注册中心 Eureka 源码解析 —— Eureka-Server 集群同步
点击上方“芋道源码”,选择“置顶公众号”
技术文章第一时间送达!
源码精品专栏
精尽 Dubbo 原理与源码专栏( 已经完成 69+ 篇,预计总共 75+ 篇 )
中文详细注释的开源项目
Java 并发源码合集
RocketMQ 源码合集
Sharding-JDBC 源码解析合集
Spring MVC 和 Security 源码合集
MyCAT 源码解析合集
摘要: 原创出处 http://www.iocoder.cn/Eureka/server-cluster/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文主要基于 Eureka 1.8.X 版本
1. 概述
2. 集群节点初始化与更新
2.1 集群节点启动
2.2 更新集群节点信息
2.3 集群节点
3. 获取初始注册信息
4. 同步注册信息
4.1 同步操作类型
4.2 发起 Eureka-Server 同步操作
4.3 接收 Eureka-Server 同步操作
4.4 处理 Eureka-Server 同步结果
1. 概述
本文主要分享 Eureka-Server 集群同步注册信息。
Eureka-Server 集群如下图:
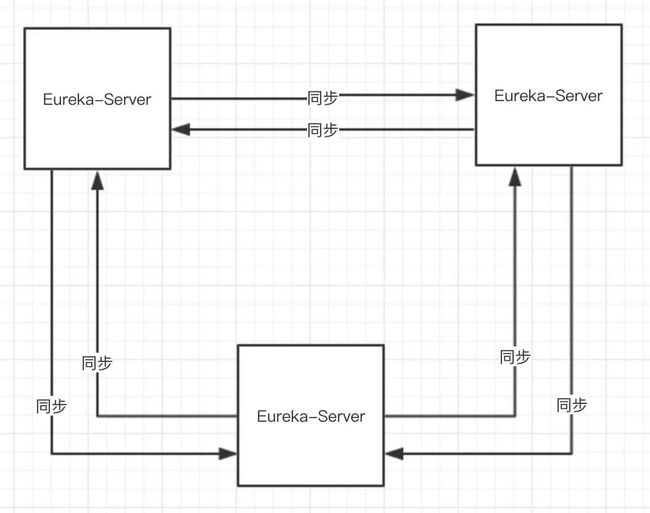
Eureka-Server 集群不区分主从节点或者 Primary & Secondary 节点,所有节点相同角色( 也就是没有角色 ),完全对等。
Eureka-Client 可以向任意 Eureka-Client 发起任意读写操作,Eureka-Server 将操作复制到另外的 Eureka-Server 以达到最终一致性。注意,Eureka-Server 是选择了 AP 的组件。
Eureka-Server 可以使用直接配置所有节点的服务地址,或者基于 DNS 配置。推荐阅读:《Spring Cloud构建微服务架构(六)高可用服务注册中心》 。
本文主要类在 com.netflix.eureka.cluster 包下。
OK,让我们开始愉快的遨游在代码的海洋。
推荐 Spring Cloud 书籍:
请支持正版。下载盗版,等于主动编写低级 BUG 。
程序猿DD —— 《Spring Cloud微服务实战》
周立 —— 《Spring Cloud与Docker微服务架构实战》
两书齐买,京东包邮。
推荐 Spring Cloud 视频:
Java 微服务实践 - Spring Boot
Java 微服务实践 - Spring Cloud
Java 微服务实践 - Spring Boot / Spring Cloud
ps :注意,本文提到的同步,准确来说是复制( Replication )。
2. 集群节点初始化与更新
com.netflix.eureka.cluster.PeerEurekaNodes ,Eureka-Server 集群节点集合 。构造方法如下 :
public class PeerEurekaNodes {
private static final Logger logger = LoggerFactory.getLogger(PeerEurekaNodes.class);
/**
* 应用实例注册表
*/
protected final PeerAwareInstanceRegistry registry;
/**
* Eureka-Server 配置
*/
protected final EurekaServerConfig serverConfig;
/**
* Eureka-Client 配置
*/
protected final EurekaClientConfig clientConfig;
/**
* Eureka-Server 编解码
*/
protected final ServerCodecs serverCodecs;
/**
* 应用实例信息管理器
*/
private final ApplicationInfoManager applicationInfoManager;
/**
* Eureka-Server 集群节点数组
*/
private volatile List peerEurekaNodes = Collections.emptyList();
/**
* Eureka-Server 服务地址数组
*/
private volatile Set peerEurekaNodeUrls = Collections.emptySet();
/**
* 定时任务服务
*/
private ScheduledExecutorService taskExecutor;
@Inject
public PeerEurekaNodes(
PeerAwareInstanceRegistry registry,
EurekaServerConfig serverConfig,
EurekaClientConfig clientConfig,
ServerCodecs serverCodecs,
ApplicationInfoManager applicationInfoManager) {
this.registry = registry;
this.serverConfig = serverConfig;
this.clientConfig = clientConfig;
this.serverCodecs = serverCodecs;
this.applicationInfoManager = applicationInfoManager;
}
}
peerEurekaNodes,peerEurekaNodeUrls,taskExecutor属性,在构造方法中未设置和初始化,而是在PeerEurekaNodes#start()方法,设置和初始化,下文我们会解析这个方法。Eureka-Server 在初始化时,调用
EurekaBootStrap#getPeerEurekaNodes(…)方法,创建 PeerEurekaNodes ,点击 链接 查看该方法的实现。
2.1 集群节点启动
调用 PeerEurekaNodes#start() 方法,集群节点启动,主要完成两个逻辑:
初始化集群节点信息
初始化固定周期( 默认:10 分钟,可配置 )更新集群节点信息的任务
代码如下:
1: public void start() {
