纯干货:大对象导致FullGC频繁的原因及实践思路
今天在检查线上环境的时候,发现了在2分钟内出现了2次FullGC。
虽然对线上功能影响不是很大,但还是想一探究竟。
线上监控得到的信息:
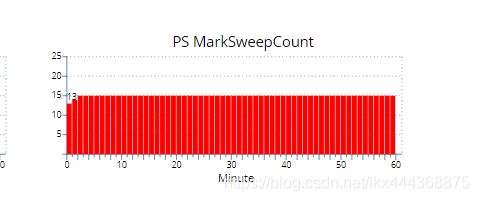
可以看到从短时间内有了2次GC,从13次直接飙到15次。
然后看了下老年代的堆情况:

可以看到这两次分别从620M直接下降到了400M然后又下降到了200M的样子。
脑海中的直觉应该是出现了大对象的感觉,因为老年代的堆是650M。达到620M触发GC,可能是堆空间不足,对象分配不进去,触发了1次GC,清理了200M,这个没什么问题,但是同一时刻又触发了一次GC,又清理了一遍,这个就是有问题了。
但是这个不是什么内存溢出啊啥的,dump不到大对象呀。事故现场已经被清理完了这可咋整喔 。
这个时候我在想,要是Full GC之前能够得到hprof文件就好了。
但其实JVM早就提供了这些参数了。
开启GC参数
# 1. 查看可实时配置的GC参数
java -XX:+PrintFlagsFinal -version | grep manageable
# 2. 查看服务进程编号
jps
# 3. 在full gc前开启dump文件 +表示开启 -表示关闭。 18881 代表应用进程编号
jinfo -flag +HeapDumpBeforeFullGC 18881
jinfo -flag HeapDumpPath=/elab/spring-boot/logs/dump_file 18881
# 查看配置是否生效
jinfo -flag HeapDumpPath 18881
# 查看当前应用的jvm配置
jinfo -flags 18881
通过第一个命令可以不重启应用实时开启的参数:
java -XX:+PrintFlagsFinal -version | grep manageable
intx CMSAbortablePrecleanWaitMillis = 100 {manageable}
intx CMSTriggerInterval = -1 {manageable}
intx CMSWaitDuration = 2000 {manageable}
bool HeapDumpAfterFullGC = false {manageable}
bool HeapDumpBeforeFullGC = false {manageable}
bool HeapDumpOnOutOfMemoryError = false {manageable}
ccstr HeapDumpPath = {manageable}
uintx MaxHeapFreeRatio = 100 {manageable}
uintx MinHeapFreeRatio = 0 {manageable}
bool PrintClassHistogram = false {manageable}
bool PrintClassHistogramAfterFullGC = false {manageable}
bool PrintClassHistogramBeforeFullGC = false {manageable}
bool PrintConcurrentLocks = false {manageable}
bool PrintGC = false {manageable}
bool PrintGCDateStamps = false {manageable}
bool PrintGCDetails = false {manageable}
bool PrintGCID = false {manageable}
bool PrintGCTimeStamps = false {manageable}
这里我们关注其中几个参数:
- PrintClassHistogramBeforeFullGC
- 这个参数是说在full gc前会将内存中的对象以日志的形式输出,但是很多大对象都是些byte啊啥的,你压根不知道是那个对象引用的。
- HeapDumpBeforeFullGC
- 这个参数就是full gc前将hprof文件保存下来
- HeapDumpPath
- dump下来的hprof文件存放位置
通过上述操作,在应用下一次full gc的时候便会保存hprof文件文件
分析hprof文件
通过上述命令保存下来的文件大概有1.3G,有点大。
下载下来会比较麻烦。
这里通过MAT的linux的工具直接在服务器上进行分析。
MAT分析工具
从这个网站上下载Linux (x86_64/GTK+)的
如何使用?
