客户管理模块(文件上传-图片/删除-修改客户/条件查询客户)| CRM客户关系管理系统项目实战三(Struts2+Spring+Hibernate)解析+源代码
struts2文件上传代码实现上传文件图片
创建类随机生成文件名称
目录的分离
控制上传文件大小和格式
以及设置错误回显信息
客户的修改操作(放入栈当中的两种方式,以及获取值的两种方式)
修改数据的时候的回显数据,以及设置该图片的时候,删除原有的图片,添加新的图片,不改图片的时候,不修改图片
条件上回显数据
一、文件上传
1、什么是文件上传
- 将本地文件通过流的形式写到服务器上。
2、文件上传的技术:
(1)jspSmartUpload(很少用)
- jspSmartUpload组件是应用JSP进行B/S程序开发过程中经常使用的上传下载组件,它使用简单,方便。
现在我又为其加上了下载中文名字的文件的支持,真的是如虎添翼,必将赢得更多开发者的青睐。
(2)FileUpload
- FileUpload 是 Apache commons下面的一个子项目,用来实现Java环境下面的文件上传功能,与常见的SmartUpload齐名。
(3)Servlet3.0
- 文件上传
- 注解开发
- 异步请求
(4)Struts2框架
- 底层的实现FileUpload,对FileUpload进行封装。
3、文件上传的要素
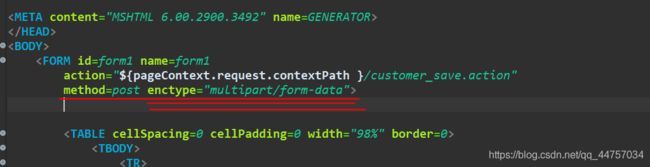
- 表单的提交方式必须是
POST(没有大小限制) - 表单当中需要提供
< input type = "file" name = "upload">这个文件项必须要求name属性和值 - 表单的enctype属性必须是
multipart/from-data
二、struts2文件上传代码实现
1、修改JSP页面(添加页面add.jsp)
(1)在页面的表单当中提供文件的上传项
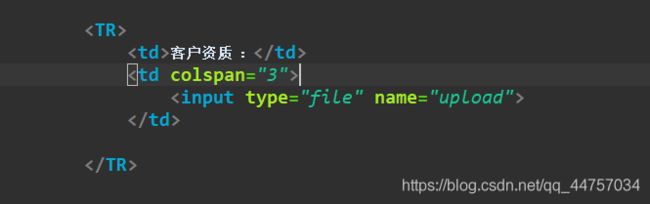
(2)修改表单的from
2、修改Action当中save方法
(1)工具类的创建:做文件上传前编写一个类处理上传文件的名称(解决目录下文件名重复的问题),以及目录分离
package com.itzheng.crm.utils;
import java.util.UUID;
/*
- 文件上传的工具类
*/
public class UploadUtils {
// 解决目录下文件名重复的问题
public static String getUuidFileName(String fileName) {
int idx = fileName.lastIndexOf(".");// aa.txt
String extions = fileName.substring(idx);// 等到文件的扩展名
return UUID.randomUUID().toString().replace("-", "") + extions;// 得到随机的文件名
}
/*
* 目录分离的方法
*/
public static String getPath(String uuidFileName) {
int code1 = uuidFileName.hashCode();
int d1 = code1 & 0xf;//作为一级目录
int code2 =code1 >>> 4;//code1右移动4位
int d2 = code2 & 0xf;//二级目录
return "/"+d1+"/"+d2;//目录的分离
}
public static void main(String[] args) {
System.out.println(getUuidFileName("aaa.txt"));
}
}

(2)Struts2的文件上传:
-
在Action当中提三个属性,对三个属性提供set方法。
字符串类型 上传项名称 + FileName
文件类型 上传项的名称
字符串类型 上传项的名称+ContextType
在CustomerAction当中提供文件上传的三个属性 -
文件上传提供的三个属性
private String uploadFileName;// 这个就直接接收到文件名称
private File upload;// 上传文件本身
private String uploadContextType;// 代表的是文件的类型
- upload与jsp页面对应的上传文件name属性名称对应

