tensorflowweek2
实现非线性回归
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt数据准备
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]
# -0.5-0.5表示范围的一维数据,
# linspace是生成范围内的等差数列
# 后边这个将生成的数据每一个数据转换为一维数组
# [-0.5 -0.49497487 -0.48994975 ..]--->[[-0.5][-0.49497487][-0.48994975][-0.48492462][-0.4798995 ]
# print(x_data.shape)
# print(x_data)
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
x=tf.placeholder(tf.float32,[None,1])
y=tf.placeholder(tf.float32,[None,1])中间层
# 中间层 10个神经元
Weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10]))
Wx_plus_b_L1=tf.matmul(x,Weights_L1)+biases_L1
L1=tf.nn.tanh(Wx_plus_b_L1)输出层
# 输出层
Weight_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1]))
Wx_plus_b_L2=tf.matmul(L1,Weight_L2)+biases_L2损失值和优化
# 代价函数和优化器
prediction=tf.nn.tanh(Wx_plus_b_L2)
loss=tf.reduce_mean(tf.square(y-prediction))
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)运行结果展示
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
prediction_value=sess.run(prediction,feed_dict={x:x_data})
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()
手写数字识别:
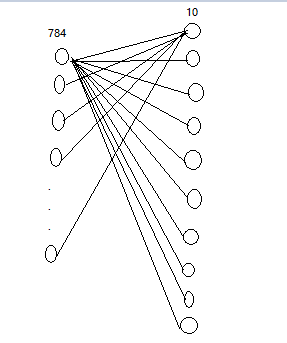
简述:每张图片784(28*28)个像素,通过784个像素来获得十个数字字母的哪一个数字的概率,未增加隐藏层,可根据上一部分自行添加隐藏层。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data数据准备以及分组
# 路径,将y标签转换为0-1格式
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)
# 定义批次,并不是6000次串行输入,而是每次以矩阵的形式每次放入数量为100的矩阵
batch_size=100
# 批次数量
n_batch=mnist.train.num_examples//batch_size构建网络的隐藏层
# 行不定列定
x=tf.placeholder(tf.float32,[None,784])
y=tf.placeholder(tf.float32,[None,10])
W1=tf.Variable(tf.random_normal([784,32]))
b1=tf.Variable(tf.zeros([32]))
w_b1=tf.matmul(x,W1)+b1
#双曲正切作为中间层输出的激活函数
L1=tf.nn.tanh(w_b1)
W2=tf.Variable(tf.random_normal([32,10]))
b2=tf.Variable(tf.zeros([10]))
w_b2=tf.matmul(L1,W2)+b2
prediction=tf.nn.softmax(w_b2)定义损失函数和优化器
#二次代价函数
loss=tf.reduce_mean(tf.square(y-prediction))
train_step=tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# 求出概率最大的位置作为预测结果和标签进行比较
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(100):
for batch in range (n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print(acc)
# print('Iter:'+str(epoch)+'Testing accuracy:'+str(acc))