nginx与php的WEB常见问题一般的排查方法有:
检查error_log,检查access_log,使用strace查看系统调用,tcpdump分析网络状况。而程序本身的问题,可能需要用到gdb调试。

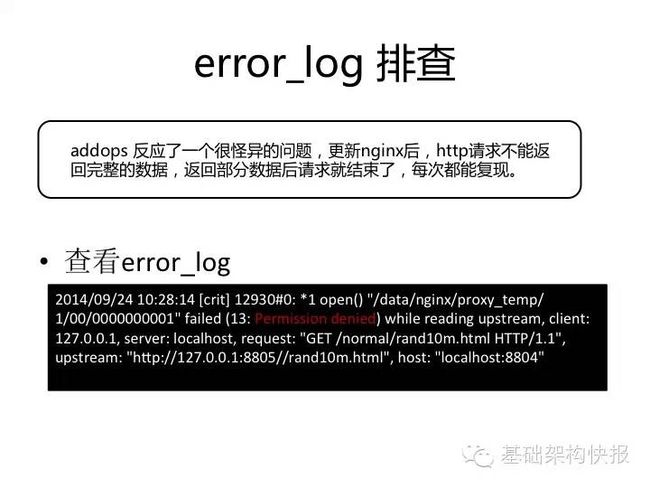
error_log提供了有关异常的丰富信息,大多数情况下可以发现问题的蛛丝马迹。比如:connect,write,read timeout等网络超时错误,比如Permission denied, File not found等系统调用错误,比如400,499,500等对应的HTTP状态码错误。

举例来讲,更新nginx后,http请求不能返回完整数据,返回部分数据后请求就结束了,每次都能复现。这时候查看error_log,看到有Permission denied错误,即查实为nginx的临时写目录没有权限所造成。
access_log则提供了所有客户端访问流水的日志,而且可以灵活定义日志的格式与内容,包括日志翻转的设定。比如查看到后端响应的时间,后端返回状态码。
对access_log进行统计分析,可以很好地展示与监控web服务的状态。包括200请求次数的变化,流量大小,后端响应时间等等。一般地讲:
可以定义access_log每5分钟翻转1次;
统计HTTP状态码的比例,可以知道nginx服务健康状况;
统计响应时间,判断超时请求。(根据经验,如果响应时间分布集中在某个数字,并且标准差很小,则可能是达到超时)
统计QPS,对比负载是否均衡。

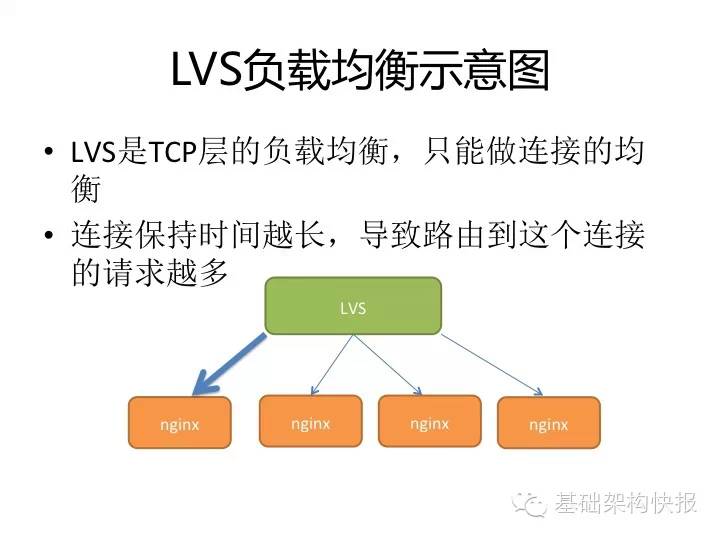
举例:在一次nginx应用更新的灰度过程中,我们选取一台nginx上线,观察接下来的半小时内,nginx占用内存不断增大,直到耗尽系统资源。排查error_log中并没有错误信息;监控发现新上线的nginx流量大增;分析access_log发现新上线的nginx的QPS是原机器的6~8倍。证实是Keepalived导致流量负载不均衡。LVS作为负载均衡时,后端的nignx配置的keepalive_timeout时间有差异导致。

LVS的负载均衡是TCP层的,只能做连接的均衡,如果Keepalive时间设置的超长,会导致路由到这个连接的请求越多。
access_log排查举例2:nginx做反向代理,有时发现某些接口较慢,通常都在3s左右。
配置nginx的access log记录upstream_response_time,分析发现响应大约3s多。而分析后端的access_log,处理时间都在毫秒级别。这说明问题是由于nginx跟后端connect较慢导致。