- save方法当中创建目录,目录分离,随机生成文件
将源文件(上传的文件)copyFile到目标文件
/*
- 保存客户的方法:save
*/
public String save() throws IOException {
// 上传图片
if(upload != null) {
//进行文件的上传
//设置文件上传的路径:
String path = "C:/upload";
//一个目录下存放相同文件名:文件名是一个随机的文件名(生成随机的文件)
String uuidFileName = UploadUtils.getUuidFileName(uploadFileName);
//一个目录下存放的文件过多:目录分离
String realPath = UploadUtils.getPath(uuidFileName);
//创建目录
String url = path+realPath;
File file = new File(url);//在系统当中创建目录
if(!file.exists()) {
file.mkdirs();
}
//文件上传
File dictFile = new File(url+"/"+uuidFileName);//在目录当中创建文件
FileUtils.copyFile(upload, dictFile);//源文件,目标文件
}
// 保存客户
customerService.save(customer);
return NONE;
}
测试:

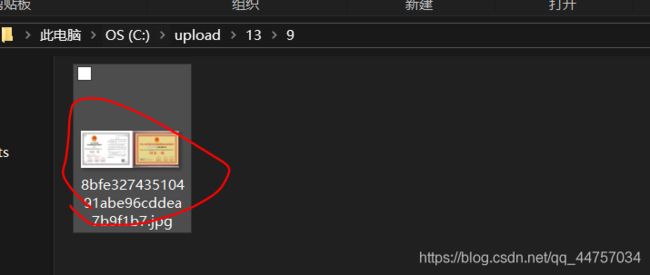
(3)将文件上传的路径存入到数据库当中
- 修改实体
在Customer类当中
设置属性保存客户资质的图片路径的属性
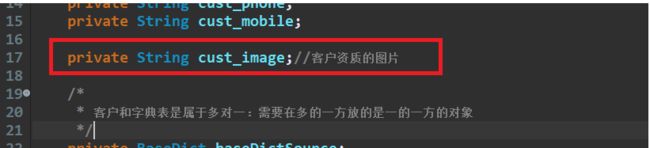
- 以及对应get和set方法

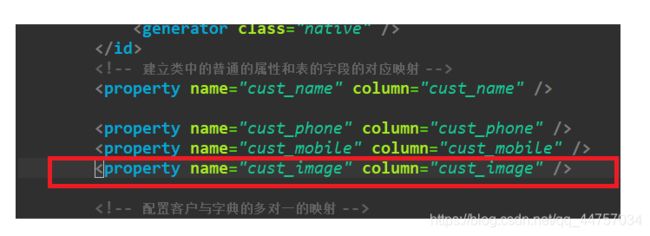
- 修改映射:修改Customer.hbm.xml
- 修改文件上传的代码: 在CustomerAction当中设置属性保存路径,并设置跳转

- 配置跳转在struts.xml当中

(4)测试
- 因为在applicationContext.xml当中配置的是update
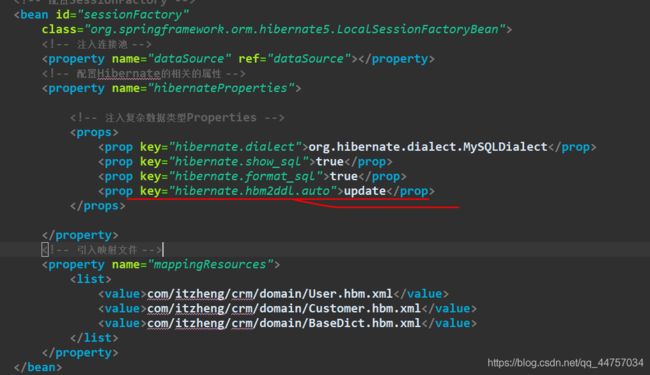
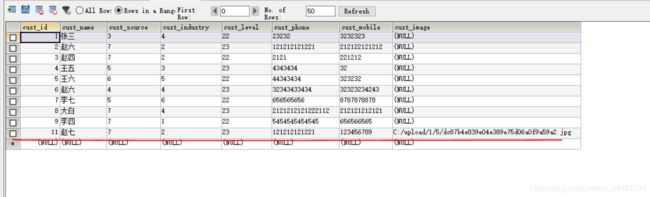
- 运行程序的时候会自动添加一列在数据库当中

- 测试

- 提交成功
3、设置拦截器:struts2控制文件大小以及文件的格式(拦截器当中都以及具备的功能)
(1)在struts.xml当中修改常量:配置Struts2当中一个表单上传的文件的总大小
- 一个表单的总大小不能超过5M