2: // 创建 定时任务服务
3: taskExecutor = Executors.newSingleThreadScheduledExecutor(
4: new ThreadFactory() {
5: @Override
6: public Thread newThread(Runnable r) {
7: Thread thread = new Thread(r, "Eureka-PeerNodesUpdater");
8: thread.setDaemon(true);
9: return thread;
10: }
11: }
12: );
13: try {
14: // 初始化 集群节点信息
15: updatePeerEurekaNodes(resolvePeerUrls());
16: // 初始化 初始化固定周期更新集群节点信息的任务
17: Runnable peersUpdateTask = new Runnable() {
18: @Override
19: public void run() {
20: try {
21: updatePeerEurekaNodes(resolvePeerUrls());
22: } catch (Throwable e) {
23: logger.error("Cannot update the replica Nodes", e);
24: }
25:
26: }
27: };
28: taskExecutor.scheduleWithFixedDelay(
29: peersUpdateTask,
30: serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
31: serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
32: TimeUnit.MILLISECONDS
33: );
34: } catch (Exception e) {
35: throw new IllegalStateException(e);
36: }
37: // 打印 集群节点信息
38: for (PeerEurekaNode node : peerEurekaNodes) {
39: logger.info("Replica node URL: " + node.getServiceUrl());
40: }
41: }
第 15 行 && 第 21 行 :调用
#updatePeerEurekaNodes()方法,更新集群节点信息。
2.2 更新集群节点信息
调用 #resolvePeerUrls() 方法,获得 Eureka-Server 集群服务地址数组,代码如下:
1: protected List resolvePeerUrls() {
2: // 获得 Eureka-Server 集群服务地址数组
3: InstanceInfo myInfo = applicationInfoManager.getInfo();
4: String zone = InstanceInfo.getZone(clientConfig.getAvailabilityZones(clientConfig.getRegion()), myInfo);
5: List replicaUrls = EndpointUtils.getDiscoveryServiceUrls(clientConfig, zone, new EndpointUtils.InstanceInfoBasedUrlRandomizer(myInfo));
6:
7: // 移除自己(避免向自己同步)
8: int idx = 0;
9: while (idx < replicaUrls.size()) {
10: if (isThisMyUrl(replicaUrls.get(idx))) {
11: replicaUrls.remove(idx);
12: } else {
13: idx++;
14: }
15: }
16: return replicaUrls;
17: }
第 2 至 5 行 :获得 Eureka-Server 集群服务地址数组。
EndpointUtils#getDiscoveryServiceUrls(…)方法,逻辑与 《Eureka 源码解析 —— EndPoint 与 解析器》「3.4 ConfigClusterResolver」 基本类似。EndpointUtils 正在逐步,猜测未来这里会替换。第 7 至 15 行 :移除自身节点,避免向自己同步。
调用 #updatePeerEurekaNodes() 方法,更新集群节点信息,主要完成两部分逻辑:
添加新增的集群节点
关闭删除的集群节点
代码如下:
1: protected void updatePeerEurekaNodes(List newPeerUrls) {
2: if (newPeerUrls.isEmpty()) {
3: logger.warn("The replica size seems to be empty. Check the route 53 DNS Registry");
4: return;
5: }
6:
7: // 计算 新增的集群节点地址
8: Set toShutdown = new HashSet<>(peerEurekaNodeUrls);
9: toShutdown.removeAll(newPeerUrls);
10:
11: // 计算 删除的集群节点地址
12: Set toAdd = new HashSet<>(newPeerUrls);
13: toAdd.removeAll(peerEurekaNodeUrls);
14:
15: if (toShutdown.isEmpty() && toAdd.isEmpty()) { // No change
16: return;
17: }
18:
19: // 关闭删除的集群节点
20: // Remove peers no long available
21: List newNodeList = new ArrayList<>(peerEurekaNodes);
22: if (!toShutdown.isEmpty()) {
23: logger.info("Removing no longer available peer nodes {}", toShutdown);
