CRM项目总结
CRM项目总结
用户的登录和注册
用户的注册操作
-
从页面获取数据,后台使用数据模型进行封装,同时对密码进行密码的数据MD5加密操作
/** * 使用md5的算法进行加密 */ public static String md5(String plainText) { byte[] secretBytes = null; try { secretBytes = MessageDigest.getInstance("md5").digest(plainText.getBytes()); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("没有md5这个算法!"); } String md5code = new BigInteger(1, secretBytes).toString(16);// 16进制数字 // 如果生成数字未满32位,需要前面补0 for (int i = 0; i < 32 - md5code.length(); i++) { md5code = "0" + md5code; } return md5code; }
用户的登录操作
- 前台输入数据,后台与数据库对数据的用户名和密码(再次进行MD5进行加密)对象校对,并将查询到的数据返回给web层进行处理。
客户列表操作
客户的查询(分页)
-
设置离线查询条件DetachedCriteria(方便后续的分页查询)
-
对于前台来说分页需要当前页(currPage)、每页数据数量(pageSize)、数据总数量(totalCount)、数据根据每页数据数量所分的总页数(totalPage)、每页显示的数据的集合(list)
-
所以我们需要创建一个JavaBean对象PageBean存储分页的相关数据
public class PageBean<T> { private Integer currPage; // 当前页 private Integer pageSize; // 每页显示多少条记录 private Integer totalPage;// 总页数 private Integer totalCount;// 总条数 private List<T> list; // 每次查询到的数据的集合 get/set方法 } -
从前台传当前页(currPage)和每页数据数量(pageSize),并将PageBean压入值栈中
-
web层对当前页(currPage)和每页数据数量(pageSize)进行获取并初始化。
// 用于接收当前页数据 private Integer currPage = 1; public void setCurrPage(Integer currPage) { if (currPage == null) { currPage = 1; } this.currPage = currPage; } // 用于接收当前页数据 private Integer pageSize = 3; public void setPageSize(Integer pageSize) { if (pageSize == null) { pageSize = 3;// 初始数据每页显示3条 } this.pageSize = pageSize; } -
在Service层封装PageBean
@Override // 业务层分页查询客户的方法 public PageBean<Customer> findByPage(DetachedCriteria detachedCriteria, Integer currPage, Integer pageSize) { PageBean<Customer> pageBean = new PageBean<Customer>(); // 封装当前页数(currPage) pageBean.setCurrPage(currPage); // 封装每页显示的记录数(pageSize) pageBean.setPageSize(pageSize); // 封装数据的总数(totalCount) Integer totalCount = customerDao.findCount(detachedCriteria); pageBean.setTotalCount(totalCount); // 封装总页数 // 1.先将总页数转化为Double方便向上取整 Double tc = totalCount.doubleValue(); Double num = Math.ceil(tc / pageSize); pageBean.setTotalPage(num.intValue()); // 封装每页显示查询到的客户数据 // 从第几条数据开始 Integer begin = (currPage - 1) * pageSize; List<Customer> list = customerDao.findByPage(detachedCriteria, begin, pageSize); pageBean.setList(list); return pageBean; } -
dao层查询总数量
public Integer findCount(DetachedCriteria detachedCriteria) { detachedCriteria.setProjection(Projections.rowCount()); List<Long> list = (List<Long>) this.getHibernateTemplate().findByCriteria(detachedCriteria); if (list.size() > 0) { return list.get(0).intValue(); } return null; } -
离线的分页查询
// 分页查询 public List<T> findByPage(DetachedCriteria detachedCriteria, Integer begin, Integer pageSize) { // 清空查询总数中缓存的sql语句 detachedCriteria.setProjection(null); return (List<T>) this.getHibernateTemplate().findByCriteria(detachedCriteria, begin, pageSize); }
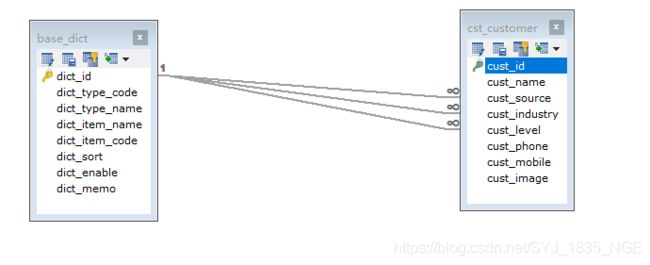
客户的数据字典
