深度学习图像分割评测指标MIOU之python代码详解
博主刚期末考完,就又又又被抓来干活了!这次的任务是!帮学长的论文实验的分割结果与正确的分割结果(ground truth)做个对比,给出测评结果。于是,我就找了目前几个主流的评测指标如下:
-
Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
-
Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
-
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。(最常用)
-
Frequency Weighted Intersection over Union(FWIoU,频权交并比):为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
我们选用的评测度量是MIOU,下面介绍一下MIOU衡量的具体思想。
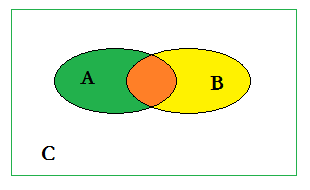
如图所示,A代表ground truth,B代表预测样本。针对预测值和真实值之间的关系,我们可以将样本分成以下四部分(这是论文中常见的四个名称,看了一学期的论文现在我才顿悟啊!真的菜!!) -
真正值(TP):预测值为1,真实值为1;橙色,A∩B
-
真负值(TN):预测值为0,真实值为0;白色,~(A∪B)
-
假正值(FP):预测值为1,真实值为0;黄色,B-(A∩B)
-
假负值(FN):预测值为0,真实值为1;绿色,A-(A∩B)
MIOU=TP/(FP+FN+TP)
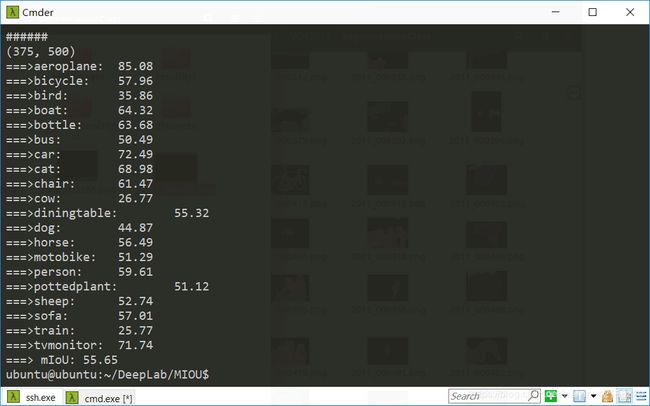
接下来给出计算MIOU的核心代码,基于此篇博客进行更加详细地说明和相应的改写(因为实验所用的数据集是VOC2011,不是CITYSCAPES)(https://blog.csdn.net/jiongnima/article/details/84750819)
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import argparse
import json
from PIL import Image
from os.path import join
#设标签宽W,长H
def fast_hist(a, b, n):#a是转化成一维数组的标签,形状(H×W,);b是转化成一维数组的标签,形状(H×W,);n是类别数目,实数(在这里为19)
'''
核心代码
'''
k = (a >= 0) & (a < n) #k是一个一维bool数组,形状(H×W,);目的是找出标签中需要计算的类别(去掉了背景) k=0或1
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)#np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
def per_class_iu(hist):#分别为每个类别(在这里是19类)计算mIoU,hist的形状(n, n)
'''
核心代码
'''
return np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))#矩阵的对角线上的值组成的一维数组/矩阵的所有元素之和,返回值形状(n,)
#hist.sum(0)=按列相加 hist.sum(1)按行相加
#def label_mapping(input, mapping):#主要是因为CityScapes标签里面原类别太多,这样做把其他类别转换成算法需要的类别(共19类)和背景(标注为255)
# output = np.copy(input)#先复制一下输入图像
# for ind in range(len(mapping)):
# output[input == mapping[ind][0]] = mapping[ind][1]#进行类别映射,最终得到的标签里面之后0-18这19个数加255(背景)
# return np.array(output, dtype=np.int64)#返回映射的标签
'''
compute_mIoU函数原始以CityScapes图像分割验证集为例来计算mIoU值的(可以根据自己数据集的不同更改类别数num_classes及类别名称name_classes),本函数除了最主要的计算mIoU的代码之外,还完成了一些其他操作,比如进行数据读取,因为原文是做图像分割迁移方面的工作,因此还进行了标签映射的相关工作,在这里笔者都进行注释。大家在使用的时候,可以忽略原作者的数据读取过程,只需要注意计算mIoU的时候每张图片分割结果与标签要配对。主要留意mIoU指标的计算核心代码即可。
'''
def compute_mIoU(gt_dir, pred_dir, devkit_dir):#计算mIoU的函数
"""
Compute IoU given the predicted colorized images and
"""
with open('/home/ubuntu/DeepLab/datasets/VOCdevkit/VOC2012/ImageSets/Segmentation/info.json', 'r') as fp:
#读取info.json,里面记录了类别数目,类别名称。(我们数据集是VOC2011,相应地改了josn文件)
info = json.load(fp)
num_classes = np.int(info['classes'])#读取类别数目,这里是20类