24: int i = 0;
25: while (i < newNodeList.size()) {
26: PeerEurekaNode eurekaNode = newNodeList.get(i);
27: if (toShutdown.contains(eurekaNode.getServiceUrl())) {
28: newNodeList.remove(i);
29: eurekaNode.shutDown(); // 关闭
30: } else {
31: i++;
32: }
33: }
34: }
35:
36: // 添加新增的集群节点
37: // Add new peers
38: if (!toAdd.isEmpty()) {
39: logger.info("Adding new peer nodes {}", toAdd);
40: for (String peerUrl : toAdd) {
41: newNodeList.add(createPeerEurekaNode(peerUrl));
42: }
43: }
44:
45: // 赋值
46: this.peerEurekaNodes = newNodeList;
47: this.peerEurekaNodeUrls = new HashSet<>(newPeerUrls);
48: }
第 7 至 9 行 :计算新增的集群节点地址。
第 11 至 13 行 :计算删除的集群节点地址。
第 19 至 34 行 :关闭删除的集群节点。
第 36 至 43 行 :添加新增的集群节点。调用
#createPeerEurekaNode(peerUrl)方法,创建集群节点,代码如下:1: protected PeerEurekaNode createPeerEurekaNode(String peerEurekaNodeUrl) {
2: HttpReplicationClient replicationClient = JerseyReplicationClient.createReplicationClient(serverConfig, serverCodecs, peerEurekaNodeUrl);
3: String targetHost = hostFromUrl(peerEurekaNodeUrl);
4: if (targetHost == null) {
5: targetHost = "host";
6: }
7: return new PeerEurekaNode(registry, targetHost, peerEurekaNodeUrl, replicationClient, serverConfig);
8: }第 2 行 :创建 Eureka-Server 集群通信客户端,在 《Eureka 源码解析 —— 网络通信》「4.2 JerseyReplicationClient」 有详细解析。
第 7 行 :创建 PeerEurekaNode ,在 「2.3 PeerEurekaNode」 有详细解析。
2.3 集群节点
com.netflix.eureka.cluster.PeerEurekaNode ,单个集群节点。
点击 链接 查看构造方法
第 129 行 :创建 ReplicationTaskProcessor 。在 「4.1.2 同步操作任务处理器」 详细解析
第 131 至 140 行 :创建批量任务分发器,在 《Eureka 源码解析 —— 任务批处理》 有详细解析。
第 142 至 151 行 :创建单任务分发器,用于 Eureka-Server 向亚马逊 AWS 的 ASG (
Autoscaling Group) 同步状态。暂时跳过。
3. 获取初始注册信息
Eureka-Server 启动时,调用 PeerAwareInstanceRegistryImpl#syncUp() 方法,从集群的一个 Eureka-Server 节点获取初始注册信息,代码如下:
1: @Override
2: public int syncUp() {
3: // Copy entire entry from neighboring DS node
4: int count = 0;
5:
6: for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) {
7: // 未读取到注册信息,sleep 等待
8: if (i > 0) {
9: try {
10: Thread.sleep(serverConfig.getRegistrySyncRetryWaitMs());
11: } catch (InterruptedException e) {
12: logger.warn("Interrupted during registry transfer..");
13: break;
14: }
15: }
16:
17: // 获取注册信息
18: Applications apps = eurekaClient.getApplications();
19: for (Application app : apps.getRegisteredApplications()) {
20: for (InstanceInfo instance : app.getInstances()) {
21: try {
22: if (isRegisterable(instance)) { // 判断是否能够注册
23: register(instance, instance.getLeaseInfo().getDurationInSecs(), true); // 注册
24: count++;
25: }
26: } catch (Throwable t) {
27: logger.error("During DS init copy", t);
28: }
29: }
30: }
31: }
32: return count;
33: }
第 7 至 15 行 :未获取到注册信息,
sleep等待再次重试。第 17 至 30 行 :获取注册信息,若获取到,注册到自身节点。
第 22 行 :判断应用实例是否能够注册到自身节点。主要用于亚马逊 AWS 环境下的判断,若非部署在亚马逊里,都返回 `true` 。点击 链接 查看实现。