(2)在struts.xml当中对应提交的表单的Action配置当中:引入拦截器
- 配置单个文件上传的大小不超过2M:
2097152 - 设置上传单个文件的格式 jpg和png:
.jpg,.png

(3)配置input视图:当上传文件格式不正确的时候会报错,因此需要配置input视图
- 在struts.xml当中配置

- 在add.jsp页面回显错误信息

(4)测试
- 上传txt文件

- 回显错误信息

三、客户的删除操作
1、修改list.jsp列表页面上的路径

2、编写Action的delete方法
在CustomerAction当中的delete方法,先查询后删除
(1)在save方法当中编写通过id查询customer
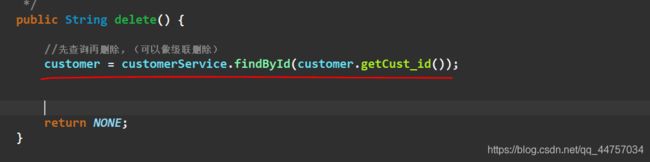
- serviceimpl查询方法
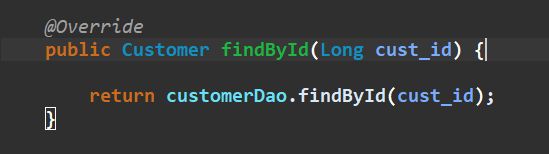
- DaoImpl查询方法

(2)在action当中创建delete方法

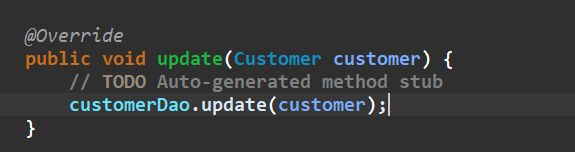
- 在seviceImpl删除方法
@Override
public void delete(Customer customer) {
// TODO Auto-generated method stub
customerDao.delete(customer);
}
- 在daoimpl删除方法
@Override
//Dao 当中删除客户的方法
public void delete(Customer customer) {
this.getHibernateTemplate().delete(customer);
}
3、测试方法

- 数据删除成功:
- 图片删除成功:
四、客户的修改回显
1、修改列表页面list.jsp上的路径
![]()
在CustomerAction
-
将对象放入到栈当中两种方式:
第一种:手动压栈。
第二种:因为上面模型驱动管理的对象,默认就在栈里面(所以customer已经在值栈当中了)
-
在页面上的取值两种不同方式
如果我们使用第一种方式:回显数据;
如果使用第二种方式:回显数据:
测试一、编写Action的edit方法:方式一
(1)第一种方式:手动压栈

- 配置跳转是struts.xml当中

(2)修改edit.jsp页面

(3)测试

测试二、编写Action的edit方法:方式二直接在页面上使用栈当中的数据
(1)查询到数据之后直接跳转
/*
* 编辑客户的方法
*/
public String edit() {
// 根据id查询,跳转页面,回显数据
customer = customerService.findById(customer.getCust_id());
//第二种:因为上面模型驱动管理的对象,默认就在栈里面(customer已经在值栈当中了)
//两种方式在页面上的取值方式不同
// 跳转页面
return "editSuccess";
}
(2)修改edit.jsp页面上的数据


(3)测试

2、使用第二种方式
(1)查询到数据之后直接跳转
/*
* 编辑客户的方法
*/
public String edit() {
// 根据id查询,跳转页面,回显数据
customer = customerService.findById(customer.getCust_id());
//第二种:因为上面模型驱动管理的对象,默认就在栈里面(customer已经在值栈当中了)
//两种方式在页面上的取值方式不同
// 跳转页面
return "editSuccess";
}
(2)修改edit.jsp页面上的数据
- 异步加载并且回显下拉列表的数据
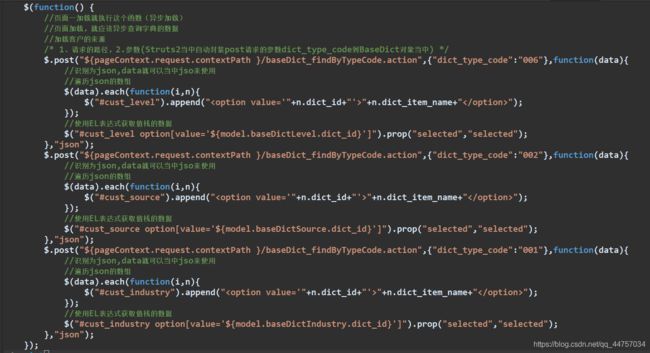
- 表单回显数据
回显数据:隐藏字段
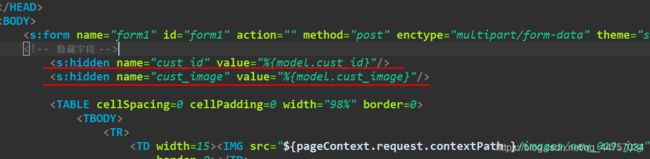
表单回显文本框