-
在数据字典中数据字典的id和客户的客户的来源、客户的行业、客户的级别相对应。(字典id是客户表来源。行业、级别的外键)
-
在保存客户的相关操作上,我们有关于客户的来源、客户的行业、客户的级别。为了让客户更方便的做相对应得选择,我们可以对这三个数据进行异步的加载。
-
数据字典的表
CREATE TABLE `base_dict` ( `dict_id` varchar(32) NOT NULL COMMENT '数据字典id(主键)', `dict_type_code` varchar(10) NOT NULL COMMENT '数据字典类别代码', `dict_type_name` varchar(64) NOT NULL COMMENT '数据字典类别名称', `dict_item_name` varchar(64) NOT NULL COMMENT '数据字典项目名称', `dict_item_code` varchar(10) DEFAULT NULL COMMENT '数据字典项目(可为空)', `dict_sort` int(10) DEFAULT NULL COMMENT '排序字段', `dict_enable` char(1) NOT NULL COMMENT '1:使用 0:停用', `dict_memo` varchar(64) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`dict_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
根据字典码(dict_type_code)查询出所有符合条件的字典数据。得到对应的字典类型名(dict_type_name)。
-
异步加载的代码:(选择的时候将字典id传到后台封装进客户的来源、级别和行业上)
<script type="text/javascript" src="${pageContext.request.contextPath }/js/jquery-1.11.3.min.js" ></script> <script type="text/javascript"> $(function() { //页面加载函数就会为执行 //页面加载,异步查询字典的数据 //加载客户的来源 $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"002"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_source").append("+n.dict_item_name+""); }); },"json"); $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"006"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_level").append("+n.dict_item_name+""); }); },"json"); $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"001"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_industry").append("+n.dict_item_name+""); }); },"json"); }); </script><td>客户级别 :</td> <select id="cust_level" name="baseDictLevel.dict_id" > <option value="">--请选择--</option> </select> <td>信息来源 :</td> <select id="cust_source" name="baseDictSource.dict_id"> <option value="">--请选择--</option> </select> <td>所属行业 :</td> <select id="cust_industry" name="baseDictIndustry.dict_id"> <option value="">--请选择--</option> </select> -
在添加客户处要求对客户的资质进行鉴定,上传操作
使用Struts2的上传组件
<input type="file" name="upload" > -
在后台提供三个有关文件上传的属性
// 实现客户资质的上传 private File upload; private String uploadFileName;//文件组件名+FileName private String uploadContentType;//文件组件名+ContentType; //set方法 -
处理客户的保存操作(并将资质鉴定的路径放入到数据表的cust_image字段中)
// 保存客户信息 public String save() throws IOException { // 1.判断文件是否为空 if (upload != null) { // 2.设置文件上传的路径 String path = "E:/upload"; // 3.同一目录下文件的重名问题:随机文件名 // 获取得到随机产生后的文件名: String randomFileName = UploadUtils.getUUIDFileName(uploadFileName); // 4.同一目录文件或多:目录的分离 String separateDirectory = UploadUtils.getDandomDirectory(uploadFileName); // 5.目录的创建 File file = new File(path + separateDirectory); if (!file.exists()) { file.mkdirs(); } // 6.进行文件的上传操作 String lastpath = file + "/" + randomFileName; File dictFile = new File(lastpath); FileUtils.copyFile(upload, dictFile); // 7.将上传的文件的路径保存到数据库中 // 手动将路径封装到customer中 customer.setCust_image(lastpath); } customerService.save(customer); return "saveSuccess"; }