使用strace命令工具可跟踪系统调用并打印出丰富的信息,如系统调用发生的时间,调用耗时,传送的参数,调用返回结果等等。
常用参数有:
-tt 打印系统调用发生的时间
-T 打印系统调用耗时
-e
-s

strace举例:某个PHP进程hang住,其pid为26879,那么可以使用strace -p 26879来观察。
示例显示,futex表示很可能发生死锁,strace打印出其参数值。

某次排查PHP问题时,发现有时PHP处理请求过慢,就可用strace来追查验证系统调用耗时。结果strace -T就发现是flock调用过慢。

而另外一次,朋友线上出了故障,系统负载特别高,load到200多,CPU使用率也到90%的,特别高,关键是使用strace追查并没有发现什么问题。这里要说明一下,strace只能追踪系统调用,普通函数是无法追踪的。CPU很高,说明程序一直在跑,但strace没有异常,说明是用户状代码在消耗CPU。问题必定出现在自己程序逻辑上。
最终证实是系统上线更换配置文件,导致程序逻辑出错。

tcpdump是linux本身得供的一款强大的网络抓包工具。对于两台设备之间传输的数据是否正常,为何响应慢等网络问题,都可以使用tcpdump来抓包排查。
windows下面有一款具有同样功能的工具软件--wireshark,也很好用。

还记得刚才示例中提到的慢连接吧,Nginx的access_log显示请求响应时间为3s多,而后端是毫秒计,这种慢就可以使用tcpdump来抓包查看了。

可以看到后端响应ack花了3s.这种慢连接,我们线上会经常碰到。通常nginx做反向代量连接后端时、php程序在访问后端资源时、以及php用curl请求其他接口时,经常出现慢连接的情况。这些慢连接产生的根本原因在于:
--服务端listen时,设置的backlog太小,导致连接队列很小;
--连接队列满时,对于新的连接请求,服务端会直接丢弃SYN包;
--SYN包初始重传时间为3s;

再举一下综合案例:PHP升级后,开始运行正常,但几天后,系统负载突然上升,达到200-400左右,CPU使用不高,内存使用不高,netstat发现大量的PHP进程处于CLOSE_WAIT状态。
排查:error_log与access_log都没有问题;
nginx与PHP不在同一台机器,暂时无法查看其error_log;
CPU、内存都不高,为何负载这么高?
CLOSE_WAIT是怎么造成的?

我们先从CLOSE_WAIT入手,TCP关闭连接过程中,被动关闭的一方,在接收到对方的FIN后,发送自己的FIN前,这个状态就是CLOSE_WAIT。
系统调用close,关闭连接,发送FIN。

从CLOSE_WAIT的状态看,PHP应该是没有调用close函数,程序可能因为某种原因堵塞,而无法调用close。
启用strace追踪PHP进程到底堵塞在哪里。

从strace追踪结果来看,PHP进程没有堵塞,但write函数调用失败,Broken pipe说明连接已经关闭,调用close了。

继续strace分析,连接为什么关闭,是后端PHP处理太慢导致nginx超时么?从strace看到,PHP从accept到close,总共耗时1ms,nginx不可能超时。

我们启动tcpdump抓包(windows下使用wireshark查看)

发现3个异常:
--3次握手nginx发送的SYN,PHP响应是ACK,而不是SYN+ACK
--Nginx发送FIN关闭连接后,PHP没有发送FIN
--第二个连接的SYN,PHP同样只返回ACK,但ACK序列号却是确认上一个连接的。

结合strace与tcpdump来看,accept调用比接收到SYN晚了2分钟。

这里可以看到:SYN三次握手完成后,socket放到了连接队列里,accept从连接队列获取socket,如果队列过大,等到accept消费到这个socket,可能已经超时关闭连接。队列中关闭的连接处于CLOSE_WAIT状态。若PHP一个关闭的连接,就会出现Broken Pipe报错现象。
这其实就是backlog设置过大引起。

总结一下,web问题排障很复杂,找到正确的方向很重要。学会看log与系统状态,学会使用统计数据(常用的一些awk,grep命令),熟悉一些常用的工具。
问题一定是有原因的,要找到root cause(真正的根本原因)

最后,常常总结分享,共同进步。