(3)测试回显成功
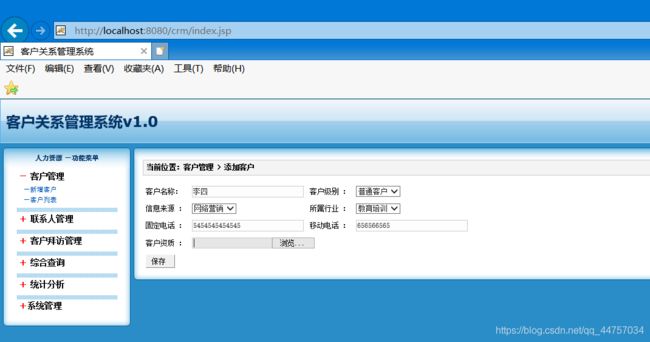
五、客户的修改保存
1、修改edit.jsp中的提交的路径
![]()
2、编写Action当中的update 的方法
(1)CustomerAction的update方法
先判断上传的update是不是为空,如果不为空那么证明修改了图片,将原有的路径对应的图片删除,然后将新路径下的图片上传,并更新这个新的路径
如果为空,那么证明没有修改图片,图片的路径不需要更改
将模型驱动获取的对象保存到数据库
/*
* 修改客户的方法:update
*/
public String update() throws IOException {
// 文件项是否已经选择:如果选择就删除原有文件然后上传新文件。如果没有选择,就使用原有的即可。
if (upload != null) {
// 以及选了
// 删除原有文件
String cust_image = customer.getCust_image();
if (cust_image != null || !"".equals(cust_image)) {
File file = new File(cust_image);
file.delete();
}
// 完成文件上传:
// 进行文件的上传
// 设置文件上传的路径:
String path = "C:/upload";
// 一个目录下存放相同文件名:文件名是一个随机的文件名(生成随机的文件)
String uuidFileName = UploadUtils.getUuidFileName(uploadFileName);
// 一个目录下存放的文件过多:目录分离
String realPath = UploadUtils.getPath(uuidFileName);
// 创建目录
String url = path + realPath;//创建美目录的路径
File file = new File(url);// 获取对应的文件信息
if (!file.exists()) {
file.mkdirs();//支持创建目录
}
// 文件上传
File dictFile = new File(url + "/" + uuidFileName);// 在目录当中创建文件
FileUtils.copyFile(upload, dictFile);// 源文件,目标文件
customer.setCust_image(url + "/" + uuidFileName);
}
// 模型驱动以及分装好数据
customerService.update(customer);
return "updateSuccess";
}
(2)CustomerServiceImpl的update方法
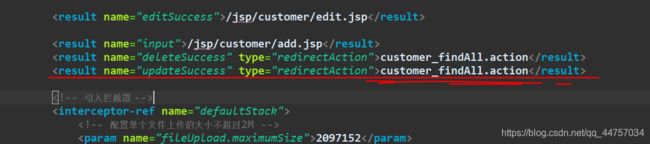
(3)CustomerDaoImpl的update方法

(4)在struts.xml当中配置返回的跳转页面(这里是查询所有的数据)
3、测试


图片修改成功

六、条件查询客户
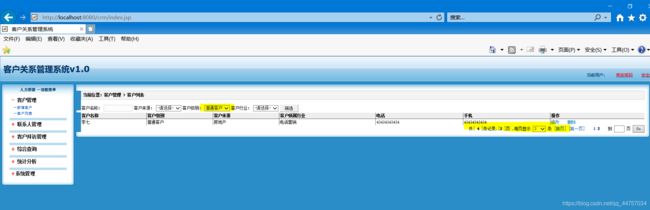
1、客户管理的条件查询
(1)在列表的页面list.jsp上新加几个选框