客户的修改操作
-
首先根据id查询客户的数据,并对数据在edit页面进行数据得回显操作。
-
在对于客户的来源,行业,级别上,我们仍然使用异步加载的操作,将数据进行回显。并将查询到的数据使用选择下拉进行显示,并将客户对应的默认选中。
script type="text/javascript"> $(function() { //页面加载函数就会为执行 //页面加载,异步查询字典的数据 //加载客户的来源 $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"002"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_source").append("+n.dict_item_name+""); }); $("#cust_source option[value='${model.baseDictSource.dict_id}']").prop("selected","selected"); },"json"); $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"006"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_level").append("+n.dict_item_name+""); }); $("#cust_level option[value='${model.baseDictLevel.dict_id}']").prop("selected","selected"); },"json"); $.post("${pageContext.request.contextPath }/baseDict_findByTypeCode.action",{"dict_type_code":"001"},function(data){ //遍历json数据 $(data).each(function(i,n) { $("#cust_industry").append("+n.dict_item_name+""); }); $("#cust_industry option[value='${model.baseDictIndustry.dict_id}']").prop("selected","selected"); },"json"); }); -
对于客户的修改我们需要注意是否改变了上传的文件进行判断
-
如果没有改变我们不做任何的操作,
-
如果进行了修改,我们将该客户的数据进行更新,并将原来的文件在存放处进行删除
// 修改客户的方法 public String update() throws IOException { // 判断文件向是否被选择 if (upload != null) { // 被选择了(删除原来文件的内容) String cust_image = customer.getCust_image(); if (cust_image != null || !"".equals(cust_image)) { // 说明有内容 File file = new File(cust_image); if (file.exists()) { // 如果存在就删除 file.delete(); } } // 文件的上传 // 2.设置文件上传的路径 String path = "E:/upload"; // 3.同一目录下文件的重名问题:随机文件名 // 获取得到随机产生后的文件名: String randomFileName = UploadUtils.getUUIDFileName(uploadFileName); // 4.同一目录文件或多:目录的分离 String separateDirectory = UploadUtils.getDandomDirectory(uploadFileName); // 5.目录的创建 File file = new File(path + separateDirectory); if (!file.exists()) { file.mkdirs(); } // 6.进行文件的上传操作 String lastpath = file + "/" + randomFileName; File dictFile = new File(lastpath); FileUtils.copyFile(upload, dictFile); // 7.将上传的文件的路径保存到数据库中 // 手动将路径封装到customer中 customer.setCust_image(lastpath); } customerService.update(customer); return "updateSuccess"; }
客户的查询操作
-
根据客户的名称、客户的来源、客户的行业、或者级别进行查询。
// 查询所有用户操作(列表显示) public String findAll() { // 接收参数,分页参数 // 最好使用DetachedCriteria进行分页查询 DetachedCriteria detachedCriteria = DetachedCriteria.forClass(Customer.class); // 实现筛选操作 if (customer.getCust_name() != null) { detachedCriteria.add(Restrictions.like("cust_name", "%" + customer.getCust_name() + "%")); } if (customer.getBaseDictSource() != null) { if (customer.getBaseDictSource().getDict_id() != null && !"".equals(customer.getBaseDictSource().getDict_id())) { detachedCriteria .add(Restrictions.eq("baseDictSource.dict_id", customer.getBaseDictSource().getDict_id())); } } if (customer.getBaseDictLevel() != null) { if (customer.getBaseDictLevel().getDict_id() != null && !"".equals(customer.getBaseDictLevel().getDict_id())) { detachedCriteria .add(Restrictions.eq("baseDictLevel.dict_id", customer.getBaseDictLevel().getDict_id())); } } if (customer.getBaseDictIndustry() != null) { if (customer.getBaseDictIndustry().getDict_id() != null && !"".equals(customer.getBaseDictIndustry().getDict_id())) { detachedCriteria .add(Restrictions.eq("baseDictIndustry.dict_id", customer.getBaseDictIndustry().getDict_id())); } } // 调用业务层方法 PageBean<Customer> pageBean = customerService.findByPage(detachedCriteria, currPage, pageSize); ServletActionContext.getContext().getValueStack().push(pageBean); return "findAll"; } -
查询完成之后,搜索框的数据还存在(默认选中),并重新加载列表。
客户的删除
- 根据id对客户进行删除操作。
联系人操作
-
联系人和客户的关系(一个客户多个联系人公司产品单一的情况下)
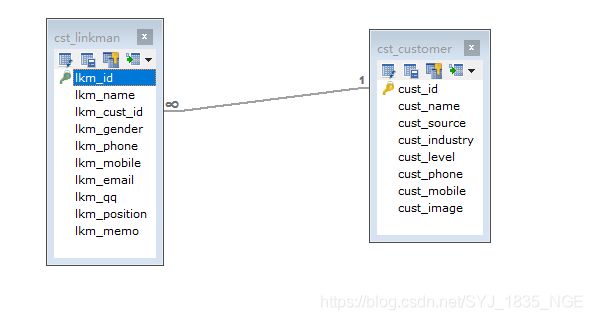
-
分页查询所有
-
添加联系人(同步查询客户)
public String saveUI() { // 同步加载 // 查询出所有客户 List<Customer> list = customerService.findAll(); // 将所有客户保存到值栈中 ServletActionContext.getContext().getValueStack().set("list", list); return "saveUI"; } -
文本框下拉选择
-
搜索框的查询
-
修改(客户的异步加载下拉选择)
联系人的删除(级联)
-
cascade=“delete” inverse=“true”
-
解决延迟加载问题:
在web.xml文件中配置:
<filter> <filter-name>openSessionInViewFilterfilter-name> <filter-class>org.springframework.orm.hibernate5.support.OpenSessionInViewFilterfilter-class> filter> <filter-mapping> <filter-name>openSessionInViewFilterfilter-name> <url-pattern>/*url-pattern> filter-mapping>
抽取通用的DAO
-
将保存、更新、删除、根据id查询、查询所有、分页查询方法,抽取到一个通用的类中
public void save(T t); public void update(T t); public void delete(T t); // 通过id获取返回对象 public T findById(Serializable id); // 查询所有 public List<T> findAll(); // 查询总的数据量 public Integer findCount(DetachedCriteria detachedCriteria); // 进行分页查询 public List<T> findByPage(DetachedCriteria detachedCriteria, Integer begin, Integer pageSize); -
唯一比较难的就是获取某个实体的字节码对象(有两种方式)
构造方法的方法
-
子类使用无参的构造方法调用父类的有参的构造方法(传入所需的字节码对象)
//根据有参的构造方法获取子类的class对象 public BaseDaoImpl(Class clazz) { System.out.println(clazz); this.clazz = clazz; }
反射的方式
-
根据反射获取继承类的实例化类型参数
public BaseDaoImpl() { // 第一步:获得Class // 正在被调用的类的Class,CustomerImple或者LinkManImple. Class clazz = this.getClass(); // 第二步:获取参数化类型参数(BaseDaoImplBaseDaoImpl Type type = clazz.getGenericSuperclass(); ParameterizedType pType = (ParameterizedType) type; // 第三步:根据(参数化类型参数)获得(实际化类型参数):得到一个实际类型参数的数组? Map)
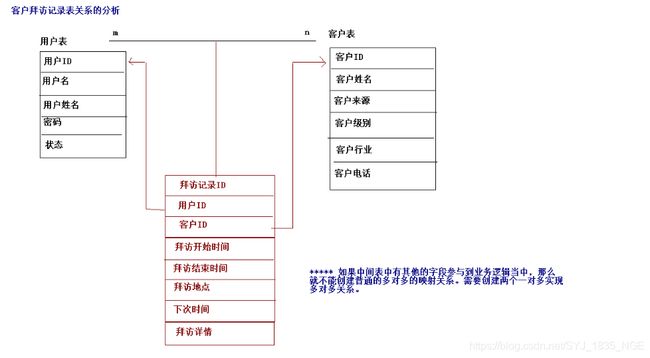
客户拜访操作
-
业务员(用户)和客户(客户)之间关系(需要具体业务具体分析:一对多—公司产品比较单一,只允许一个业务员对应多个客户。多对多—大公司有不同的产品,不同产品下有不同业务员都可以接触到同一个客户,一个客户可以对应多个业务员)。大部分情况创建成多对多。
-
建表字段:
private String visit_id; private Date visit_time; private String visit_addr; private String visit_detail; private Date visit_nexttime; // 拜访记录相关联的客户对象 private Customer customer; // 拜访记录相关联的用户对象 private User user;
拜访记录的添加
-
对于业务员(User)和客户(Customer)可以分别使用异步加载的方式(下拉选择)