cd mat
./ParseHeapDump.sh /elab/spring-boot/dump.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
# 预计五分钟之后出结果,查看结果就到hprof所在的位置
/elab/spring-boot/dump.hprof : 位置
-rw-r--r-- 1 root root 8.3M Mar 20 10:15 java_pid18881.a2s.index
-rw-r--r-- 1 root root 13M Mar 20 10:15 java_pid18881.domIn.index
-rw-r--r-- 1 root root 37M Mar 20 10:15 java_pid18881.domOut.index
-rw------- 1 root root 1.3G Mar 20 10:01 java_pid18881.hprof
-rw-r--r-- 1 root root 295K Mar 20 10:16 java_pid18881.i2sv2.index
-rw-r--r-- 1 root root 33M Mar 20 10:15 java_pid18881.idx.index
-rw-r--r-- 1 root root 50M Mar 20 10:15 java_pid18881.inbound.index
-rw-r--r-- 1 root root 7.2M Mar 20 10:15 java_pid18881.index
-rw-r--r-- 1 root root 100K Mar 20 10:15 java_pid18881_Leak_Suspects.zip
-rw-r--r-- 1 root root 12M Mar 20 10:15 java_pid18881.o2c.index
-rw-r--r-- 1 root root 33M Mar 20 10:15 java_pid18881.o2hprof.index
-rw-r--r-- 1 root root 28M Mar 20 10:15 java_pid18881.o2ret.index
-rw-r--r-- 1 root root 49M Mar 20 10:15 java_pid18881.outbound.index
-rw-r--r-- 1 root root 82K Mar 20 10:15 java_pid18881_System_Overview.zip
-rw-r--r-- 1 root root 356K Mar 20 10:15 java_pid18881.threads
-rw-r--r-- 1 root root 256K Mar 20 10:16 java_pid18881_Top_Components.zip
一共会有这么些东西,你只要关注3个*.zip包就行了。
把这3个下载到本地,里面是html文件,打开就是结果。
主要关注 : java_pid18881_Leak_Suspects.zip 这个文件
打开结果:
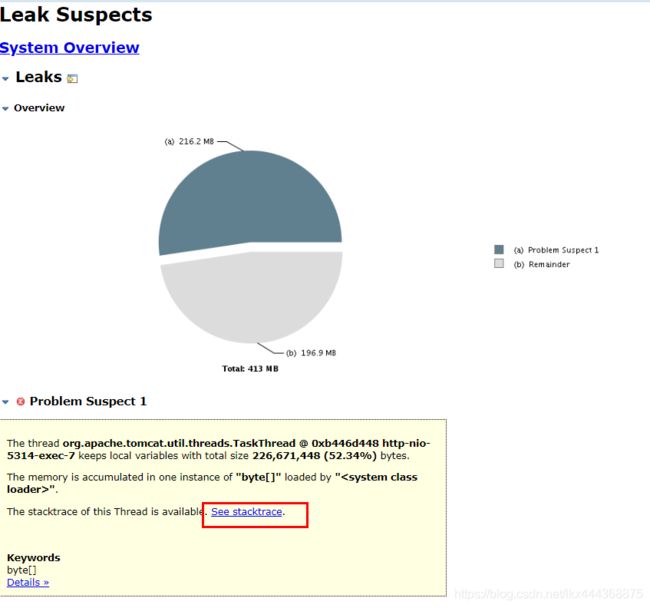
我们看到有一个216M的大对象出现了。
然后点击链接进去看是那个线程造成的.
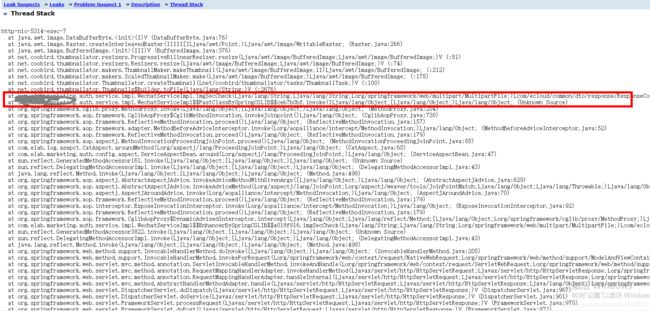
我们这里就找到了具体业务触发的方法了。
我这里就不贴具体的方法了,最根本的原因是一个图片压缩的功能造成的
Thumbnails.of(file.getInputStream()).scale(0.1f).toFile(outputImg);
如果客户端上传的图片太大,会通过这个方法进行压缩。由于对象本身会很大的话,很容易触发Full GC。
然后我根据这个时间点去监控系统中查询该URL的方法日志的时候,也发现了一个超过9秒的请求,根据方法执行的时间链路基本上也就确定了就是上述代码造成的。
好了,具体过程就是这样。
总结一下 :
- 通过开启JVM的参数,在full GC前保留一份hprof文件。
- 通过MAT的linux工具直接在服务器上分析,避免文件过大下载下来太慢。
- 然后查看结果页来找到具体的大对象
如果你还有什么更好的排查思路以及工具欢迎交流。