第 23 行 :调用 `#register()` 方法,注册应用实例到自身节点。在 《Eureka 源码解析 —— 应用实例注册发现(一)之注册》 有详细解析。
若调用 #syncUp() 方法,未获取到应用实例,则 Eureka-Server 会有一段时间( 默认:5 分钟,可配 )不允许被 Eureka-Client 获取注册信息,避免影响 Eureka-Client 。
标记 Eureka-Server 启动时,未获取到应用实例,代码如下:
// PeerAwareInstanceRegistryImpl.java
private boolean peerInstancesTransferEmptyOnStartup = true;
public void openForTraffic(ApplicationInfoManager applicationInfoManager, int count) {
// ... 省略其他代码
if (count > 0) {
this.peerInstancesTransferEmptyOnStartup = false;
}
// ... 省略其他代码
}判断 Eureka-Server 是否允许被 Eureka-Client 获取注册信息,代码如下:
// PeerAwareInstanceRegistryImpl.java
public boolean shouldAllowAccess(boolean remoteRegionRequired) {
if (this.peerInstancesTransferEmptyOnStartup) {
// 设置启动时间
this.startupTime = System.currentTimeMillis();
if (!(System.currentTimeMillis() > this.startupTime + serverConfig.getWaitTimeInMsWhenSyncEmpty())) {
return false;
}
}
// ... 省略其他代码
return true;
}
4. 同步注册信息
Eureka-Server 集群同步注册信息如下图:
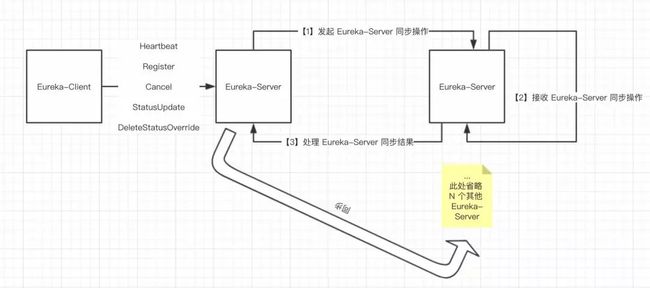
Eureka-Server 接收到 Eureka-Client 的 Register、Heartbeat、Cancel、StatusUpdate、DeleteStatusOverride 操作,固定间隔( 默认值 :500 毫秒,可配 )向 Eureka-Server 集群内其他节点同步( 准实时,非实时 )。
4.1 同步操作类型
com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl.Action ,同步操作类型,代码如下:
public enum Action {
Heartbeat, Register, Cancel, StatusUpdate, DeleteStatusOverride;
// ... 省略监控相关属性
}
Register ,在 《Eureka 源码解析 —— 应用实例注册发现(一)之注册》 有详细解析
Heartbeat ,在 《Eureka 源码解析 —— 应用实例注册发现(二)之续租》 有详细解析
Cancel ,在 《Eureka 源码解析 —— 应用实例注册发现(三)之下线》 有详细解析
StatusUpdate ,在 《Eureka 源码解析 —— 应用实例注册发现(八)之覆盖状态》 有详细解析
DeleteStatusOverride ,在 《Eureka 源码解析 —— 应用实例注册发现(八)之覆盖状态》 有详细解析
4.2 发起 Eureka-Server 同步操作
Eureka-Server 在完成 Eureka-Client 发起的上述操作在自身节点的执行后,向集群内其他 Eureka-Server 发起同步操作。以 Register 操作举例子,代码如下:
// PeerAwareInstanceRegistryImpl.java
public void register(final InstanceInfo info, final boolean isReplication) {
// 租约过期时间
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
// 注册应用实例信息
super.register(info, leaseDuration, isReplication);
// Eureka-Server 复制
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}
最后一行,调用
#replicateToPeers(…)方法,传递对应的同步操作类型,发起同步操作。
#replicateToPeers(...) 方法,代码如下:
1: private void replicateToPeers(Action action, String appName, String id,
2: InstanceInfo info /* optional */,
3: InstanceStatus newStatus /* optional */, boolean isReplication) {
4: Stopwatch tracer = action.getTimer().start();
5: try {
6: if (isReplication) {
7: numberOfReplicationsLastMin.increment();
8: }
9:
10: // Eureka-Server 发起的请求 或者 集群为空
11: // If it is a replication already, do not replicate again as this will create a poison replication
12: if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
13: return;
14: }
15:
16: for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
17: // If the url represents this host, do not replicate to yourself.