<script type="text/javascript"> $(function() { //异步加载客户信息 $.post("${pageContext.request.contextPath }/customer_findAllCustomer.action",{},function(date){ $(date).each(function(i,n) { $("#customer").append("+n.cust_name+""); }); },"json"); //异步加载用户信息 $.post("${pageContext.request.contextPath }/user_findAllUser.action",{},function(date){ $(date).each(function(i,n) { $("#user").append("+n.user_name+""); }); },"json"); }); </script>
拜访记录的列表查询
- 分页查询
- 使用jquery日历组件进行日期的选择(格式控制JQ)
拜访记录的修改
- 业务员(User)和客户(Customer)使用同步查询(下拉选择)
SSH纯注解整合
Struts2层
-
创建相应的类
-
开启组件扫描(扫描指定包下(及其子包)的资源)
<context:component-scan base-package="com.syj" /> -
使用注解将类都交给Spring管理
@Controller("customerAction") //@Service("customerService") //@Repository("customerDao")// -
在Struts2中配置Action(使用注解)
/* * 最开始的时候我们需要将action叫交给Spring进行管理 ** * 配置Action ** */ @Controller("customerAction") //* *@Scope("prototype") // scope="prototype"> @ParentPackage("struts-default") // extends="struts-default" @Namespace("/") // namespace="/" public class CustomerAction extends ActionSupport implements ModelDriven<Customer> { private Customer customer = new Customer(); @Override public Customer getModel() { return customer; } @Resource(name = "customerService") private CustomerService customerService; @Action(value = "customer_save", results = { @Result(name = "success", location = "/login.jsp") }) // name="customer_save" public String save() { System.out.println("CustomerAction的save方法执行了"); customerService.save(customer); return SUCCESS; } }
Hibernate注解实现替代
-
取出Hibernate的核心配置文件:
<context:property-placeholder location="classpath:jdbc.properties" /> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" > <property name="driverClass" value="${jdbc.driver}" /> <property name="jdbcUrl" value="${jdbc.url}" /> <property name="user" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> bean> <bean id="sessionFactory" class="org.springframework.orm.hibernate5.LocalSessionFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="hibernateProperties"> <props> <prop key="hibernate.dialect">org.hibernate.dialect.MySQLDialectprop> <prop key="hibernate.show_sql">trueprop> <prop key="hibernate.format_sql">trueprop> <prop key="hibernate.hbm2ddl.auto">updateprop> props> property> <property name="packagesToScan" > <list> <value>com.syj.entityvalue> list> property> bean> -
SessionFactory
-
数据源(DataSource)
-
Hibernate中的一些相关属性(是否格式化sql、是否显示sql等等)
-
映射文件的引入
Spring的applicationContext.xml配置
-
在DAO层使用HIbernate模板
<bean id="hibernateTemplate" class="org.springframework.orm.hibernate5.HibernateTemplate"> <property name="sessionFactory" ref="sessionFactory"/> bean> -
开启注解事务(在Service层开启事务)
<bean id="transactionManager" class="org.springframework.orm.hibernate5.HibernateTransactionManager"> <property name="sessionFactory" ref="sessionFactory" /> bean> <tx:annotation-driven transaction-manager="transactionManager"/>
链接:
链接:https://pan.baidu.com/s/1uIxjEEB1pj4OqYV7R_IpQw 密码:huaq