
* If not set, the Configuration setting {@link HConstants#HBASE_CLIENT_SCANNER_CACHING} will
* apply.
* Higher caching values will enable faster scanners but will use more memory.
* @param caching the number of rows for caching
*/
scan4.setCaching(10); //设置客户端一次取数据缓存数据的多少
scan4.setBatch(1);
ResultScanner scanner4 = table.getScanner(scan4);
for(Result res : scanner4){
System.out.println(res);
}
scanner4.close();
table.close();
}
}