(2)向选框当中异步加载数据
![]()
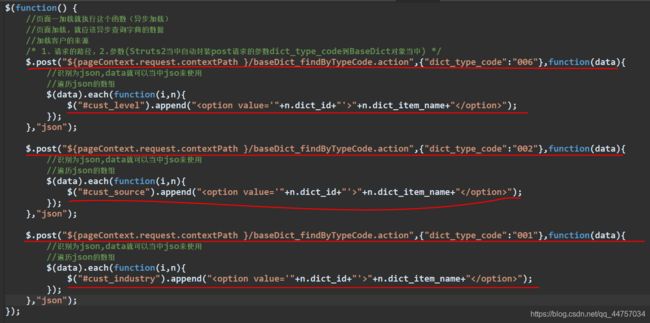
2、修改CustomerAction当中的findAll方法(在DetachedCriteria对象当中添加条件然后带条件的查询下符合页面上所选择的信息)
/*
* 分页查询客户的方法
*/
public String findAll() {
// 接收参数:分页的参数:
// 最好使用DetachedCriteria对象(条件查询--带分页)
DetachedCriteria detachedCriteria = DetachedCriteria.forClass(Customer.class);
// 设置离线的条件(在web层设置条件)detachedCriteria向符合特征的当中添加条件
if (customer.getCust_name() != null) {
// 添加条件:输入名称:设置查询的是cust_name的名称模糊匹配模型驱动当中的值
detachedCriteria.add(Restrictions.like("cust_name", "%" + customer.getCust_name() + "%"));
}
if (customer.getBaseDictSource() != null) {
if (customer.getBaseDictSource().getDict_id() != null
&& !"".equals(customer.getBaseDictSource().getDict_id())) {
// 添加条件:设置查询的是baseDictSource.dict_id的值模糊匹配模型驱动当中的值,即对应的id
detachedCriteria.add(Restrictions.eq("baseDictSource.dict_id", customer.getBaseDictSource().getDict_id()));
}
}
if (customer.getBaseDictLevel() != null) {
if (customer.getBaseDictLevel().getDict_id() != null&& !"".equals(customer.getBaseDictLevel().getDict_id())) {
// 添加条件:设置查询的是baseDictSource.dict_id的值模糊匹配模型驱动当中的值,即对应的id
detachedCriteria.add(Restrictions.eq("baseDictLevel.dict_id", customer.getBaseDictLevel().getDict_id()));
}
}
if (customer.getBaseDictIndustry() != null) {
if (customer.getBaseDictIndustry().getDict_id() != null
&& !"".equals(customer.getBaseDictIndustry().getDict_id())) {
// 添加条件:设置查询的是baseDictSource.dict_id的值模糊匹配模型驱动当中的值,即对应的id
detachedCriteria.add(Restrictions.eq("baseDictIndustry.dict_id", customer.getBaseDictIndustry().getDict_id()));
}
}
// 调用业务层查询:带着条件去查询
PageBean<Customer> pageBean = customerService.findByPage(detachedCriteria, currPage, pageSize);
ActionContext.getContext().getValueStack().push(pageBean);// 放入到值栈当中
return "findAll";
}
在点击查询之后,选框当中数据会消失
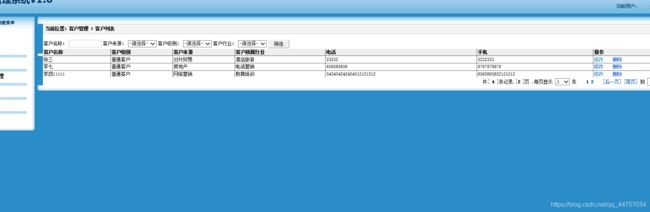
在查询一次条件之后,在点击下一页的时候会查询出来全部的数据
需要设置条件的数据回显

3、在条件上回显数据
在list.jsp页面上
回显input的数据

回显下列列表的数据
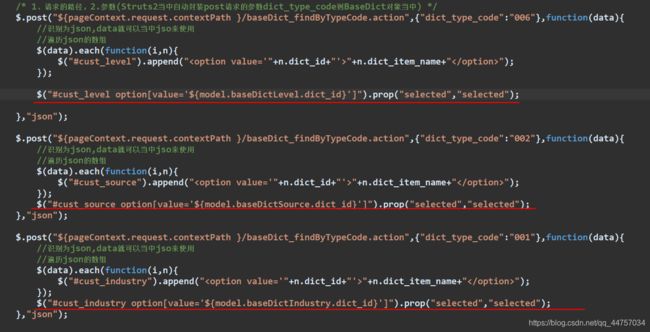
测试