18: if (peerEurekaNodes.isThisMyUrl(node.getServiceUrl())) {
19: continue;
20: }
21: replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
22: }
23: } finally {
24: tracer.stop();
25: }
26: }
第 10 至 14 行 :Eureka-Server 在处理上述操作( Action ),无论来自 Eureka-Client 发起请求,还是 Eureka-Server 发起同步,调用的内部方法相同,通过
isReplication=true参数,避免死循环同步。第 16 至 22 行 :循环集群内每个节点,调用
#replicateInstanceActionsToPeers(…)方法,发起同步操作。
#replicateInstanceActionsToPeers(...) 方法,代码如下:
// ... 省略代码,太长了。Cancel :调用
PeerEurekaNode#cancel(…)方法,点击 链接 查看实现。Heartbeat :调用
PeerEurekaNode#heartbeat(…)方法,点击 链接 查看实现。Register :调用
PeerEurekaNode#register(…)方法,点击 链接 查看实现。StatusUpdate :调用
PeerEurekaNode#statusUpdate(…)方法,点击 链接 查看实现。DeleteStatusOverride :调用
PeerEurekaNode#deleteStatusOverride(…)方法,点击 链接 查看实现。上面的每个方法实现,我们都会看到类似这么一段代码 :
batchingDispatcher.process(
taskId("${action}", appName, id), // id
new InstanceReplicationTask(targetHost, Action.Cancel, appName, id) {@Override
public EurekaHttpResponse<Void> execute() {
return replicationClient.doString(...);
}
@Override
public void handleFailure(int statusCode, Object responseEntity) throws Throwable {
// do Something...
}
}, // ReplicationTask 子类
expiryTime)相同应用实例的相同同步操作使用相同任务编号。在 《Eureka 源码解析 —— 任务批处理》「2. 整体流程」 中,我们看到" 接收线程( Runner )合并任务,将相同任务编号的任务合并,只执行一次。 ",因此,相同应用实例的相同同步操作就能被合并,减少操作量。例如,Eureka-Server 同步某个应用实例的 Heartbeat 操作,接收同步的 Eureak-Server 挂了,一方面这个应用的这次操作会重试,另一方面,这个应用实例会发起新的 Heartbeat 操作,通过任务编号合并,接收同步的 Eureka-Server 恢复后,减少收到重复积压的任务。
#task(...)方法,生成同步操作任务编号。代码如下:private static String taskId(String requestType, String appName, String id) {
return requestType + '#' + appName + '/' + id;
}
InstanceReplicationTask ,同步操作任务,在 「4.1.1 同步操作任务」 详细解析。
expiryTime,任务过期时间。
4.1.1 同步操作任务
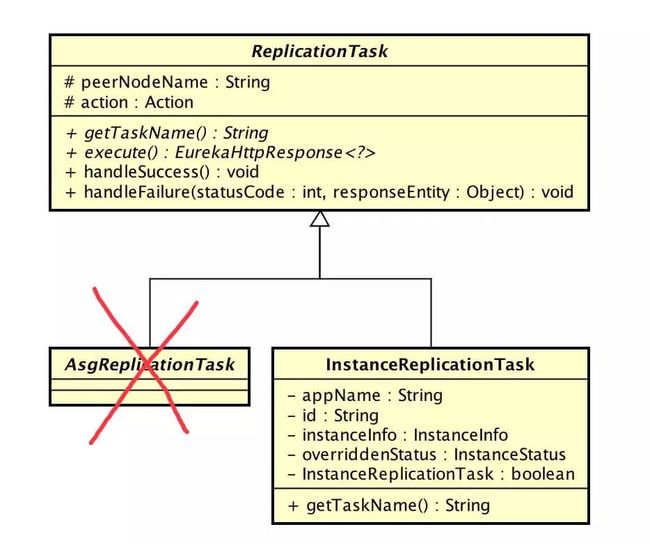
com.netflix.eureka.cluster.ReplicationTask,同步任务抽象类点击 链接 查看 ReplicationTask 代码。
定义了 `#getTaskName()` 抽象方法。
定义了 `#execute()` 抽象方法,执行同步任务。
实现了 `#handleSuccess()` 方法,处理成功执行同步结果。
实现了 `#handleFailure(…)` 方法,处理失败执行同步结果。
com.netflix.eureka.cluster.InstanceReplicationTask,同步应用实例任务抽象类点击 链接 查看 InstanceReplicationTask 代码。