print('Num classes', num_classes)#打印一下类别数目
name_classes = np.array(info['label'], dtype=np.str)#读取类别名称
#mapping = np.array(info['label2train'], dtype=np.int)#读取标签映射方式,详见博客中附加的info.json文件
hist = np.zeros((num_classes, num_classes))#hist初始化为全零,在这里的hist的形状是[20, 20]
'''
原代码是有进行类别映射,所以通过json文件来存放类别数目、类别名称、 标签映射方式。而我们只需要读取类别数目和类别名称即可,可以按下面这段代码将其写死
num_classes=20
print('Num classes', num_classes)
name_classes = ["aeroplane","bicycle","bird","boat","bottle","bus","car", "cat","chair","cow","diningtable","dog","horse","motobike","person","pottedplant","sheep","sofa","train","tvmonitor"]
hist = np.zeros((num_classes, num_classes))
'''
image_path_list = join(devkit_dir, 'val2.txt')#在这里打开记录分割图片名称的txt
label_path_list = join(devkit_dir, 'val2.txt')#ground truth和自己的分割结果txt一样
gt_imgs = open(label_path_list, 'r').read().splitlines()#获得验证集标签名称列表
gt_imgs = [join(gt_dir, x) for x in gt_imgs]#获得验证集标签路径列表,方便直接读取
pred_imgs = open(image_path_list, 'r').read().splitlines()#获得验证集图像分割结果名称列表
pred_imgs = [join(pred_dir, x) for x in pred_imgs]
#pred_imgs = [join(pred_dir, x.split('/')[-1]) for x in pred_imgs]#获得验证集图像分割结果路径列表,方便直接读取
for ind in range(len(gt_imgs)):#读取每一个(图片-标签)对
pred = np.array(Image.open(pred_imgs[ind]))#读取一张图像分割结果,转化成numpy数组
label = np.array(Image.open(gt_imgs[ind]))#读取一张对应的标签,转化成numpy数组
#print pred.shape
#print label.shape
#label = label_mapping(label, mapping)#进行标签映射(因为没有用到全部类别,因此舍弃某些类别),可忽略
if len(label.flatten()) != len(pred.flatten()):#如果图像分割结果与标签的大小不一样,这张图片就不计算
print('Skipping: len(gt) = {:d}, len(pred) = {:d}, {:s}, {:s}'.format(len(label.flatten()), len(pred.flatten()), gt_imgs[ind], pred_imgs[ind]))
continue
hist += fast_hist(label.flatten(), pred.flatten(), num_classes)#对一张图片计算19×19的hist矩阵,并累加
if ind > 0 and ind % 10 == 0:#每计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
print('{:d} / {:d}: {:0.2f}'.format(ind, len(gt_imgs), 100*np.mean(per_class_iu(hist))))
print(per_class_iu(hist))
mIoUs = per_class_iu(hist)#计算所有验证集图片的逐类别mIoU值
for ind_class in range(num_classes):#逐类别输出一下mIoU值
print('===>' + name_classes[ind_class] + ':\t' + str(round(mIoUs[ind_class] * 100, 2)))
print('===> mIoU: ' + str(round(np.nanmean(mIoUs) * 100, 2)))#在所有验证集图像上求所有类别平均的mIoU值,计算时忽略NaN值
return mIoUs
compute_mIoU('/home/ubuntu/DeepLab/datasets/VOCdevkit/VOC2012/SegmentationClass/',
'/home/ubuntu/DeepLab/datasets/VOCdevkit/VOC2012/zhuosetu/',
'/home/ubuntu/DeepLab/datasets/VOCdevkit/VOC2012/ImageSets/Segmentation/'
)#执行主函数 三个路径分别为 ‘ground truth’,'自己的实验分割结果',‘分割图片名称txt文件’
这是测评结果