实现了父类 `#getTaskName()` 抽象方法。
com.netflix.eureka.cluster.AsgReplicationTask,亚马逊 AWS 使用,暂时跳过。
从上面 PeerEurekaNode#同步操作(...) 方法,全部实现了 InstanceReplicationTask 类的 #execute() 方法,部分重写了 #handleFailure(...) 方法。
4.1.2 同步操作任务处理器
com.netflix.eureka.cluster.InstanceReplicationTask ,实现 TaskProcessor 接口,同步操作任务处理器。
TaskProcessor ,在 《Eureka 源码解析 —— 任务批处理》「10. 任务执行器【执行任务】」 有详细解析。
点击 链接 查看 InstanceReplicationTask 代码。
ReplicationTaskProcessor#process(task) ,处理单任务,用于 Eureka-Server 向亚马逊 AWS 的 ASG ( Autoscaling Group ) 同步状态,暂时跳过,感兴趣的同学可以点击 链接 查看方法代码。
ReplicationTaskProcessor#process(tasks) ,处理批量任务,用于 Eureka-Server 集群注册信息的同步操作任务,通过调用被同步的 Eureka-Server 的 peerreplication/batch/ 接口,一次性将批量( 多个 )的同步操作任务发起请求,代码如下:
// ... 省略代码,太长了。第 4 行 :创建批量提交同步操作任务的请求对象( ReplicationList ) 。比较易懂,咱就不啰嗦贴代码了。
ReplicationList ,点击 链接 查看类。
ReplicationInstance ,点击 链接 查看类。
`#createReplicationListOf(…)` ,点击 链接 查看方法。
`#createReplicationInstanceOf(…)` ,点击 链接 查看方法。
第 7 行 :调用
JerseyReplicationClient#submitBatchUpdates(…)方法,请求peerreplication/batch/接口,一次性将批量( 多个 )的同步操作任务发起请求。`JerseyReplicationClient#submitBatchUpdates(…)` 方法,点击 链接 查看方法。
ReplicationListResponse ,点击 链接 查看类。
ReplicationInstanceResponse ,点击 链接 查看类。
第 9 至 31 行 :处理批量提交同步操作任务的响应,在 「4.4 处理 Eureka-Server 同步结果」 详细解析。
4.3 接收 Eureka-Server 同步操作
com.netflix.eureka.resources.PeerReplicationResource ,同步操作任务 Resource ( Controller )。
peerreplication/batch/ 接口,映射 PeerReplicationResource#batchReplication(...) 方法,代码如下:
// ... 省略代码,太长了。第 7 至 15 行 :逐个处理单个同步操作任务,并将处理结果( ReplicationInstanceResponse ) 添加到 ReplicationListResponse 。
第 23 至 50 行 :处理单个同步操作任务,返回处理结果( ReplicationInstanceResponse )。
第 24 至 25 行 :创建 ApplicationResource , InstanceResource 。我们看到,实际该方法是把单个同步操作任务提交到其他 Resource ( Controller ) 处理,Eureka-Server 收到 Eureka-Client 请求响应的 Resource ( Controller ) 是相同的逻辑。
Register :点击 链接 查看 `#handleRegister(…)` 方法。
Heartbeat :点击 链接 查看 `#handleHeartbeat(…)` 方法。
Cancel :点击 链接 查看 `#handleCancel(…)` 方法。
StatusUpdate :点击 链接 查看 `#handleStatusUpdate(…)` 方法。
DeleteStatusOverride :点击 链接 查看 `#handleDeleteStatusOverride(…)` 方法。
4.4 处理 Eureka-Server 同步结果